





Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти.
Часть 2: Кэш-память процессора
Оригинал: "Memory part 2: CPU caches"Автор: Ulrich Drepper
Дата публикации: October 1, 2007
Перевод: Н.Ромоданов
Дата перевода: апрель 2012 г.
| Назад | Оглавление | Вперед |
3.3.4 Поддержка многопроцессорности
В предыдущем разделе мы уже указывали на проблему, которая у нас возникает в случае, когда в игру вступают несколько процессоров. Даже в многоядерных процессорах есть проблемы для тех уровней кэш-памяти, к которым отсутствует совместный доступ (по крайней мере, для L1d).
Совершенно нецелесообразно предоставлять прямой доступ одного процессора к кэш-памяти другого процессора. Прежде всего, такой доступ недостаточно быстрый. Более практичной является альтернатива, когда в случае, когда это необходимо, содержимое кэш-памяти передается в другой процессор. Обратите внимание, что это относится и к кэш-памяти, к которой у процессора нет совместного доступа.
Вопрос теперь в том, когда должна происходить передача этой кэш-строки? На этот вопрос очень легко ответить: когда некоторому процессору нужно прочитать или записать кэш-строку, которая была изменена в кэш-памяти другого процессора. Но как процессор определит, изменена ли кэш-строка в кэш-памяти другого процессора? Если исходить только из того, что кэш-строка была загружена другим процессором, то такое решение будет (в лучшем случае) неоптимальным. Обычно, в большинстве случаев обращения к памяти доступ осуществляется для чтения и в результате этого кэш-строки не изменяются. Операции процессора над кэш-строками происходаят часто (конечно, почему бы и нет, если у нас есть такая возможность?), что означает, что широковещательная передача информации об измененных кэш-строках после каждого доступа на запись была бы непрактичной.
В течение ряда лет был разработан протокол согласования кэш-памяти MESI (Modified, Exclusive, Shared, Invalid). Протокол назван по названию четырех состояний, в которых может находиться кэш-строка при использовании протокола MESI:
- Modified - Модифицированный: Локальный процессор изменил кэш-строку. Также подразумевается, что в кэш-памяти находится только одна копия кэш-строки.
- Exclusive - Эксклюзивный: Кэш-строка не изменена, но известно, что она не загружена ни в какую-либо кэш-память другого процессора.
- Shared- Разделяемый: Кэш-строка не изменена, но она может быть в кэш-памяти какого-нибудь другого процессора.
- Invalid- Недействительный: Кэш-строка недействительна, т. е. не используется.
Этот протокол разрабатывался на протяжении многих лет на основе более простых вариантов, которые были менее сложными, но и менее эффективными. Используя эти четыре состояния можно эффективно реализовать кэш-память с обратной записью, обеспечивая при этом другим процессорам одновременный доступ к этим данным только для чтения.
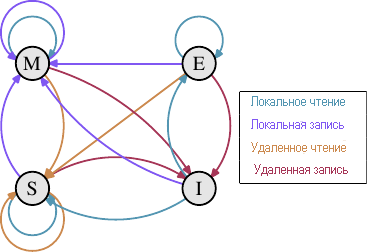
Рис.3.18: Переходы между состояниями протокола MESI
Изменение состояний происходит без особых затрат за счет прослушивания или перехвата сигналов, что выполняется другими процессорами. Некоторые операции, которые выполняет процессор, анонсируются на внешних контактах и, следовательно, за пределами процессора становится известно о том, как происходит обработка кэш-памяти процессора. По запросу на адресной шине виден адрес кэш-строки. В следующем описании состояний и переходов между ними (смотрите рис.3.18), мы укажем, когда будет использована шина.
Первоначально все кэш-строки пусты, а, следовательно, и недействительны (состояние Invalid). Если данные будут загружены для записи, то кэш-строка станет модифицированной (состояние Modified). Если данные загружаются для чтения, то новое состояние зависит от того, будет ли та же кэш-строка также загружена другим процессором. Если будет, то новое состояние будет разделяемым (состояние Shared), в противном случае - эксклюзивным (состояние Exclusive).
