





Библиотека сайта rus-linux.net
Хэш-таблицы: теория и практика
Оригинал: Hash Tables-Theory and Practice
Автор: Mihalis Tsoukalos
Дата публикации: 12 октября 2015 г.
Перевод: A.Панин
Дата перевода: 13 октября 2015 г.
Впервые я узнал о хэш-таблицах при изучении курса теории компиляторов в ходе обучения на бакалавра в университете. Если говорить честно, в тот момент я не до конца понял их устройство и не осознал их важности. На данный момент я знаю о хэш-таблицах гораздо больше и решил написать статью для того, чтобы все читатели также узнали о них.
Хэш-таблицы могут быть реализованы с помощью любого языка программирования, включая Awk. Однако, выбор языка программирования не является важным по сравнению с другими возникающими в ходе их реализации кардинальными решениями. Хэш-таблицы используются при реализации компиляторов, баз данных, систем кэширования данных, ассоциативных массивов и других механизмов и программных продуктов. Хэш-таблицы являются одними из наиболее важных структур данных, изучаемых в рамках курсов компьютерных наук.
Постановка задачи
Задача, которую я буду рассматривать в качестве примера в рамках данной статьи, заключается в установлении количества слов из одного текстового файла, присутствующих в другом текстовом файле. Все программы из данной статьи будут использовать один и тот же текстовый файл для заполнения хэш-таблицы (этот текстовый файл будет содержать текст книги "Гордость и предубеждение"). Другой текстовый файл (содержащий текст книги "Приключения Тома Сойера") будет использоваться для тестирования производительности хэш-таблицы. Вы можете загрузить оба текстовых файла с ресурса Project Gutenberg.
В следующем выводе приводится информация о количестве слов в каждом из упомянутых файлов:
$ wc AofTS.txt
9206 73845 421884 AofTS.txt
$ wc PandP.txt
13426 124589 717573 PandP.txt
Как видите, оба текстовых файла имеют относительно большой размер, что положительно скажется на корректности тестов. В реальной жизни ваши хэш-таблицы не должны содержать такой же большой объем данных. Для того, чтобы удалить различные управляющие символы, а также символы пунктуации и числа, оба текстовых файла должны быть подвергнуты дополнительной обработке:
$ strings PandP.txt > temp.INPUT
$ awk '{for (i = 1; i <= NF; i++) print $i}' temp.INPUT > new.INPUT
$ cat new.INPUT | tr -cd '![a-zA-Z]\n' > INPUT
$ strings AofTS.txt > temp.CHECK
$ awk '{for (i = 1; i <= NF; i++) print $i}' temp.CHECK > new.CHECK
$ cat new.CHECK | tr -cd '![a-zA-Z]\n' > empty.CHECK
$ sed '/!/d' empty.CHECK > temp.CHECK
$ sed '/^\s*$/d' temp.CHECK > CHECK
Причина упрощения содержимого обоих фалов состоит в том, что в случае недостаточно обработки некоторые управляющие символы могут приводить к аварийному завершению программ, созданных с использованием языка программирования C. Ввиду того, что целью данной статьи является демонстрация приемов разработки и использования хэш-таблиц, я решил упростить входные данные, а не тратить время на поиск причины аварийного завершения программы и модификацию кода на языке C.
После создания хэш-таблицы с данными из первого файла (с именем INPUT) данные из второго файла (с именем CHECK) будут использоваться для тестирования хэш-таблицы. Именно таким образом хэш-таблицы чаще всего используются на практике.
Теоретическая информация
Позвольте мне начать с определения хэш-таблицы. Хэш-таблица - это структура данных, которая содержит одну или большее количество пар ключ-значение. Хэш-таблица может содержать ключи любого типа.
