





Библиотека сайта rus-linux.net
Поиск текста в PDF-документах из командной строки с помощью pdfgrep
Оригинал: How to Search PDF Files from the Terminal with pdfgrep
Автор: Bruno Edoh
Дата публикации: 12 декабря 2017 года
Перевод: А. Кривошей
Дата перевода: февраль 2018 г.
Утилиты командной строки, такие как grep и ack-grep, отлично подходят для поиска паттернов в текстовых файлах с использованием регулярных выражений. Но пытались ли вы когда-нибудь использовать эти утилиты для поиска паттернов в PDF-файлах? Вы не получите никакого результата, поскольку эти утилиты не могут читать файлы PDF, они работают только с текстовыми файлами.
, как следует из названия, представляет собой небольшую утилиту командной строки, которая позволяет искать текст в PDF-документе без открытия файла. Это безумно быстро - быстрее, чем поиск, предоставляемый практически всеми программами для просмотра PDF. Основное различие между grep и pdfgrep заключается в том, что pdfgrep работает со страницами, тогда как grep работает со строками. Он также выводит одну строку несколько раз, если для этой строки найдено несколько совпадений. Давайте посмотрим, как использовать эту утилиту.
Установка
В Ubuntu и других дистрибутивах на его базе установка очень проста:
$ sudo apt install pdfgrep
В других дистрибутивах просто введите pdfgrep в строке поиска менеджера пакетов, и скорее всего вы его там найдете. Также можете просмотреть , если вы хотите поиграть с исходным кодом.
Тестирование
Теперь, когда наш инструмент установлен, давайте перейдем к тестовому прогону. Команда pdfgrep имеет следующий формат:
pdfgrep [OPTION...] PATTERN [FILE...]
OPTION - это список дополнительных атрибутов, например, -i или --ignore-case указывают, что нужно игнорировать регистр в заданном регулярном выражении при сопоставлении его с файлом.
PATTERN - это просто расширенное регулярное выражение.
FILE - это имя файла, если он находится в том же каталоге или путь к файлу.
Я запустил команду на файле официальной документации Python 3.6. Результат на картинке ниже.
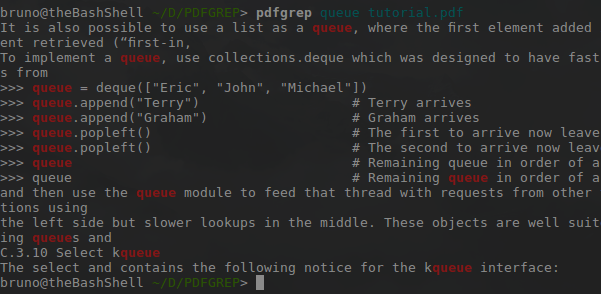
Красная подсветка указывает на все места, где встречалось слово «queue». Использование в качестве опции -i обусловило включение в качестве совпадения слова «Queue».
Дополнительные опции
Для pdfgrep имеется целый ряд интересных опций его использования. Я расскажу о некоторых из них.
-c или --count: эта опция подавляет нормальный вывод совпадений. Вместо отображения длинного списка совпадений отображается только их количество.
-p или -page-count: этот параметр выводит номера страниц, на которых найдены совпадения, и количество вхождений паттерна на странице.
-m или --max-count [число]: задает максимальное количество совпадений. Это означает, что при достижении заданного количества совпадений команда перестает читать файл.
Полный список поддерживаемых опций можно найти на страницах руководства или в pdfgrep. Не забывайте, что pdfgrep может искать одновременно в нескольких файлах, если вы работаете с объемными файлами. Цвет подсветки соответствия по умолчанию можно изменить с помощью переменной окружения GREP_COLORS.