Если кэш-строка модифицирована (состояние Modified) и чтение или запись выполняется локальным процессором, то инструкция может использовать содержимое текущее содержимое кэш-строки и ее состояние не изменяется. Если второй процессор хочет читать из кэш-строки, то первый процессор должен отправить содержимое кэш-строки во второй процессор, а затем изменить состояние на разделяемое (состояние Shared). Данные, переданные во второй процессор, также принимаются и обрабатываются контроллером памяти, который сохраняет данные в памяти. Если этого не произойдет, то кэш-строка не может быть помечена как Shared. Если второй процессор хочет сделать запись в кэш-строку, то первый процессор посылает содержимое кэш-строки и локально помечает кэш-строку как недействительную (состояние Invalid). Это печально известная операция "Request For Ownership" (RFO). Выполнение этой операции в кэш-памяти последнего уровня, например, переход I → M, является сравнительно дорогим. Для кэш-памяти с прямой записью мы также должны добавить время, необходимое для записи нового содержимого кэш-строки на следующий более высокий уровень или в оперативную память, что еще увеличит затраты.
Если кэш-строка находится в разделяемом состоянии (состояние Shared) и локальный процессор выполняет чтение, то нет необходимости изменять состояние и чтение можно выполнить из кэш-строки. Если в кэш-строке происходит локальная запись, то кэш-строка также может использоваться, но ее состояние изменится на модифицированное (состояние Modified). При этом также потребуется, чтобы все другие возможные копии кэш-строки в других процессорах были помечены как недействительные (состояние Invalid). Таким образом, операция записи должна с помощью сообщения RFO оповестить другие процессоры об этом. Если кэш-строка запрашивается вторым процессором для чтения, то ничего не происходит. Текущие данных находятся в основной памяти, а локальное состояние уже помечено как разделяемое (состояние Shared). В случае, если второй процессор захочет сделать запись в кэш-строку (RFO), то кэш-строка будет просто помечена как недействительная (Invalid). Операции с шиной не нужны.
Эксклюзивное состояние (Exclusive), в основном, идентично разделяемому состоянию (Shared) с одним важным отличием: сообщения о локальных операциях записи не должны передаваться по шине. Известно, что локальная копия кэш-памяти только одна. Это является огромным преимуществом, поэтому процессор будет пытаться сохранить столько кэш-строк в эксклюзивном (Exclusive) состянии, а не в разделяемом (Shared), сколько это будет возможно. Для случая в состоянии Shared нужно возвращать данные обратно, если они на данный момент недоступны. В случае эксклюзивного состояния (Exclusive) все можно оставить так, как оно есть, без возникновения каких-либо проблем с функционированием. Единственное, что будет страдать - это производительность, поскольку переход E → M выполняется намного быстрее, чем переход S → M.
Из этого описания переходов между состояниями должно быть ясно, где возникают затраты, характерные для многопроцессорных операций. Да, заполнение кэш-памяти по-прежнему дорого, но теперь мы также должны обратить внимание на сообщения RFO. Всякий раз, когда должно быть отправлено такое сообщение, дела будут идти очень медленно.
Есть две ситуации, когда необходимы сообщения RFO:
- Поток мигрирует с одного процессора на другой, и все кэш-строки должны быть сразу перенесены на новый процессор.
- Кэш-строка действительно необходима в двух разных процессорах. {В меньшей степени то же самое верно для двух ядер на одном процессоре. Затраты только немного меньше. Вероятно, что сообщение RFO будет отправляться много раз.}
В многопоточных или многопроцессорных программах всегда есть необходимость в синхронизации; эта синхронизация осуществляется с использованием памяти. Таким образом, есть некоторые действительно нужные сообщения RFO. Они по-прежнему должны быть максимально редкими настолько, насколько это окажется возможным. Хотя есть и другие источники сообщений RFO. В разделе 6 мы разъясним эти сценарии. Сообщения протокола однородности кэш-памяти должны распространяться между процессорами системы. Переходы между состояниями MESI не будут происходить до тех пор, пока не станет ясно, что все процессоры в системе имели возможность отреагировать на сообщение. Это значит, что скорость протокола однородности определяется максимально возможным временем ответа. {Именно поэтому мы видим сегодня, например, системы AMD Opteron с тремя сокетами. Если учесть, что в каждом процессоре используются только три гиперссылки и еще одна, необходимая для подключения южного моста, процессор может выполнить ровно один далекий переход.} На шине возможны коллизии, в системах NUMA могут быть большие задержки и, конечно, большой объем трафика может замедлить ход событий. Все это достаточно веские причины для того, чтобы постараться избежать ненужного трафика.
