





Библиотека сайта rus-linux.net
Что каждый программист должен знать о памяти.
Часть 2: Кэш-память процессора
Оригинал: "Memory part 2: CPU caches"Автор: Ulrich Drepper
Дата публикации: October 1, 2007
Перевод: Н.Ромоданов
Дата перевода: апрель 2012 г.
| Назад | Оглавление | Вперед |
3.3.2 Измерение влияния использования кэш-памяти
Все рисунки строятся на основе измерений при помощи программы, в которой можно промоделировать рабочие наборы произвольного размера, доступ на чтение и запись, а также доступ в последовательном или произвольном порядке. Некоторые результаты мы уже видели на рис.3.4. Программа создает массив, соответствующий по размеру рабочего набора и состоящий из элементов следующего типа:
struct l {
struct l *n;
long int pad[NPAD];
};
Все элементы соединяются в циклический список с помощью элемента n в последовательном или случайном порядке. При переходе от одного элемента к следующему всегда используется указатель, даже если элементы расположены последовательно. Элемент pad представляет собой полезную нагрузку и его можно делать сколь угодно большим. В некоторых тестах данные изменяются, в других программа выполняет только операции чтения.
При выполнении измерений мы говорим о размерах рабочего набора. Рабочий набор состоит из массива элементов структуры struct l. В рабочем наборе размером в 2N байтов находятся
2N/sizeof(struct l)
элементов. Очевидно, что значение sizeof(struct l) зависит от величины NPAD. Для 32-разрядных систем, NPAD=7 означает, что размер каждого элемента массива равен 32 байта, а для 64-разрядных систем - 64 байта.
Простейший случай представляет собой простой обход всех записей в списке. Элементы списка располагаются последовательно, между ними нет промежутков. Порядок обхода значения не имеет, процессор может выполнять обход одинаково хорошо в обоих направлениях. Мы измеряем здесь, а также во всех следующих тестах, время, в течение которого выполняется обработка одного элемента списка. Единицей времени является процессорный цикл. Результат приведен на рис.3.10. Если не указано что-либо иное, все измерения выполняется на машине с процессором Pentium 4 в 64-разрядном режиме, что означает, что структура structure l с NPAD=0 имеет размер в восемь байт.
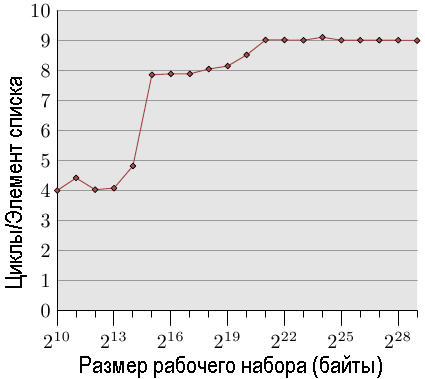
Рис.3.10: Доступ с последовательным чтением, NPAD=0
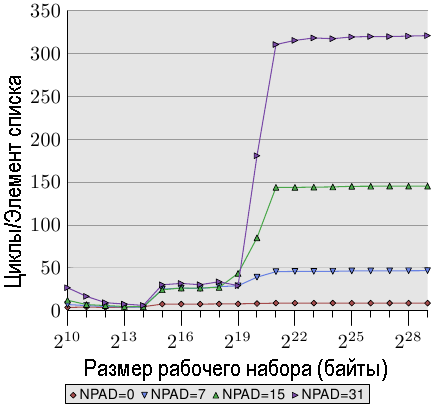
Рис.3.11: Последовательное чтение для нескольких значений размеров
Первые два измерения загрязнены шумом. Измеряемая нагрузка слишком мала, чтобы из нее отфильтровать влияние остальной части системы. Мы можем смело предположить, что все значения равны уровню в 4 цикла. С учетом этого, мы видим следующие три различных фрагмента:
- Когда размер рабочего набора увеличивается до 214 байтов.
- Размер от 215 байтов и до 220 байтов
- Размер от 221 байтов и выше.