Хэш-таблица использует хэш-функцию для вычисления индекса в рамках массива корзин или слотов, в котором может быть найдено корректное значение. В идеальном случае хэш-функция будет размещать каждый ключ в отдельной корзине. К сожалению, такое случается крайне редко. На практике хэш-функции работают таким образом, что в одной корзине размещается более одного ключа. Наиболее важной характеристикой хэш-таблицы является количество корзин. Количество корзин учитывается хэш-функцией. Второй наиболее важной характеристикой хэш-таблицы является используемая хэш-функция. Ключевой задачей хэш-функции является генерация равномерно распределенных хэш-значений.
На основе вышесказанного вы можете сделать вывод о том, что время поиска значения в хэш-таблице будет масштабироваться по формуле O(n/k), где n является количеством ключей, а k - размером массива хэш-таблицы. Несмотря на то, что на первый взгляд сокращение времени поиска значений кажется незначительным, вы должны понимать, что в случае использования хэш-таблицы с массивом из 20 корзин время поиска значения уменьшится в 20 раз.
Важно, чтобы хэш-функция демонстрировала постоянство поведения и генерировала одинаковые хэш-значения для идентичных ключей. Коллизия происходит тогда, когда для двух ключей генерируется одно и то же значение - и это не является чем-то необычным. Существует много способов обработки коллизий.
Хорошим решением является использование отдельных цепочек. Хэш-таблица по своей сути является массивом из указателей, каждый из которых указывает на следующий ключ с тем же хэш-значением. В случае коллизии ключ будет добавлен в течение короткого постоянного промежутка времени в начало связанного списка. Проблема в данном случае будет заключаться в том, что при необходимости поиска ключа на основе хэш-значения вам придется осуществлять поиск ключа по всему связанному списку. В худшем случае может понадобиться обход всего связанного списка - это главная причина, по которой связанный список не должен быть очень большим, исходя из чего можно сделать вывод о необходимости создания большого количества корзин.
Как вы можете предположить, разрешение коллизий связано с использованием какого-либо алгоритма линейного поиска; исходя из этого, вам понадобится хэш-функция, которая минимизирует количество коллизий настолько, насколько это возможно. Другими техниками разрешения коллизий являются открытая адресация, алгоритм Robin Hood hasing и использование двух различных хэш-функций.
Преимущества хэш-таблиц:
-
В хэш-таблице с "корректным" количеством корзин средняя цена каждой операции поиска значения не зависит от количества элементов таблицы.
-
Хэш-таблицы особенно эффективны в том случае, если максимальное количество элементов может быть предсказано заранее, благодаря чему фрагмент памяти для хранения массива корзин оптимального размера может резервироваться однократно без последующих операций повторного резервирования.
-
В том случае, если набор пар ключ-значение является фиксированным и известным заранее (соответственно, операции добавления и удаления элементов не будут позволены), вы можете сократить среднюю цену операции поиска значения, выбрав корректные хэш-функцию, размер таблицы и тип внутренних структур данных.
Хэш-таблицы также имеют некоторые недостатки:
-
Они не предназначены для хранения отсортированных данных. Использование хэш-таблицы для сортировки данных не является продуктивным.
-
Хэш-таблицы не эффективны в том случае, если количество элементов очень мало, ведь, несмотря на то, что операции с хэш-таблицами выполняются в течение в среднем равных промежутков времени, цена операции хэширования с использованием качественной хэш-функции может быть значительно выше, чем цена операции поиска на основе алгоритма поиска в списке или в дереве.
-
При реализации определенных приложений для обработки строк, таких, как приложения для проверки орфографии, хэш-таблицы могут быть менее эффективными, чем деревья или конечные автоматы.
-
Несмотря на то, что средняя цена операции является постоянной и достаточно малой, цена отдельной операции может оказаться достаточно большой. В частности, если хэш-таблица использует механизм динамического изменения размера массива, для одной из операций удаления или добавления ключа может потребоваться время, пропорциональное количеству элементов таблицы. Эта особенность может превратиться в серьезный недостаток в приложениях, которые должны выводить результаты без промедления.
-
Хэш-таблицы работают достаточно неэффективно при наличии множества коллизий.