Есть еще одна проблема, связанная с использованием более одного процессора. Эффект проявляется на вполне конкретных машинах, но, в принципе, эта проблема существует всегда: шина FSB является общим ресурсом. В большинстве машин все процессоры подключены к контроллеру памяти с помощью одной шины (смотрите рис.2.1). Если один процессор может исчерпать пропускную возможность шины (как это обычно и бывает), то два или четыре процессора, совместно использующих одну и ту же шину, будут для каждого процессора еще больше ограничивать пропускную способность шины.
Даже если каждый процессор имеет свою шину к контроллеру памяти так, как это показано на рис.2.2, есть еще шина к модулям памяти. Обычно это одна шина, но даже для расширенной модели, показанной на рис.2.2, при одновременном доступе к одному и тому же модулю памяти будет возникать ограничение пропускной способности.
То же самое справедливо и для модели AMD, где каждый процессор может иметь локальную память. Да, все процессоры могут одновременно и быстро получить доступ к локальной памяти. Но многопоточные и многозадачные программы должны для синхронизации получать, по крайней мере, время от времени, доступ к одним и теми же областям памяти.
Распараллеливание серьезно ограничивается окончательной пропускной способностью, которая обусловлена тем, как реализуется требуемая синхронизация. Нужно тщательно разрабатывать программы для того, чтобы минимизировать доступ разных процессоров и ядер к одним и тем же местам памяти. В следующих измерениях будут показаны этот и другие эффекты кэш-памяти, возникающие в многопоточном коде.
Измерение многопоточностиДля того, чтобы понять всю важность проблем, возникающих при использовании одних и тех же самых кэш-строк в разных процессорах, мы здесь рассмотрим еще несколько графиков производительности той же самой программы, которую мы использовали раньше. Однако, на этот раз будет одновременно запускаться более одного потока. Измеряться будет наилучшее время выполнения любого из потоков. Это означает, что время, в течение которого будут выполнены все потоки, будет больше. Используемая машина имеет четыре процессора; в тестах используется до четырех потоков. Все процессоры для доступа к контроллеру памяти используют одну и ту же шину, для доступа к модулям памяти имеется только одна шина.
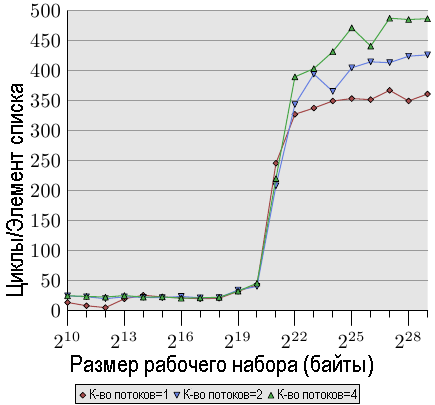
Рис.3.19: Последовательный доступ на чтение, многопоточный вариант
На рис.3.19 показана производительность последовательного доступа только на чтение записей размером в 128 байтов (NPAD = 15 для 64-разрядной машины). Как можно было ожидать, кривая для одного потока аналогична кривой на рис.3.11. При измерениях на различных машинах фактические цифры отличаются.
Важная часть на этом рисунке это, конечно, поведение графика при работе с несколькими потоками. Обратите внимание, что память не изменяется и попытки синхронизации потоков при проходе по связному списку отсутствуют. Хотя сообщения RFO не являются необходимыми и ко всем кэш-строкам можно обращаться одновременно, мы видим, что в случае, когда используется два потока, снижение производительности для самого быстрого потока доходит до 18%, а при использовании четырех потоков — до 34%. Поскольку кэш-строки не должны пересылаться между процессорами, то это снижение производительности обусловлено исключительно одним из следующих или обоими узкими местами: общей шиной, используемой для доступа от процессора к контроллеру памяти, и общей шиной, используемой для при доступе от контроллера памяти к модулям памяти. Как только размер рабочего набора становится больше размера кэш-памяти L3 для этой машины, во всех трех потоках будет происходить предварительная загрузка новых элементов списка. Даже при двух потоках пропускной способности недостаточно для того, что масштаб изменений был линейным (то есть, что отсутствовали накладные расходы, связанные работой нескольких потоков).
Когда мы модифицируем содержимое памяти, то все выглядит еще хуже. На рис.3.20 показаны результаты теста, осуществляющего последовательное приращение значений.