Эти различия можно легко объяснить: в процессоре есть 16kB кэш-памяти L1d и 1MB кэш-памяти L2. При переходе от одного уровня к другому острых углов не видно, поскольку кэш-память используется другими частями системы, а также кэш-память не предназначена для хранения исключительно данных программы. В частности, кэш-память L2 является универсальной кэш-памятью и она также используется для инструкций (Замечание: Intel использует инклюзивную кэш-память).
Что, возможно, не вполне ожидаемо, это действительно затрачиваемое время для рабочих наборов различного размера. Значения времени при попадании данных в кэш-памятьL1d оказывается ожидаемым: время загрузки после попадания в кэш-память L1d составляет приблизительно 4 цикла для процессора P4. Но как насчет доступа к кэш-памяти L2? Как только кэш-памяти L1d окажется недостаточно для хранения данных, можно ожидать, что в кэш-памяти L2 для одного элемента потребуется 14 циклов или более. Но результаты показывают, что требуется лишь около 9 циклов. Это несоответствие можно объяснить только использованием в процессорах улучшенной логики. Предполагая, что будут использоваться последовательно идущие области памяти, процессор осуществляет предварительную загрузку (prefetches) следующей кэш-строки. Это означает, что когда на самом деле будет использоваться следующая строка, она окажется уже наполовину загруженной. Поэтому задержка, которая требуется на ожидание загрузки следующей кэш-строки, гораздо меньше, чем время доступа к кэш-памяти L2.
Эффект предварительной загрузки будет еще большее в случае, если размер рабочего набора будет превышать размер кэш-памяти L2. Ранее мы говорили, что на доступ к основной памяти затрачивается более 200 циклов. Однако при использовании эффективной предварительной загрузки время доступа в процессоре можно уменьшить до 9 циклов. Как видно из разницы между 200 и 9, это работает прекрасно.
Мы можем, по крайней мере, косвенно, пронаблюдать за тем, как процессор выполняет предварительную загрузку. На рис.3.11 показаны значения времени для различных размеров одного и того же рабочего набора, но на этот раз мы рассмотрим графики для различных размеров структуры structure l. Они отличаются тем, что элементов в списке меньше, но размеры элементов - больше. Влияние различия размеров элементов выражается в том, что расстояние между элементами n (они, по-прежнему, идут последовательно) растет. Для четырех вариантов графика значения равны 0, 56, 120 и 248 байтов, соответственно.
В нижней части мы видим строку из предыдущего графика, но на этот раз он выглядит более или менее прямой линией. Значения времени для других случаев выглядят гораздо хуже. На этом графике мы также видим три других уровня, а также большое количество ошибок в тестах с небольшими размерами рабочего набора (игнорируем их снова). До тех пор, пока используется только кэш-память L1d , графики, более или менее, везде совпадают. Предварительная загрузка не нужна и поэтому при каждом доступе в кэш-память L1d имеет место попадание для элементов всех размеров.
Что касается попаданий кэш-памяти L2, то, как мы видим, три новых графика, в целом, совпадают друг с другом, но находятся на более высоком уровне (около 28). Это уровень времени доступа к кэш-памяти L2. Это значит, что, как правило, отсутствует предварительная загрузка из кэш-памяти L2 в кэш-память L1d. Даже для NPAD = 7 нам при каждой итерации требуется новая кэш-строка; для NPAD = 0 цикл должен повториться восемь раз прежде, чем потребуется следующая кэш-строка. Нельзя на каждом цикле загружать новую строку с помощью технологии предварительной загрузки. Поэтому в каждой итерации мы видим срыв загрузки из кэш-памяти L2.