Как вы наверняка поняли, не каждая задача может быть решена с помощью хэш-таблиц одинаково эффективно. В любом случае, вы должны рассматривать и исследовать все доступные структуры для хранения данных перед тем, как принять решение о том, какие из них следует использовать.
На Рисунке 1 схематично изображена простая хэш-таблица с ключами и значениями. В качестве хэш-функции используется функция вычисления остатка при делении на 10; исходя из этого, потребуются десять корзин, так как при делении на 10 остаток может быть представлен лишь 10 значениями. Использование десяти корзин не является достаточно хорошей идеей, особенно в том случае, если в таблицу будет добавляться большое количество элементов, но для иллюстрации принципа работы хэш-таблицы использование такого количества корзин вполне допустимо.
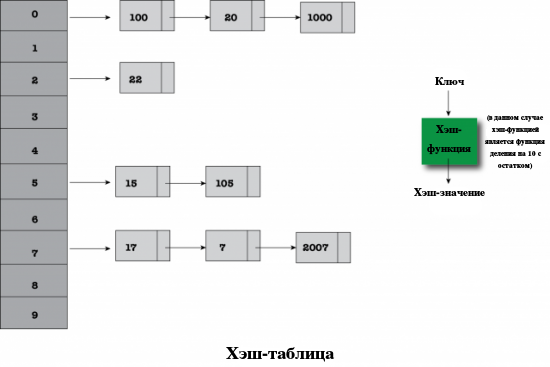
Рисунок 1. Простая хэш-таблица
Подводя итог, можно сказать, что при создании хэш-таблицы необходимо следовать следующим принципам:
-
Не следует создавать слишком большое количество корзин; следует создавать ровно столько корзин, сколько требуется.
-
Хэш-функция должна обрабатывать настолько большой объем информации о ключе, насколько возможно. Это не такая уж тривиальная задача.
-
Хэш-функция должна генерировать различные значения для похожих ключей.
-
Каждая корзина должна содержать одно и то же количество ключей или, по крайней мере, их сопоставимые количества (это очень желательное свойство).
-
При соблюдении некоторых принципов можно снизить вероятность возникновения коллизий. Во-первых, количество корзин должно быть представлено простым числом. Во-вторых, чем больше размер массива, тем меньше вероятность возникновения коллизий. Наконец, вы должны убедиться в том, что хэш-функция является достаточно проработанной для распределения возвращаемых значений настолько равномерно, насколько это возможно.
Добавление, удаление и поиск элементов
Основными операциями, выполняемыми с хэш-таблицами являются добавление, удаление и поиск элементов. Вы можете использовать значение, генерируемое хэш-функцией, для установления того, где в рамках хэш-таблицы следует сохранить ключ. Впоследствии эта же хэш-функция может использоваться для установления того, где в рамках хэш-таблицы следует искать значение данного ключа.
После заполнения хэш-таблицы поиск элементов может осуществляться по аналогии их добавлением. Сначала хэш-функция применяется к значению ключа, после чего осуществляется переход к заданной позиции в массиве, обход соответствующего связанного списка и установление наличия в нем интересующего ключа. Количество шагов в описанном случае будет постоянным O(1). В худшем случае время поиска элемента в хэш-таблице может достигать O(n) тогда, когда все ключи хранятся в одной корзине. Тем не менее, вероятность такого исхода настолько мала, что в общем случае, как в идеальном случае, можно считать количество шагов постоянным O(1).
Вы можете найти множество реализаций хэш-таблиц в сети Интернет или в книгах, посвященных рассматриваемой теме. Наиболее сложным аспектом использования хэш-таблиц является выбор подходящего количества корзин, а также выбор эффективной хэш-функции, которая будет распределять значения настолько равномерно, насколько это возможно. Неравномерное распределение значений приведет к увеличению количества коллизий и, соответственно, к увеличению цены их разрешения.
