





Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти.
Часть 2: Кэш-память процессора
Оригинал: "Memory part 2: CPU caches"Автор: Ulrich Drepper
Дата публикации: October 1, 2007
Перевод: Н.Ромоданов
Дата перевода: апрель 2012 г.
| Назад | Оглавление | Вперед |
3.5 Коэффициенты промахов кэш-памяти
Мы уже видели, что когда при доступе к памяти возникают промахи в кэше, накладные расходы резко увеличиваются. Иногда этого избежать не удается, и важно понять, какими будут фактические затраты, и что можно сделать, чтобы смягчить проблему.
3.5.1 Пропускная способность кэш-памяти и основной памяти
Чтобы получить более полное представление о возможностях процессоров, мы измерим пропускную способность в оптимальных условиях. Этот показатель особенно интересен, поскольку различные версии процессоров отличаются друг от друга. По этой причине в данном разделе будут приведены данные, полученные на различных машинах. Для измерения производительности взята программа, в которой используются инструкции SSE процессоров с архитектурой x86 и x86-64, с помощью которых за одно действие выполняется загрузка из памяти или сохранение в памяти 16 байт данных. Рабочий набор увеличивается с 1kB до 512MB точно также, как это было в других наших тестах, и измеряется, сколько байтов данных можно загрузить или сохранить за один цикл.
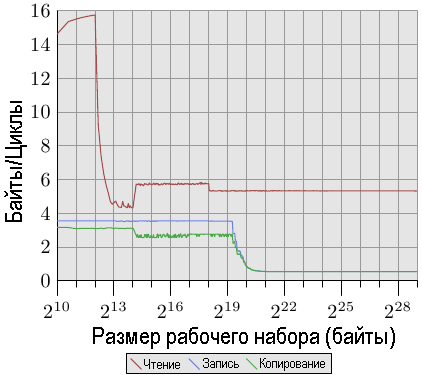
Рис.3.24: Пропускная способность процессора Pentium 4
На рис.3.24 показана производительность 64-разрядного процессора Intel NetBurst. Для рабочих наборов с примерами, которые помещаются в кэш-память L1d, процессор может прочитать все 16 байтов за один цикл, т. е. за один цикл выполняется одна инструкция загрузки (инструкция movaps перемещает за один раз 16 байтов данных). В тесте ничего не делается с прочитанными данными, мы тестируем только сами инструкции чтения данных. Как только кэш-памяти L1d станет не хватать, производительность резко падает до менее чем 6 байтов за цикл. Порог в 218 байтов связан с исчерпанием кэш-памяти DTLB, что означает дополнительную работу для каждой новой страницы. Поскольку чтение выполняется последовательно, предсказание доступа в предварительной загрузке работает прекрасно, а шина FSB может для всех размеров рабочего набора передавать содержимое памяти в потоке со скоростью 5,3 байта за цикл. Однако предварительная загрузка не распространяется на кэш-память L1d. Это, конечно, значения, которые никогда не будут достижимы в реальной программе. Считайте их практически предельными значениями.
Более удивительной по сравнению с производительностью при чтении является производительность при записи и копировании. Производительность при записи даже для рабочих наборов с небольшими размерами, никогда не поднимается выше 4 байтов за цикл. Это указывает на то, что в таких процессорах Netburst, Intel решила использовать в кэш-памяти L1d режим с прямой записью (Write-Through), при котором скорость, очевидно, ограничена скорость работы кэш-памяти L2. Это также означает, что производительность теста копирования, в котором данные копируются из одной области памяти в другую непересекающуюся области памяти, не намного хуже. Следовательно, требуемые операций чтения выполняются намного быстрее и могут частично перекрываться с операциями записи. Самым интересными деталями измерения записи и копирования является низкая производительность в случае, как только становится мало кэш-памяти L2. Производительность падает до 0,5 байта за цикл! Это значит, что операции записи в десять раз медленнее, чем операции чтения. Это означает, что оптимизация этих операций еще более важна для выполнения программы.
На рис.3.25 мы видим результаты для того же процессора, но с двумя работающими потоками по одному на каждом из двух гиперпотоков процессора.