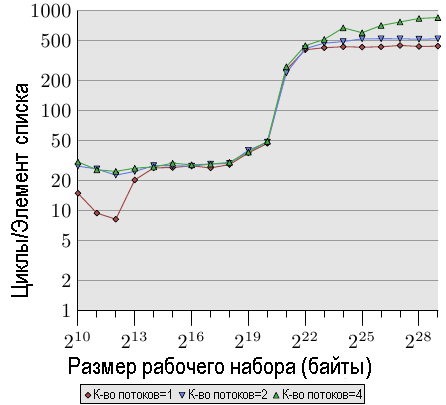
Рис.3.20: Последовательное приращение, многопоточный вариант
На этом графике для оси Y используется логарифмическая шкала. Поэтому обратите внимание, что, на самом деле, различия существенные. Мы при выполнении двух потоков все еще теряем 18% производительности, а теперь, как ни странно, при выполнении четырех потоков теряем 93% производительности. Это значит, что когда используются четыре потока, трафик предварительной загрузки вместе механизмом обратной записи значительно быстрее насыщают шину.
Мы при показе результатов изменений для кэш-памяти L1d используем логарифмическую шкалу. Все, что в этом случае можно увидеть, это то, что если работает более одного потока, кэш-память L1d, как правило, неэффективна. Время доступа для одного превышает 20 циклов только в случае, когда кэш-памяти L1d недостаточно для хранения рабочего набора. Когда работает несколько потоков, время доступа увеличивается до таких значений сразу даже с самым маленьким размером рабочего набора.
Здесь не показан один из аспектов этой проблемы. Его трудно измерить при использовании этой конкретной тестовой программы. Даже если тест изменяет содержимое памяти и мы, таким образом, должны ожидать появление сообщений RFO, мы в случае, когда используется более одного потока, мы не видим более высоких затрат для диапазона кэш-памяти L2. Программа должна использовать больше памяти, и все потоки должны в параллель получать доступ к одной и той же памяти. Этого трудно достичь без большого количества синхронизаций, что должно оказать доминирующее влияние на время выполнения.
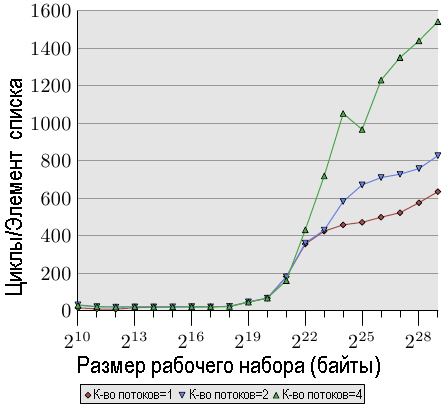
Рис.3.21: Тест Addnextlast с произвольным порядком доступа, многопоточный вариант
Наконец, на рис.3.21 у нас приведены значения для теста Addnextlast с произвольным доступом к памяти. Этот рисунок представлен, в основном, для того, чтобы показать необычайно большие значения. В экстремальном случае обработка одного элемента списка достигает 1500 циклов. Под вопросом становится еще большего количества потоков. Мы можем в следующей таблице подвести итог, связанный с эффективность использования нескольких потоков.
Таблица 3.3: Эффективность в многопоточном случае
| Количество потоков | Последовательное чтение | Последовательное добавление | Добавление в произвольном порядке |
|---|---|---|---|
| 2 | 1.69 | 1.69 | 1.54 |
| 4 | 2.98 | 2.07 | 1.65 |
В таблице показана эффективность многопоточной работы для наибольшего размера рабочего набора из трех значений, изображенных на рис.3.21. Показаны наилучшие значения по скорости тестовой программы для наибольшего размера рабочего набора при использовании случая двух или четырех потоков. Для случая двух потоков теоретический предел ускорения составляет 2, а для четырех потоков — 4. Для случая двух потоков значения выглядят не так уж и плохо. Но для четырех потоков значения последнего теста показывают, что результат почти не стоит того, чтобы число потоков увеличивать больше двух. Дополнительный выигрыш незначительный. Нам это будет проще увидеть, если мы немного по-другому представим данные с рис.3.21.