Реализация на языке программирования C
Код первой реализации хэш-таблицы будет сохранен в файле с именем ht1.c. Реализация использует отдельные цепочки, так как их наличие вполне обоснованно. Для простоты имена двух используемых файлов заданы на уровне кода программы. После ввода данных и создания хэш-таблицы программа начинает последовательное чтение слов из второго файла с проверкой наличия каждого из этих слов в хэш-таблице.
В Листинге 1 показан исходный код приложения на языке C из файла ht1.c.
Листинг 1. ht1.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
#define TABLESIZE 5
// Связанный список
typedef struct node
{
char *data;
struct node *next;
} node;
// Хэш-функция: возвращаемое значение будет остатком от деления разности между
// значением первого символа строки и значением первого строкового символа
// таблицы ASCII на переданное значение размера таблицы.
unsigned int hash(const char *str, int tablesize)
{
int value;
// Получение значения первого символа строки
value = toupper(str[0]) - 'A';
return value % tablesize;
}
static int lookup(node *table[], const char *key)
{
unsigned index = hash(key, TABLESIZE);
const node *it = table[index];
// Попытка установить наличие соответствующего ключа в связанном списке
while(it != NULL && strcmp(it->data, key) != 0)
{
it = it->next;
}
return it != NULL;
}
int insert(node *table[], char *key)
{
if( !lookup(table, key) )
{
// Поиск необходимого связанного списка
unsigned index = hash(key, TABLESIZE);
node *new_node = malloc(sizeof *new_node);
if(new_node == NULL)
return 0;
new_node->data = malloc(strlen(key)+1);
if(new_node->data == NULL)
return 0;
// Добавление нового ключа и обновление указателя на начало связанного списка
strcpy(new_node->data, key);
new_node->next = table[index];
table[index] = new_node;
return 1;
}
return 0;
}
// Заполнение хэш-таблицы
// Первый параметр: Переменная хэш-таблицы
// Второй параметр: Структура файла со словами
int populate_hash(node *table[], FILE *file)
{
char word[50];
char c;
do {
c = fscanf(file, "%s", word);
// Важно: следует удалить символ перехода на следующую строку
size_t ln = strlen(word) - 1;
if (word[ln] == '\n')
word[ln] = '\0';
insert(table, word);
} while (c != EOF);
return 1;
}
int main(int argc, char **argv)
{
char word[50];
char c;
int found = 0;
// Инициализация хэш-таблицы
node *table[TABLESIZE] = {0};
FILE *INPUT;
INPUT = fopen("INPUT", "r");
// Заполнение хэш-таблицы
populate_hash(table, INPUT);
fclose(INPUT);
printf("Хэш-таблица заполнена!\n");
int line = 0;
FILE *CHECK;
CHECK = fopen("CHECK", "r");
do {
c = fscanf(CHECK, "%s", word);
// Важно: следует удалить символ перехода на следующую строку
size_t ln = strlen(word) - 1;
if (word[ln] == '\n')
word[ln] = '\0';
line++;
if( lookup(table, word) )
{
found++;
}
} while (c != EOF);
printf("В хэш-таблице обнаружено %d слов!\n", found);
fclose(CHECK);
return 0;
}
Более удачная реализация хэш-таблицы на языке программирования C
Код второй реализации хэш-таблицы будет сохранен в файле с именем ht2.c. В данной реализации также используются отдельные цепочки. Большая часть кода на языке C данной реализации полностью идентична коду из файла с именем ht1.c, за исключением кода хэш-функции. Код модифицированной хэш-функции выглядит следующим образом:
int hash(const char *str, int tablesize)
{
int sum = 0;
// Является ли строка корректной?
if(str == NULL)
{
return -1;
}
// Вычисление суммы значений всех символов строки
for( ; *str; str++)
{
sum += *str;
}
// Возврат остатка от деления вычисленного значения суммы на переданное значение размера таблицы
return (sum % tablesize);
}
Данная функция имеет преимущество перед функцией из прошлого примера, которое заключается в том, что учитываются значения всех символов строки, а не только ее первого символа. Исходя из этого, генерируемое число, соответствующее позиции ключа в хэш-таблице, будет больше, что подразумевает возможность использования преимуществ хэш-таблицы с большим количеством корзин.