Еще более интересная ситуация в случае, когда раз размер рабочего набора превышает объем кэш-памяти L2. Теперь все четыре кэш-строки сильно отличаются друг от друга. Очевидно, что при изменении производительности разница размеров элементов играет важную роль. Процессор должен определить размер необходимого фрагмента данных и в случае, когда NPAD = 15 и 31, не выполнять ненужный поиск кэш-строк, поскольку размер элемента меньше, чем окно предварительной загрузки (см. раздел 6.3.1). Если изменение размера элемента оказывает на предварительную загрузку сильное влияние, то это значит, что на затраты, связанные с предварительной загрузкой, влияют аппаратные ограничения: предварительная загрузка не может нарушать границы страниц. При каждом увеличении размера мы снижаем аппаратную эффективность на 50%. Если бы в аппаратной реализации предварительной загрузки было бы разрешено нарушать границы страниц, а следующая страница не была бы резидентной или допустимой, то для поиска страницы пришлось бы привлечь OS. Это означает, что программа может получить отказ в доступе к странице, доступ к которой не был инициализирован самой программой. Это совершенно неприемлемо, поскольку процессор не знает, существует ли некоторая страница и присутствует ли она в оперативной памяти. В последнем случае операционная система должна прервать процесс. В любом случае, если учесть, что для NPAD = 7 и более нам для каждого элемента списка нужна одна строка кэша, аппаратная предварительная загрузка много сделать не сможет. Просто не хватит времени для загрузки данных из памяти, поскольку все, что процессор успеет сделать, это прочитать одно слово, а затем загрузить следующий элемент.
Еще одна существенная причина снижения производительности связана с промахами в кэш-памяти TLB. Это кэш-память, в которой, как это было подробно описано в разделе 4, запоминается результат перевода виртуальных адресов в физические адреса. Кэш-память TLB достаточно мала, поскольку она должна быть очень быстрой. Если доступно больше страниц, чем для них в кэш-памяти TLB может поместиться записей, используемых для перевода из виртуального в физический адрес, то перевод адресов должен повторяться. Это очень дорогостоящая операция. Если элементы большего размера, то затраты на поиск в кэш-памяти TLB компенсируются обработкой меньшего количества элементов. Это означает, что общее количество записей в кэш-памяти TLB, которые должны быть обработаны для одного элемента списка, будет большим.
Чтобы пронаблюдать за эффектами кэш-памяти TLB, мы можем запустить другой тест. При первом измерении мы, как и обычно, расположим элементы последовательно. Мы используем NPAD = 7 для элементов, которые полностью занимают одну кэш-строку. При втором измерении мы помещаем каждый элемент списка на отдельную страницу. Оставшееся место на каждой странице мы не используем и не учитываем его при подсчете общего размера рабочего набора. {Да, это немного непоследовательно, поскольку в других тестах мы учитываем неиспользуемую часть структуры в размере элемента, и мы могли бы определить NPAD так, чтобы каждый элемент занимал всю страницу. В подобном случае размеры рабочих наборов были бы совсем другими. Хотя это и не рассматривается в этом тесте, но в любом случае из-за неэффективности предварительной загрузки это мало что изменит}. Из-за этого в случае первого измерении при каждой итерации по списку потребуется новая кэш-строка, а для каждых 64 элементов — новая страница. В случае второго измерения для каждой итерации потребуется загрузить новую кэш-строку, которая будет находиться на новой странице.
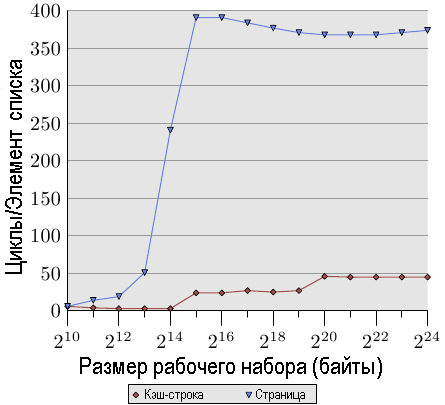
Рис.3.12: Влияние кэш-памяти TLB при последовательном чтении элементов
Результат можно увидеть на рис.3.12. Измерения проводились на той же машине, что и для рис.3.11. В связи с ограничениями имеющейся основной памяти, размер рабочего набора пришлось ограничить 224 байтами, для которых требуется 1 Гб памяти, чтобы разместить объекты на отдельных страницах. Нижняя, красная кривая в точности соответствует кривой NPAD = 7 на рис.3.11. Мы видим различные фрагменты, указывающие размеры кэш-памяти L1d и L2. Вторая кривая отличается радикальным образом. Важным отличием является резкое увеличение значения, начинающиеся, когда размер рабочего набора достигает 213 байтов. Это происходит при переполнении кэш-памяти TLB. При условии, что размер элемента равен 64 байта, мы можем вычислить, что в кэш-памяти TLB находятся 64 записи. Ошибки отказа в доступе к страницам отсутствуют, т. к. программа блокирует память для того, чтобы предотвратить использование подкачки.
