





Библиотека сайта rus-linux.net
Использование команды uniq в Linux (10 примеров)
Оригинал: Linux Uniq Command Tutorial for Beginners (10 examples)
Автор: Himanshu Arora
Дата публикации: 23 мая 2017 г.
Перевод: А.Панин
Дата перевода: 24 мая 2017 г.
Если вы являетесь пользователем интерфейса командной строки Linux и ваша работа связана с редактированием текстовых файлов, вы должны знать (если уже не знаете) о существовании огромного количества утилит с интерфейсом командной строки, которые могут помочь вам в различных ситуациях. Например, одной из таких утилит является утилита uniq, выводящая или удаляющая из вывода повторяющиеся строки, находящиеся в текстовом файле.
В данной статье мы будем обсуждать методику использования утилиты uniq на основе простых для понимания примеров. Но перед тем, как приступить к рассмотрению примеров стоит упомянуть о том, что все примеры и инструкции из данной статьи были протестированы в системе Ubuntu 16.04 LTS.
Утилита uniq в Linux
Как уже говорилось ранее, утилита uniq осуществляет вывод или удаление из вывода повторяющихся строк. А это синтаксис соответствующей команды:
$ uniq [ПАРМЕТР] ... [ВХОДНОЙ ФАЙЛ [ВЫХОДНОЙ ФАЙЛ]]
А это описание функций утилиты с ее страницы руководства: "Утилита осуществляет фильтрацию идентичных строк из ВХОДНОГО ФАЙЛА (или из стандартного потока ввода) и выводит информацию в ВЫХОДНОЙ ФАЙЛ (или стандартный поток вывода). При вызове без параметров идентичные строки объединяются в рамках первых найденных экземпляров строк."
Ниже приведен ряд примеров, которые помогут вам лучше понять принцип работы рассматриваемой утилиты.
1. Удаление повторяющихся строк из вывода
Предположим, что в нашем распоряжении имеется файл со следующими строками:
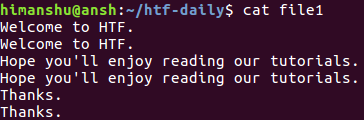
Несложно заметить, что каждая из строк повторяется. Теперь применим утилиту uniq по отношению к этому файлу и посмотрим, к чему это приведет.
$ uniq file1

Очевидно, что вывод не содержит дубликатов строк. Обратите внимание на то, что содержимое оригинального файла с именем file1 в нашем случае осталось неизменным. Вы можете перенаправить вывод утилиты в другой файл в том случае, если вам нужно сохранить вывод для дальнейшей обработки.
2. Вывод информации о количестве дубликатов каждой из строк
Если вам нужно, вы можете использовать утилиту uniq для вывода информации о количестве повторений каждой из строк файла. Это может быть сделано с помощью параметра командной строки -c. Например, команда
$ uniq -c file1
будет генерировать следующий вывод:

Несложно заметить, что перед каждой из строк выводится число, соответствующее количеству ее повторений.
3. Вывод лишь повторяющихся строк
Для того, чтобы утилита uniq выводила лишь повторяющиеся строки, следует использовать параметр -D командной строки. Например, предположим, что файл с именем файл file1 теперь содержит дополнительную строку в конце (обратите внимание на то, что эта строка не повторяется).
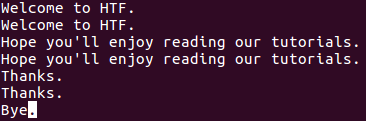
Теперь при исполнении команды
$ uniq -D file1
будет генерироваться следующий вывод:
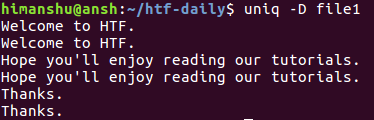
Как вы видите, параметр -D сообщает утилите uniq о необходимости вывода всех повторяющихся строк, включая их повторы. Для лучшей читаемости вы можете активировать режим вывода пустой строки после каждой из групп повторяющихся строк с помощью параметра --all-repeated.
$ uniq --all-repeated[=МЕТОД] file1
Данный параметр требует от пользователя обязательного указания метода добавления разделителя. Строки могут добавляться к разделителю (то есть, пустой строке) с помощью метода prepend или разделяться с помощью него с помощью метода append. Например, в данном случае используется метод prepend.
![]()
Более того, если вам нужно, чтобы утилита выводила лишь по одному экземпляру каждой из повторяющихся строк, вы можете воспользоваться параметром -d. Это пример его использования:

Очевидно, что в выводе приводится лишь по одному экземпляру строки из каждой группы.
4. Пропуск начальных фрагментов строк
Иногда, в зависимости от ситуации, совпадение двух строк может быть установлено по совпадению определенных частей этих строк. Например, рассмотрим следующий файл:
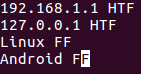
Теперь предположим, что строки должны считаться совпадающими или не совпадающими на основании совпадения или несовпадения их вторых полей (то есть HTF или FF) и вам нужно сделать так, чтобы утилита uniq использовала такой же критерий сравнения, чего несложно добиться с помощью параметра командной строки -f.
$ uniq -f [количество-прпускаемых-полей] [имя-файла]
Параметр -f требует от вас обязательной передачи числа, которое соответствует количеству полей, которые нужно пропустить. Например, в нашем случае мы передаем в качестве значения параметр -f значение 1, так как мы хотим, чтобы утилита uniq пропустила лишь первое поле:
$ uniq -f 1 file1