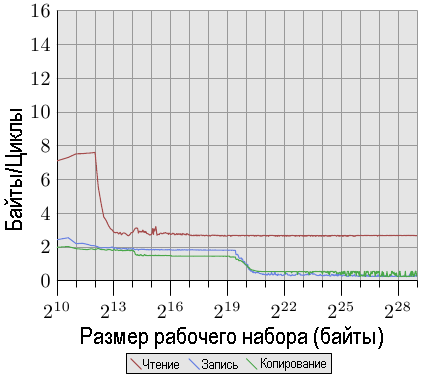
Рис.3.25: Пропускная способность процессора Pentium 4 с двумя гиперпотоками
Для того, чтобы показать различия, график изображен в том же самом масштабе, что и предыдущий, а кривые немного варьируются просто из-за проблем измерения двух параллельных потоков. Результаты такие, как и ожидалось. Поскольку гиперпотоки совместно используют одни и те же ресурсы кроме регистров, каждый из них может использовать только половину кэш-памяти и половину пропускной способности процессора. Это значит, что, хотя каждый поток может долго находиться в режиме ожидания и предоставлять другому потоку возможность выполняться, это не окажет никакого влияния, поскольку другой поток может также ожидать доступ к памяти. Здесь действительно показан худший вариант использования гиперпотоков.
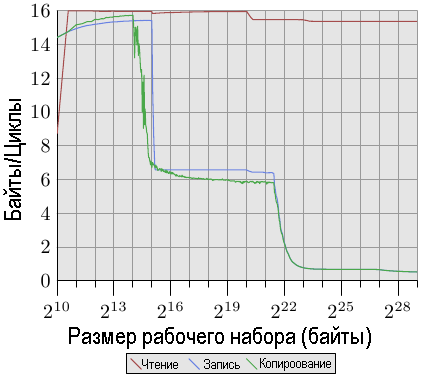
Рис.3.26: Пропускная способность процессора Core 2
По сравнению с рис.3.24 и 3.25 результаты на рис. 3.26 и 3.27 для процессора Intel Core 2 выглядят совсем иначе. Это двухядерный процессор с совместно используемой кэш-памятью L2, которая в четыре раза больше, чем кэш-память L2 на машине P4. Однако, этим объясняется только более позднее падение производительности при записи и копировании.
Различий гораздо больше. Производительность чтения во всем диапазоне рабочего набора колеблется вокруг оптимального значения 16 байтов за цикл. Падение производительности чтения после значения в 220 байтов опять же объясняется слишком большим размером рабочего набора для DTLB. Получение таких больших значений означает, что процессор не только может выполнять предварительную загрузку данных и осуществлять их своевременную передавать. Это также означает, что предварительная загрузка данных также осуществляется для кэш-памяти L1d.
Производительность записи и копирования также резко отличается. Процессор не использует политику прямой записи (Write-Through); записанные данные хранятся в кэш-памяти L1d и удаляются из нее только когда это необходимо. Это позволяет писать со скоростью, близкой к оптимальной в 16 байт за цикл. Как только оказывается мало кэш-памяти L1d, производительность резко падает. Как и в процессорах Netburst, скорость записи здесь значительно ниже. Благодаря высокой производительности при чтении, различия здесь еще больше. На самом деле, когда становится мало даже кэш-памяти L2, различие в скорости возрастает до 20 раз! Это не означает, что процессоры Core 2 работают плохо. Наоборот, их производительность всегда лучше, чем производительность ядер Netburst.
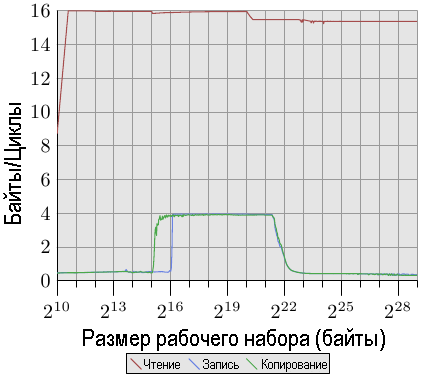
Рис.3.27: Пропускная способность процессора Core 2 с двумя потоками
На рис.3.27 тестовая программа запускает два потока, по одному для каждого из двух ядер процессора Core 2. Хотя оба потока получают доступ к одной и той же памяти, им не требуется синхронизация. Результаты по производительности чтения не отличаются от однопоточного случая. Видно еще несколько флуктуаций, которые ожидаемы в случае любого многопоточного теста.
Интерес представляет производительность записи и копирования для рабочих наборов с размерами, которые будут вписываться в кэш-память L1d. Как видно на рисунке, производительность такая же, как если бы данные считывались из основной памяти. Оба потока соревнуются за доступ к одному и тому же месту памяти и для кэш-строк должны отправляться сообщения RFO. Проблема состоит в том, что, хотя оба ядра используют общую кэш-память, эти запросы не обрабатываются со скоростью работы кэш-памяти L2. Как только становится недостаточно кэш-памяти L1d, все модифицированные записи удаляются из кэш-памяти L1d и помещаются в общую кэш-память L2. В этот момент производительность значительно возрастает, поскольку теперь промахи L1d разрешаются кэш-памятью L2, а сообщения RFO нужны только тогда, когда данные еще не были сброшены. Вот почему мы видим снижение скорости на 50% для рабочих наборов этих размеров. Асимптотическое поведение такое, как и ожидалось: поскольку оба ядра совместно используют одну и ту же шину FSB, каждое ядро получает половину пропускной способности шины FSB, что означает, что для больших рабочих наборов производительность каждого потока составляет примерно половину от однопоточного случая.