Тестирование производительности
Представленные тесты производительности далеки от точных и научных тестов. Они всего лишь иллюстрируют лучшие и худшие, а также корректные и некорректные параметры хэш-таблиц. Помните о том, что установить оптимальный размер хэш-таблицы не всегда просто.
Все программы компилируются с помощью следующей команды:
$ gcc -Wall <имя файла исходного кода>.c -o <имя программы>
Надежная утилита time вывела следующую информацию после четырехкратного исполнения программы ht1 с использованием четырех различных размеров хэш-таблицы:
$ grep define ht1.c #define TABLESIZE 101 $ time ./ht1 Хэш-таблица заполнена! В хэш-таблице обнаружено 59843 слов! real 0m0.401s user 0m0.395s sys 0m0.004s $ grep define ht1.c #define TABLESIZE 10 $ time ./ht1 Хэш-таблица заполнена! В хэш-таблице обнаружено 59843 слов! real 0m0.794s user 0m0.788s sys 0m0.004s $ grep define ht1.c #define TABLESIZE 1001 $ time ./ht1 Хэш-таблица заполнена! В хэш-таблице обнаружено 59843 слов! real 0m0.410s user 0m0.404s sys 0m0.004s $ grep define ht1.c #define TABLESIZE 5 $ time ./ht1 Хэш-таблица заполнена! В хэш-таблице обнаружено 59843 слов! real 0m1.454s user 0m1.447s sys 0m0.004s
На Рисунке 2 представлен график времени исполнения программы на основе исходного кода из файла ht1.c с четырьмя различными значениями константы TABLESIZE. Проблема реализации хэш-таблицы из файла ht1.c заключается в том, что производительность хэш-таблицы с 101 корзиной практически равна производительности хэш-таблицы с 1001 корзиной!
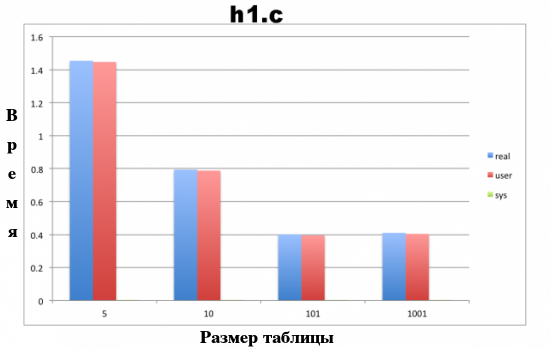
Рисунок 2. Время исполнения программы на основе исходного кода из файла ht1.c при использовании четырех различных значений константы TABLESIZE
А это результаты исполнения программы на основе исходного кода из файла ht2.c:
$ grep define ht2.c #define TABLESIZE 19 $ time ./ht2 INPUT CHECK Хэш-таблица заполнена! В хэш-таблице обнаружено 59843 слов! real 0m0.439s user 0m0.434s sys 0m0.003s $ grep define ht2.c #define TABLESIZE 97 $ time ./ht2 INPUT CHECK Хэш-таблица заполнена! В хэш-таблице обнаружено 59843 слов! real 0m0.116s user 0m0.111s sys 0m0.003s $ grep define ht2.c #define TABLESIZE 277 $ time ./ht2 INPUT CHECK Хэш-таблица заполнена! В хэш-таблице обнаружено 59843 слов! real 0m0.072s user 0m0.067s sys 0m0.003s $ grep define ht2.c #define TABLESIZE 997 $ time ./ht2 INPUT CHECK Хэш-таблица заполнена! В хэш-таблице обнаружено 59843 слов! real 0m0.051s user 0m0.044s sys 0m0.003s $ grep define ht2.c #define TABLESIZE 22397 $ time ./ht2 INPUT CHECK Хэш-таблица заполнена! В хэш-таблице обнаружено 59843 слов! real 0m0.049s user 0m0.044s sys 0m0.003s
На Рисунке 3 показан график времени исполнения программы на основе исходного кода из файла ht2.c при использовании пяти различных значений константы TABLESIZE. Все значения размера хэш-таблицы являются простыми числами. Причина использования простых чисел заключается в том, что они лучше подходят для выполнения операций деления с остатком. Это объясняется тем, что простое число не имеет положительных делителей кроме единицы и самого себя. В результате произведение простого числа и другого целого числа будет иметь меньше положительных делителей, чем произведение не являющегося простым числа и другого целого числа.