Видно, что количество циклов, необходимое для вычисления физического адреса и сохранения его в кэш-памяти TLB, очень большое. На графике на рисунке 3.12 показан экстремальный случай, но должно быть понятно, что важным фактором снижения производительности при больших значениях NPAD является уменьшение эффективности кэш-памяти TLB. Поскольку физический адрес должен вычисляться раньше, чем можно будет для кэш-памяти L2 или основной памяти прочитать кэш-строку, затраты, необходимые на это вычисление, добавляются к затратам времени доступа к памяти. Этим частично объясняется, почему общие затраты на один элемент списка для NPAD = 31 выше, чем теоретическое время доступа к памяти.
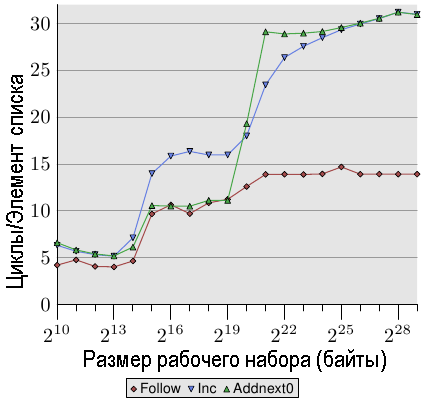
Рис.3.13: Последовательное чтение и запись, NPAD=1
Мы можем увидеть несколько более подробную информацию, касающуюся
реализации предварительной загрузки, если посмотрим на результаты
теста, в котором элементы списка изменяются. На рис.3.13 показаны три графика. Размер элементов во всех случаях равен 16 байтам. Первый график соответствует уже знакомому нам проходу по списку, который рассматривается как базовый. Для второго графика, помеченного как "Inc", перед переходом к следующему элементу в текущем элементе просто происходит увеличение компонента pad[0]. Для третьего графика, помеченного как "Addnext0", берется компонента pad[0] следующего элемента в списке, которая добавляется к компоненту pad[0] члена текущего элемента списка.
Естественно предположить, что тест "Addnext0" работает медленнее, поскольку ему предстоит выполнить больше работы. Перед тем, как переходить к следующему элементу списка, требуется загрузить его значение его элемента. Вот почему оказывается удивительно, что, на самом деле, этот тест для некоторых размеров рабочих наборов работает быстрее, чем тест "Inc". Объясняется это тем, что доступ к следующему элементу списка происходит, главным образом, с помощью принудительно выполняемой предварительной загрузки. Каждый раз, когда программа переходит к следующему элементу списка, мы можем быть уверены, что этот элемент будет находиться в кэш-памяти L1d. В результате мы видим, что до тех пор, пока рабочий набор по размеру помещается в кэш-память L2, на тест "Addnext0" затрачивается столько же времени, сколько и на тест "Follow".
Однако тест "Addnext0", когда он выходит за границы кэш-памяти L2, не поспевает за тестом "Inc". Для него требуется загружать из основной памяти больше данных. Вот почему при размере рабочего набора в 221 байтов кривая теста "Addnext0" достигает уровня в 28 циклов. Уровень в 28 циклов вдвое больше, чем уровень в 14 циклов, которого достигает кривая теста "Follow". Это тоже легко объяснить. Когда память изменяется, то, в отличие от двух других тестов, в этом тесте для того, чтобы освободить место в кэш-памяти L2 под новую кэш-строку, нельзя просто выбросить данные. Вместо этого данные должны быть записаны в память. Это значит, что доступная пропускная способность шины FSB уменьшается вдвое и, удваивается время, требуемое для передачи данных из основной памяти в кэш-память L2.