Из вывода очевидно, что утилита uniq посчитала первую и третью строку повторяющимися исключительно на основе их вторых полей.
5. Вывод всех строк с разделением групп повторяющихся строк
При необходимости вывода всех строк с разделением групп повторяющихся строк с помощью пустой строки вы можете использовать параметр --group. Как и в случае описанного выше параметра --all-repeated, параметр --groups требует от пользователя обязательного указания позиции пустой строки (prepend, append или both).
Это пример использования рассматриваемого параметра:
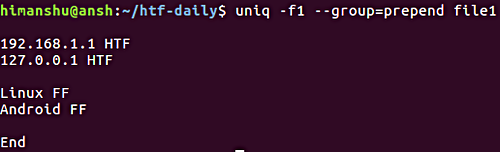
Обратите внимание на параметр -f, который обсуждался в предыдущем разделе.
6. Вывод лишь не повторяющихся строк
Вы уже наверняка поняли, что утилита uniq по умолчанию выводит лишь повторяющиеся строки. Но если вам нужно, вы можете сообщить ей о необходимости вывода лишь не повторяющихся или уникальных строк. Это делается с помощью параметра командной строки -u.
$ uniq -u [имя-файла]
В нашем случае команда будет выглядеть следующим образом:
$ uniq -u file1
Это пример ее использования:
![]()
Обратите внимание на параметр -f, который обсуждался в разделе 4.
7. Пропуск заданного количества символов в начале строк
В одном из предыдущих разделов мы обсуждали методику пропуска полей строк при использовании утилиты uniq. Однако, при необходимости вы можете сообщить утилите о необходимости пропуска не начальных полей, а начальных символов строк. Для доступа к соответствующей функции может использоваться параметр командной строки -s.
$ uniq -s [количество-символов] [имя-файла]
Например, предположим, что наш файл содержит следующие строки:
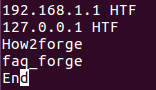
Теперь, если вы захотите, чтобы uniq пропустила первые 4 символа каждой строки перед их сравнением, вы сможете воспользоваться следующей командой:
$ uniq -s 4 file1
А это приведенная выше команда в действии:
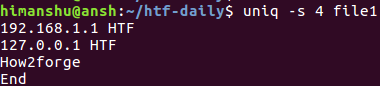
Несложно заметить, что четвертая строка (faq_forge) из оригинального файла была пропущена. Это объясняется тем, что после пропуска первых четырех символов третья и четвертая строки становятся идентичными для утилиты uniq и она выводит лишь первую из них.
8. Указание количества символов для сравнения
По аналогии с пропуском символов, вы можете сообщить утилите uniq о необходимости сравнения лишь заданного количества символов строк. Для этой цели вам придется использовать параметр командной строки -w.
$ uniq -w [количество-символов] [имя-файла]
Например, предположим, что файл содержит следующие строки:
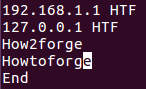
Теперь при необходимости ограничения диапазона символов строк для сравнения тремя первыми символами, может использоваться следующая команда:
$ uniq -w 3 file1
Это приведенная выше команда в действии:
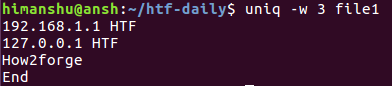
Так как первые три символа третьей и четвертой строк совпадают, эти строки считаются утилитой идентичными. По этой причине в выводе находится лишь третья строка.
9. Сравнение строк без учета регистра
По умолчанию утилита uniq осуществляет сравнение строк с учетом регистра символов. Однако, вы можете активировать режим сравнения строк без учета регистра символов с помощью параметра командной строки -i.
Например, предположим, что мы будем использовать файл с содержимым, аналогичным рассмотренному в предыдущем разделе, но теперь четвертая строка будет начинаться с символов H, O и W в верхнем регистре.
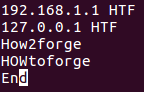
Теперь, если вы попытаетесь выполнить рассмотренную в предыдущем разделе команду, вы получите отличный вывод:
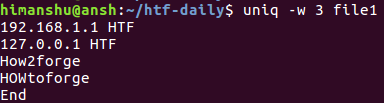
Это объясняется тем, что первые три символа третьей и четвертой строк отличны для утилиты uniq ввиду их регистра. В подобных ситуациях вы можете активировать режим сравнения строк без учета регистра с помощью параметра командной строки -i.
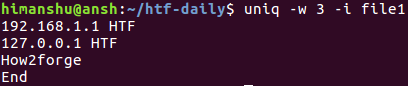
10. Использование завершающего нулевого символа вместо символа перехода на новую строку
По умолчанию утилита uniq генерирует вывод с завершающим символом перехода на новую строку. Однако, при необходимости вы можете активировать режим использования завершающего нулевого символа (полезный при вызове uniq из сценариев). Для этого следует использовать параметр командной строки -z:
$ uniq -z [имя-файла]
Заключение
Мы рассмотрели практически все поддерживаемые утилитой uniq параметры командной строки, поэтому вам остается лишь самостоятельно испытать их в работе для того, чтобы лучше понять их принцип работы и функции. И как обычно, в случае каких-либо сомнений и вопросов следует обращаться к .
О других полезных консольных командах вы можете почитать в следующих статьях:
- Himanshu Arora, перевод: А.Панин, "7 примеров использования команды cmp в Linux"
- Himanshu Arora, перевод: А.Панин, "14 примеров практического использования команды find в Linux"
- Himanshu Arora, перевод: А.Панин, "8 примеров использования команды locate в Linux"
- Himanshu Arora, перевод: А.Панин, "16 практических примеров использования команды ls в Linux"
- Himanshu Arora, перевод: А.Панин, "Полезные параметры архиватора 7zip - часть 1"