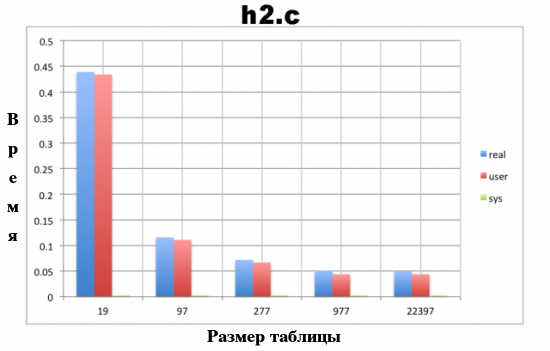
Рисунок 3. График времени исполнения программы на основе исходного кода из файла ht2.c при использовании пяти различных значений константы TABLESIZE
Как вы видите, новая хэш-функция работает гораздо продуктивнее хэш-функции из файла исходного кода ht1.c. В результате использования большего количества корзин значительно возрастает производительность хэш-таблицы. Тем не менее, по той причине, что количество слов в текстовых файлах ограничено, нет смысла использовать количество корзин, превышающее количество уникальных слов во входном файле.
Кроме того, полезно исследовать распределение ключей в реализации хэш-таблицы из файла исходного кода ht2.c при использовании двух различных количеств корзин. Следующая функция языка программирования C выводит количество ключей в каждой из корзин:
void printHashTable(node *table[], const unsigned int tablesize)
{
node *e;
int i;
int length = tablesize;
printf("Вывод информации о хэш-таблице с %d корзинами.\n", length);
for(i = 0; i<length; i++)
{
// printf("Корзина: %d\n", i);
// Получение первого элемента связанного списка
// для исследуемой корзины.
e = table[i];
int n = 0;
if (e == NULL)
{
// printf("Пустая корзина %d\n", i);
}
else
{
while( e != NULL )
{
n++;
e = e->next;
}
}
printf("Корзина %d содержит %d ключей\n", i, n);
}
}
На Рисунке 4 показано количество ключей в каждой корзине двух хэш-таблиц: с 97 корзинами и с 997 корзинами. Хэш-таблица с 997 корзинами соответствует требованиям к равномерному заполнению корзин, в то время, как в хэш-таблице с 97 корзинами наблюдается еще более равномерное распределение ключей. Тем не менее, в каждой из корзин хэш-таблиц большего размера всегда размещается меньшее количество ключей, что подразумевает размещение меньшего количества ключей в каждом из связанных списков, которое положительно влияет на на время поиска ключей.
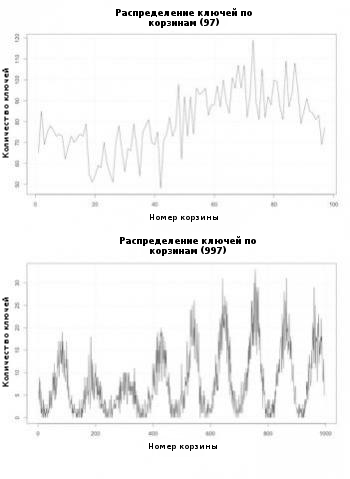
Рисунок 4. Количество ключей в каждой корзине двух хэш-таблиц с различным количеством корзин
Заключение
Хэш-таблицы являются важной частью курсов компьютерных наук и могут продуктивно использоваться при разработке программных продуктов. Я надеюсь, что данная статья поможет вам оценить их важность и понять особенности их создания и использования.