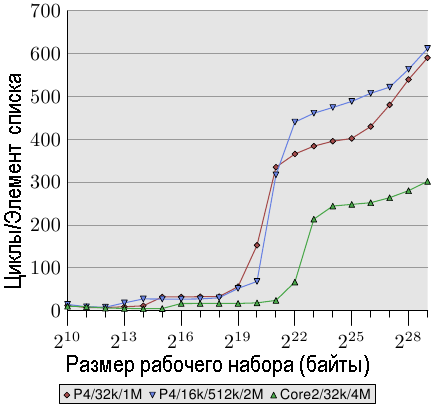
Рис.3.14: Преимущество большого размера кэш-памяти L2/L3
И последний фактором, влияющим на эффективность последовательной обработки данных в кэш-памяти, является ее размер. Это должно быть очевидным, но, тем не менее, на этот фактор следует указать. На рис.3.14 показано время для теста Increment с элементами размером в 128 байтов (NPAD=15 для 64-разрядных машин). На этот раз мы видим, измерения с трех разных машин. В первых двух машинах используется процессор P4, в последней — Core 2. Первые две различаются размерами кэш-памяти. В первом процессоре имеется 32k кэш-памяти L1d и 1M кэш-памяти L2. Во второй имеется 16k кэш-памяти L1d, 512k кэш-памяти L2 и 2M кэш-памяти L3. В процессоре Core 2 имеется 32k кэш-памяти L1d и 4M кэш-памяти L2.
На графике интересно не то, насколько хорошо процессор Core 2 работает в сравнении с другими двумя процессорами (хотя это и впечатляет). Наибольший интерес представляет та часть графика, где размер рабочего набора является слишком большим для соответствующей кэш-памяти последнего уровня и участие в работе принимает основная память.
Таблица 3.2. Попадания и пропуски при последовательном обходе списка и при обходе списка в произвольном порядке
| Размер набора |
Последовательно | Произвольным образом | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Попадания L2 |
Промахи L2 |
Число итераций |
Отношение пропусков / попаданий |
Доступ к L2 на одну итерацию |
Попадания L2 |
Промахи L2 |
Число итераций |
Отношение пропусков / попаданий |
Доступ к L2 на одну итерацию | |
| 220 | 88 636 | 843 | 16 384 | 0.94% | 5.5 | 30 462 | 4721 | 1 024 | 13.42% | 34.4 |
| 221 | 88 105 | 1 584 | 8 192 | 1.77% | 10.9 | 21 817 | 15 151 | 512 | 40.98% | 72.2 |
| 222 | 88 106 | 1 600 | 4 096 | 1.78% | 21.9 | 22 258 | 22 285 | 256 | 50.03% | 174.0 |
| 223 | 88 104 | 1 614 | 2 048 | 1.80% | 43.8 | 27 521 | 26 274 | 128 | 48.84% | 420.3 |
| 224 | 88 114 | 1 655 | 1 024 | 1.84% | 87.7 | 33 166 | 29 115 | 64 | 46.75% | 973.1 |
| 225 | 88 112 | 1 730 | 512 | 1.93% | 175.5 | 39 858 | 32 360 | 32 | 44.81% | 2 256.8 |
| 226 | 88 112 | 1 906 | 256 | 2.12% | 351.6 | 48 539 | 38 151 | 16 | 44.01% | 5 418.1 |
| 227 | 88 114 | 2 244 | 128 | 2.48% | 705.9 | 62 423 | 52,049 | 8 | 45.47% | 14 309.0 |
| 228 | 88 120 | 2 939 | 64 | 3.23% | 1 422.8 | 81 906 | 87 167 | 4 | 51.56% | 42 268.3 |
| 229 | 88 137 | 4 318 | 32 | 4.67% | 2 889.2 | 119 079 | 163 398 | 2 | 57.84% | 141 238.5 |
Как и ожидалось, чем больше размер кэш-памяти последнего уровня, тем дольше кривая остается на низком уровне, соответствующем затратам на доступ к кэш-памяти L2. Важно отметить благодаря чему достигается повышенная производительность. Второй процессор (который чуть старее) может обрабатывать рабочий набор размером в 220 байтов вдвое быстрее, чем первый процессор. Все это благодаря увеличенному размеру кэш-памяти последнего уровня. Процессор Core 2 с 4M кэш-памяти L2 выполняет это работу еще лучше.
