





Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти.
Часть 4: Поддержка устройств NUMA
Оригинал: "Memory part 4: NUMA support"Автор: Ulrich Drepper
Дата публикации: October 17, 2007
Перевод: Н.Ромоданов
Дата перевода: апрель 2012 г.
Прим.ред.: Напомним, что NUMA (Non-Uniform Memory Access - "неравномерный доступ к памяти" или Non-Uniform Memory Architecture - "Архитектура с неравномерной памятью") - схема реализации компьютерной памяти, используемая в мультипроцессорных системах, когда время доступа к памяти определяется её расположением по отношению к процессору.
| Назад | Оглавление | Вперед |
В разделе 2 мы видели, что на некоторых машинах, стоимость доступа к конкретным областям физической памяти различается в зависимости от того, откуда происходит доступ. Для этого типа устройств требуется особое внимание со стороны операционной системы и приложений. Мы начнем с некоторых особенностей устройств NUMA, а затем рассмотрим некоторые средства поддержки, предлагаемые в ядре Linux для устройств NUMA.
5.1 Аппаратные устройства NUMA
Использование архитектуры с неравномерным доступом к памяти становятся все более и более распространенным явлением. В простейшем случае архитектуры NUMA процессор может иметь локальную память (смотрите рис.2.3), доступ к которой дешевле, чем доступ к этой локальной памяти из других процессоров. Различие в стоимости для данного типа системы NUMA невысокая, то есть показатель NUMA является низким.
Архитектура NUMA используется также, и в особенности, в больших машинах. Мы описали проблемы получения доступа к одной и той же памяти из различных процессоров. С точки зрения аппаратных средств, все процессоры будут использовать один и тот же северный мост (без учета на данный момент узлов NUMA для машин AMD Opteron, у которых есть свои собственные проблемы). Это делает северный мост одним из самых узких мест, поскольку весь трафик с памятью проходит через него. В больших машинах можно, конечно, вместо северного моста использовать специальные аппаратные средства, но, если используемые чипы памяти не имеют несколько портов, то есть они не могут использоваться из нескольких шин, то узкие места все еще остаются. Многопортовая память является сложной и дорогой для производства и эксплуатации и, поэтому, почти не используется.
Следующим шагом по сложности является использование модели AMD, в которой механизм взаимодействия (Hypertransport, в случае AMD, технология, лицензированная фирмой Digital) предоставляет доступ процессорам, которые не имеют непосредственного доступа к памяти. Для того, чтобы диаметр (т.е., максимальное расстояние между любыми двумя узлами) не увеличивался произвольным образом, размер структур, которые могут формироваться таким образом, должен быть ограничен.
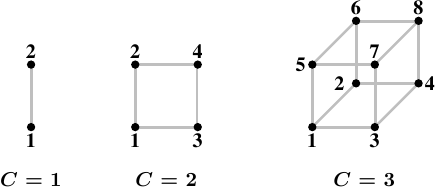
Рис 5.1: Гиперкубы
Наилучшей топологией для узлов является гиперкуб, в котором количество узлов ограничено 2C, где С - количество интерфейсов взаимных соединений, которое есть в каждом узле. Гиперкубы для всех систем с числом процессоров, равным 2n, имеют маленький диаметр. На рис.5.1 показаны первые три гиперкуба. Каждый гиперкуб имеет диаметр С, что является абсолютным минимумом. В первом поколении процессоров Opteron фирмы AMD было по три гипертранспортных соединения на процессор. По крайней мере, к одному из соединений должен быть подключен южный мост, а это означает, что в настоящее время эффективно и без всяких ухищрений можно реализовать гиперкуб с C = 2. Объявлено, что в следующем поколении соединений будет четыре, благодаря чему удастся реализовать гиперкуб с C = 3.
Однако, это не означает, что нельзя поддерживать работу большего количества процессоров. Есть компании, которые разработали сборки, позволяющие использовать наборы с большим количеством процессоров (например, Horus фирмы Newisys). Но эти сборки имеют большой показатель NUMA и при определенном количестве процессоров они становятся неэффективными.
Следующий шаг состоит в подключении групп процессоров и реализация совместно используемой памяти для каждого процессора из группы. Для всех таких систем требуются специализированные аппаратные средства и такие системы не являются изделиями широкого спроса. Такие конструкции имеют несколько уровней сложности. Системой, которая все еще достаточно похожа на машину широкого спроса, является машина IBM X445 и аналогичные машины. Их можно купить как обычные машины, имеющие размер 4U, 8 каналов и процессорами x86 и x86-64. Две такие машины (а с некоторого момента и четыре такие машины) можно объединить для работы в виде одной машины с совместно используемой памятью. Используемые соединения имеют большой показатель NUMA, что должно учитываться как операционной системой, так и приложением.
На другом конце спектра находятся машины, такие как Altix фирмы SGI, которые специально предназначены для подключения друг к другу. Механизм соединения NUMA, реализованный SGI, очень быстрый и имеет более низкую латентность; оба этих свойства очень важны при высокопроизводительных вычислениях (high-performance computing - HPC), особенно в случаях, когда используются интерфейсы Message Passing Interfaces (MPI). Недостатком является, конечно, то, что такая сложность и специализация стоят очень дорого. С их помощью можно получить достаточно низкий коэффициент NUMA, но с тем числом процессоров, которые могут быть в этих машинах (а это - несколько тысяч), а также из-за ограниченных возможностей соединений, показатель NUMA фактически является динамическим и, в зависимости от нагрузки, может достичь неприемлемых уровней.
Наиболее часто используются решения, в которых с помощью высокоскоростных соединений создается кластер из широко распространенных машин. Но они не являются системами NUMA, у них нет общего адресного пространства и, следовательно, они не попадают в какую-нибудь из категорий, которые здесь обсуждаются.
| Назад | Оглавление | Вперед |