Поскольку имеются значительные различия между версиями процессоров одного производителя, безусловно, стоит также посмотреть на производительность процессоров других производителей. На рис.3.28 показана производительность процессора Opteron серии 10 фирмы AMD. Этот процессор имеет 64kB кэш-памяти L1d, 512kB кэш-памяти L2 и 2MB кэш-памяти L3. Кэш-память L3 является общей для всех ядер процессора. Результаты тестирования производительности можно увидеть на рис.3.28.
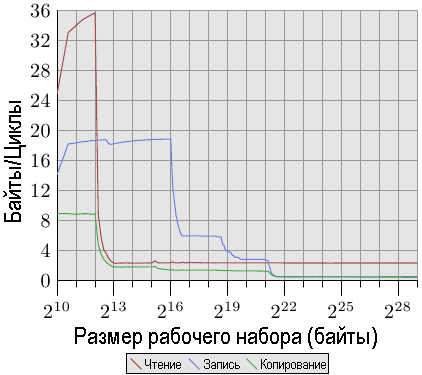
Рис.3.28: Пропускная способность процессора Opteron серии 10 фирмы AMD
Первое, что сразу видно, это то, что если достаточно кэш-памяти L1d, процессор может обрабатывать две инструкции за один цикл. Скорость чтения превышает 32 байта за цикл, а скорость записи даже более высокая - 18,7 байтов за цикл. Кривая чтения быстро выравнивается и становится довольно низкой - 2,3 байта за цикл. Процессор для этого теста не выполняет предварительную загрузку каких-либо данных, по крайней мере, не выполняет ее эффективно.
С другой стороны, кривая записи зависит от размеров кэш-памяти различных уровней. Пиковая производительность достигается до полного заполнения кэш-памяти L1d, уменьшаясь до 6 байтов на цикл для кэш-памяти L2, до 2,8 байта за цикл для кэш-памяти L3 и, наконец, до 0,5 байта за цикл в том случае, если все данные не помещаются даже в кэш-память L3. Производительность для кэш-памяти L1d превышает производительность (более старого) процессора Core 2, доступ к кэш-памяти L2 осуществляется одинаково быстро (в сравнении с Core 2, имеющим больший кэш), а доступ к кэш-памяти L3 и основной памяти происходит медленнее.
Производительность копирования не может быть лучше, чем производительность либо чтения, либо записи. Вот почему мы видим, что первоначально доминирует производительность чтения, а затем — производительность записи.
На рис. 3.29 показана производительность процессора Opteron для многопоточного случая.
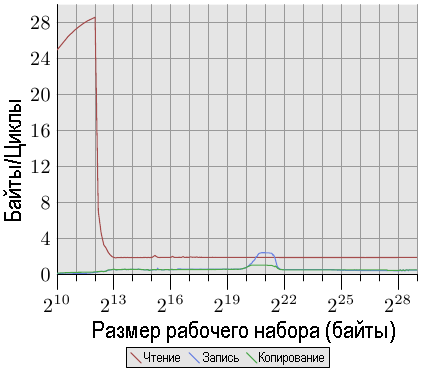
Рис.3.29: Пропускная способность процессора AMD серии 10 с двумя потоками
Производительность чтения осталась, в основном, неизменной. Кэш-память L1d и L2 для каждого потока работают как раньше, а кэш-память L3 в этом случае не выполняет предварительную загрузку достаточно хорошо. Два потока не должны в данном случае чрезмерно загружать кэш-память L3. Большой проблемой в этом тесте является производительности записи. Все данные, которые совместно используются потоками, должны пройти через кэш-память L3. Оказывается, что такое совместное использование весьма неэффективно, поскольку, даже если размер кэш-памяти L3 достаточен для хранения всего рабочего набора, затраты будут существенно выше, чем доступ к L3. Если сравнить этот график с рис.3.27, то мы увидим, что для соответствующего диапазона размеров рабочего набора два потока процессора Core 2 работают на скорости разделяемой кэш-памяти L2. Такой уровень производительности достигается для процессора Opteron только для очень небольшого диапазона размеров рабочего набора и даже здесь она соответствует только скорости кэш-памяти L3, которая работает медленнее, чем кэш-память L2 процессора Core 2.
| Назад | Оглавление | Вперед |