Если нагрузка меняется случайным образом, то это не столь важно. Но если нагрузку можно изменить в соответствие с размером кэш-памяти последнего уровня, то скорость выполнения программы можно увеличить весьма существенно. Вот почему иногда стоит потратиться на процессор с кэш-памятью большего размера.
Измерение однопоточного доступа, осуществляемого в произвольном порядкеМы видели, что процессор благодаря предварительной загрузке кэш-строк в кэш-память L2 и L1d может скрыть большую часть затрат, связанных с оперативной памятью и даже с задержками доступа к кэш-памяти L2. Одна это может хорошо работать только в случае, когда доступ к памяти предсказуем.
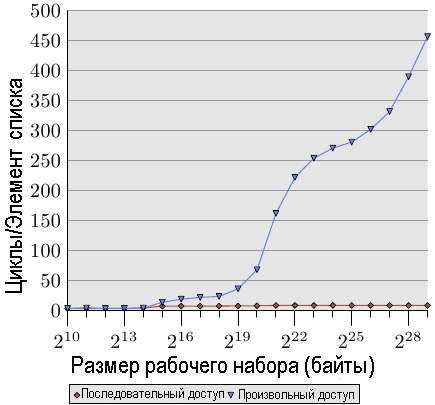
Рис.3.15: Чтение в последовательном / произвольном порядке, NPAD=0
Если доступ непредсказуем или происходит случайным образом, то ситуация совершенно иная. На рис.3.15 сравнивается время доступа к отдельному элементу списка при последовательном доступе (как на рис.3.10) с временем доступа в случае, когда элементы списка распределены в рабочем наборе случайным образом. Порядок определяется с помощью связного списка, порядок элементов в котором задан случайным образом. Процессор не может гарантированно выполнять предварительную загрузку данных. Это может произойти только случайно, если элементы, которые обрабатываются почти пдряд, в памяти также расположены близко друг к другу.
На рис.3.15 видно два важных факта, которые следует отметить. Во-первых, большее число циклов, которое требуется при увеличении размеров рабочего набора. Машина позволяет получить доступ к основной памяти за 200-300 циклов, но здесь значение достигает 450 циклов и более. Мы сталкивались с таким феноменом ранее (сравните с рис 3.11). В действительности, использование автоматической предварительной загрузки приводит здесь к потерям.
Вторым интересным фактом является то, что у кривой нет ровных горизонтальных участков таких, как в случае последовательного доступа. Кривая продолжает расти. Чтобы объяснить это, нам нужно измерить доступ программы к кэш-памяти L2 при различных размерах рабочего набора. Результат виден на рис.3.16 и в таблице 3.2.
На рисунке показано, что, когда размер рабочего набора больше, чем размер кэш-памяти L2, начинает расти относительная величина промахов кэш-памяти (промах кэш-памяти L2 / доступ в кеш-память L2). На рис.3.15 кривая имеет аналогичную форму: она резко растет, затем немного уменьшает наклон, а затем снова начинает расти. Есть тесная взаимосвязь с графиком числа циклов для отдельного элемента списка. Показатель промахов для кэш-памяти L2 будет расти до тех пор, пока он, в конечном счете, не достигнет почти 100%. При достаточно большом рабочем наборе (и размере основной памяти) вероятность того, что любые случайным образом выбираемые кэш-строки находятся в кэш-памяти L2 или будут загружены процессом, может произвольным образом снижаться.