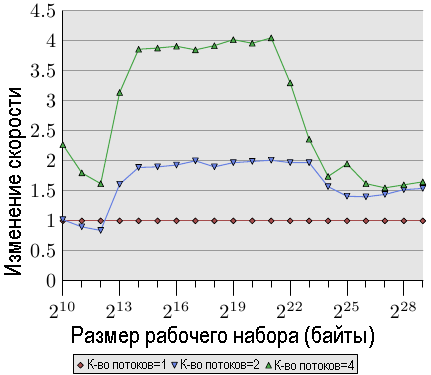
Рис.3.22: Увеличение скорости за счет распараллеливания
Кривые на рис.3.22 показывают коэффициент увеличения скорости, т.е. относительную производительность по сравнению с кодом, исполняемым в одном потоке. Нам следует игнорировать небольшие изменения, т. к. измерения недостаточно точные. Для кэш-памяти L2 и L3, мы видим, что мы действительно получаем почти линейное увеличение скорости. Мы почти достигаем коэффициентов 2 и 4, соответственно. Но как только размер кэш-памяти L3 становится недостаточным для хранения рабочего набора, значения сразу портятся. Они одинаково плохи как для двух, так и для четырех потоков (смотрите четвертый столбец в таблице 3.3). Это одна из причин, почему почти невозможно найти материнскую плату с разъемами для более чем для четырех процессоров, на которой все процессоры используют один и тот же контроллер памяти. Машины с большим количеством процессоров должны быть построены по-другому (смотрите раздел 5).
Эти значения не универсальны. В некоторых случаях даже для рабочих наборов, которые помещаются по размеру в кэш-память последнего уровня, увеличение скорости не будет линейным. Фактически это типичная ситуация, поскольку потоки, как правило, не отделены друг от друга так, как это имеет место в данной тестовой программе. С другой стороны, можно работать с большими рабочими наборами и по-прежнему получать выигрыш при наличии более, чем двух потоков. Однако, для этого требуется подумать. Мы поговорим о некоторых подходах в разделе 6.
Специальный случай: гиперпотокиГиперпотоки (Hyper-Threads), иногда называемые симметричными мультипотоками (Symmetric Multi-Threading или SMT), реализуются внутри процессора и представляют собой особый случай, поскольку в действительности отдельные потоки не могу работать одновременно. Все они совместно пользуются почти всеми ресурсами процессора за исключением набора регистров. Отдельные ядра и процессоры продолжают работать параллельно, но потоки, обрабатываемые каждым ядром, ограничены этой особенностью. В теории в каждом ядре может быть много потоков, но до сих пор процессоры Intel имеют для каждого ядра не более, чем два потока. Процессор самостоятельно реализует временное мультиплексирование потоков. Онако, в этом, само по себе, смысла мало. Реальное преимущество в том, что процессор может переключаться на другой гиперпоток в тех случаях, когда выполнение гиперпотока, обрабатываемого в настоящий момент, затягивается. В большинстве случаев это задержка, связанная с обращением к памяти.
Если два потока работают на одном ядре, позволяющем использовать гиперпотоки, то программа будет более эффективной, чем однопоточный код, только в случае, если совокупное время исполнения обоих потоков будет меньше, чем время исполнения однопоточного кода. Это может быть за счет перекрытия времени ожидания, затрачиваемого на доступ к различным областям памяти, что обычно выполняется последовательно. Простой расчет показывает минимальные требования к степени попаданий кэш-памяти, которые позволят повысить скорость работы программы.
Время выполнения программы можно аппроксимировать следующим образом с помощью простой модели с одним уровнем кэш-памяти (смотрите [htimpact]):
Texe = N[(1-Fmem)Tproc + Fmem(GhitTcache + (1-Ghit)Tmiss)]
где:
| N | = | Количество инструкций. |
| Fmem | = | Инструкции, обращающиеся в память. |
| Ghit | = | Часть нагрузки, связанная с попаданиями в кэш-памяти. |
| Tproc | = | Количество циклов на одну инструкцию. |
| Tcache | = | Количество циклов при попадании в кэш-памяти. |
| Tmiss | = | Количество циклов при промахе в кэш-памяти. |
| Texe | = | Время выполнения программы |
Чтобы имело смысл использовать два потока, время выполнения каждого из этих двух потоков должно быть не более половины от времени выполнения однопоточного кода. Единственная оптимизационная переменная для каждого потока - это количество попаданий в кэш-память. Если мы решим уравнение минимума коэффициента попаданий кэш-памяти с требованием не уменьшать скорость выполнения потока на 50% или более, мы получим график, показанный на рис.3.23.