Увеличение количества промахов кэш-памяти указывает только на некоторые bp затрат. Но есть и другой показатель. Если вглянуть на таблицу 3.2, то в столбцах "Доступ к L2 на одну итерацию" видно, что растет общее количество кэш-памяти L2, используемой в каждой итерации программы. Каждый следующий рабочий набор в два раза больше, чем предыдущий. Таким образом, без кэширования можно было бы ожидать двойное увеличение затрат на доступ к основной памяти. При наличии кэш-памяти и (почти) идеальной предсказуемости мы видим в данных, относящихся к последовательному доступу, незначительное увеличение использования кэш-памяти L2. Это увеличение связано с увеличением размера рабочего набора и больше ни с чем.
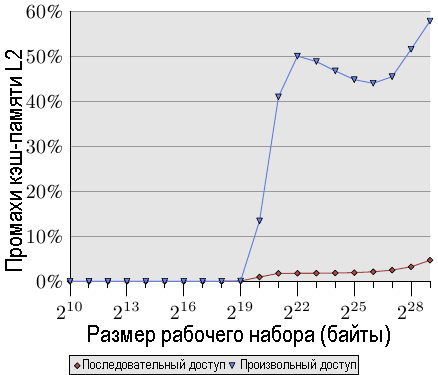
Рис.3.16: Показатель промахов кэш-памяти L2d
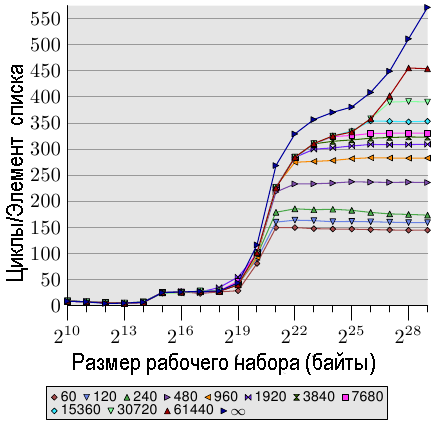
Рис.3.17: Постраничный доступ в произвольном порядке, NPAD=7
При доступе в случайном порядке, время доступа к каждому элементу увеличивается более чем на 100% при каждом удвоении размера рабочего набора. Это значит, что среднее время доступа к каждому элементу списка увеличивается, т. к. размер рабочего набора только удваивается. Это обусловлено ростом числа промахов кэш-памяти TLB. На рис. 3.17 мы видим затраты при доступе в случайном порядке для значения NPAD = 7. Только на этот раз алгоритм рандомизации изменен. Тогда как в обычном случае весь список рандомизируется (устанавливается случайный порядок доступа к элементам списка — прим.пер.) в виде единого блока (помечено символом ∞), с помощью остальных 11 кривых показаны варианты, когда рандомизация выполняется для более мелких блоков. Для кривой, помеченной как '60',отдельно рандомизируется каждый набор из 60 страниц (245 760 байт). Это значит, что перед тем, как перейти к элементу в следующем блоке, выполняется обход всех элементов списка текущего блока. Это приводит к ограничению числа записей кэш-памяти TLB, которые используются в каждый конкретный момент.
Размер элемента для NPAD=7 равен 64 байта, что соответствует размеру кэш-строки. Из-за того, что доступ к элементам списка выполняется в случайном порядке (рандомизирован), маловероятно, что аппаратная предварительная загрузка окажет какое-нибудь влияние, по крайней мере более чем на несколько элементов. Это значит, что показатель промахов кэш-памяти L2 не будет сильно отличаться от случая, когда весь список рандомизируется в виде одного блока. При увеличении размера блока результаты выполнения теста асимптотически приближаются к кривой, соответствующей рандомизации одного блока. Это значит, что выполнение этого последнего теста в значительной степени зависит от промахов кэш-памяти TLB. Если удастся снизить количество промахов кэш-памяти TLB, то производительность значительно увеличится (в одном из тестов мы позже увидим увеличение до 38%).
| Назад | Оглавление | Вперед |