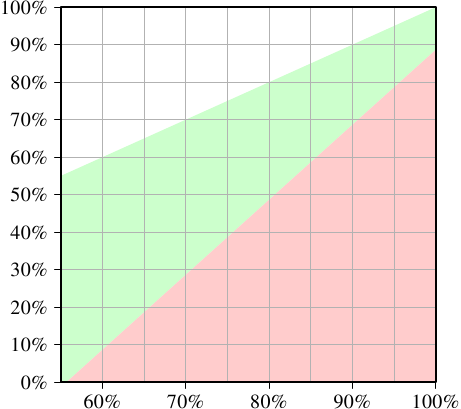
Рис.3.23: Минимум коэффициента попаданий кэш-памяти при увеличении скорости
По оси X указываются значения показателя попаданий кэш памяти Ghit для однопоточного кода. По оси Y отображается требуемый показатель попаданий кэш-памяти для многопоточного кода. Это значение никогда не может быть больше, чем показатель попаданий для однопоточного кода, поскольку, в противном случае, в однопоточном коде можно будет также использовать этот улучшенный код. Если показатель попаданий для однопоточного кода ниже 55%, то программа может во всех случаях получить преимущество от использования потоков. Из-за промахов кэш-памяти у процессора достаточно времени простоя с тем, чтобы он мог запустить второй гиперпоток.
Целевой является зеленая область. Если спад для потока составляет менее 50%, а рабочая нагрузка для каждого потока уменьшается вдвое, то совокупное время выполнения может быть меньше, чем время выполнения однопоточного кода. Для моделируемой здесь системы (были использования значения для процессора P4 с гиперпотоками) программа с коэффициентом попаданий 60% для однопоточного кода потребует по крайней мере коэффициента попаданий 10% для программы с двумя потоками. Это, как правило, выполнимо. Но если однопоточный код имеет коэффициент попадания 95%, то для многопоточного кода необходим коэффициент попаданий не менее 80%. Это сложнее. Особенно, и это проблема гиперпотоков, из-за того, что эффективный размер кэша (здесь это L1d , на практике это также L2 и т. д.), доступный для каждого гиперпотока, сокращается вдвое. Оба гиперпотока используют для загрузки своих данных одну и ту же кэш-память. Если рабочий набор для двух потоков неперекрывается, то исходный кожффициент попадания в кэш-память в 95% также может быть сокращен в два раза и, следовательно, будет значительно меньше, чем требуемые 80%.
Следовательно, гиперпотоки полезны только в ограниченном диапазоне случаев. Показатель попаданий кэш-памяти для однопоточного кода должен быть достаточно низким с тем, чтобы учитывая приведенные выше уравнения и уменьшенный размер кэш-памяти, новый показатель попаданий все еще отвечал поставленной цели. Тогда и только тогда вообще будет какой-либо смысл использовать гиперпотоки. Будет ли результат лучше, на практике зависит от того, способен ли процессор перекрыть время ожидания, затраченное в одном потоке, временем исполнения другого потока. К новому общему времени исполнения следует добавить накладные расходы на распараллеливание кода и этими дополнительными расходами не всегда можно пренебречь.
В разделе 6.3.4 мы рассмотрим методики, в которых потоки тесно взаимодействуют друг с другом и непосредственное взаимодействие через общий кэш является, на самом деле, преимуществом. Эту методику можно применять во многих ситуациях, если только программисты готовы потратить время и энергию, чтобы изменить свой код.
Должно быть ясно то, что если в двух гиперпотоках выполняется абсолютно различный код (например, два потока рассматриваются операционной системой как отдельные процессоры для выполнения отдельных процессов), размер кэша действительно сокращается вдвое, что означает значительное увеличение промахов кэш-памяти. Такая практика планирования операционной системы сомнительна в случае, если кэш-память недостаточно большая. Если рабочая нагрузка машины не состоит из процессов, которые в силу своих конструктивных особенностей, могут действительно извлечь выгоду от использования гиперпотоков, может оказаться лучше просто отключить гиперпотоки в BIOS компьютера. {Еще одна причина держать гиперпотоки включенными — это отладка. Режим SMT удивительно удобен при поиске некоторых проблем, возникающих в параллельном коде}.
| Назад | Оглавление | Вперед |