





Библиотека сайта rus-linux.net
На главную -> MyLDP -> Программирование и алгоритмические языки
| Ulrich Drepper "Как писать разделяемые библиотеки" | ||
| Назад | Оглавление | Вперед |
1.5.2. Перемещения символов
Динамический компоновщик должен выполнять перемещение для всех символов, которые используются во время выполнения программы, а поскольку они неизвестны во время компоновки, они должны быть определены в том же объекте в виде ссылки. Поскольку для разных вариантов архитектуры способы генерации кода различны, возможны задержки некоторых перемещений до тех пор, пока не будет выяснено, какие в действительности используются ссылки. Это имеет место во многих вариантах архитектуры при обращении к функциям. Все другие виды перемещений должны всегда обрабатываться раньше, чем объект будет использован. Мы будем игнорировать отложенные варианты перемещения, т.к. это просто способ отложить работу. В конечном итоге эта работа должна быть сделана, поэтому мы включим ее в наш анализ затрат. Чтобы прежде, чем объект будет использован, были в действительности выполнены все перемещения, нужно в переменной среды окружения LD BIND NOW установить некоторое непустое значение. Можно для отдельного объекта отключить использование отложенного перемещения, если в командную строку, используемую для вызова компоновщика, добавить параметр -z. Компоновщик для того, чтобы пометить объект DSO, установит флаг DF BIND NOW в записи DT FLAGS динамической секции. Эту настройку нельзя будет отменить без перекомпоновки объектов DSO или редактирования двоичного кода, хотя этой возможностью необходимо пользоваться только в том случае, когда это действительно необходимо.
Сам процесс поиска повторяется с самого начала для каждого перемещения символа в каждом загруженном объекте. Обратите внимание на то, что в различных объектах может быть много ссылок на один и тот же символ. Результат поиска для каждого объекта может быть различным, поскольку невозможно сократить этот процесс, за исключением разве что кэширования результатов, полученных для символа в каждом объекте, в случае, когда для одного и того же символа выполняется более одного перемещения. Область поиска, упоминаемая далее, может представлять собой упорядоченный список из подмножеств загруженные объекты, причем для разных объектов эти списки могут быть разными. Способ вычисления этой области довольно сложный и не связан с тем, что мы здесь обсуждаем; заинтересованного читателя мы отсылаем к спецификациям ELF и в раздел 1.5.4. Важно то, что размер этой области, как правило, напрямую зависит от количества загруженных объектов. Это еще один фактор, вследствие которого сокращение числа загружаемых объектов увеличивает производительность.
В настоящее время есть два различных способа реализации процесса поиска символа. Традиционный способ, применяемый для ELF, состоит из следующих шагов:
- Определяем хэш-значение для имени символа.
- В первом/следующем объекте в области поиска:
- Определяем хэш-группу для символа по его хеш-значению и размеру хэш-таблицы в объекте.
- Получаем смещение для имени символа и используем имя как строку с завершающим значением NUL.
- Сравнение имени символа с именем, для которого выполняется перемещение.
- Если имена совпадают, то также сравниваются версии. Это следует делать только в случае, если у ссылки и у определения одновременно указаны версии. Для этого также требуется сравнение строк. Если имя версии совпадает или если такое сравнение не выполняется, то мы нашли определение, которое искали.
- Если определение не совпадает, то то же самое повторяем со следующим элементом цепочки для данной хэш-группы.
- Если в цепочке больше нет элементов, то в текущем объекте нет определения и мы переходим к следующему объекту в области поиска.
- Если в области поиска объектов больше нет, то поиск оказался неудачным.
Обратите внимание, что проблемы не будет, если для того же самого символа в области поиска будет более одного определения. Алгоритм поиска символов просто берет первое определение, которое он находит. Обратите внимание, что определение в объекте DSO указываемое как слабо связанное (т. е. как weak), влияния оказывать не будет. Слабые определения играют роль при статической компоновке. Наличие нескольких определений, возможно, будет иметь некоторые неожиданные последствия. Предположим, что в объекте DSO 'A' определяется интерфейс и на него даются ссылки, а в объекте DSO 'B' определяется тот же самый интерфейс. Если теперь 'B' предшествует 'A' в области видимости, то ссылка в 'A' будет разрешена в соответствие с определением в 'B'. Говорят, что определение в 'B' замещает определение в 'A'. Это очень мощный прием, поскольку он позволяет без замены общего кода использовать более специализированную реализацию интерфейса. Одним из примеров применения этого механизма является использование функции LD PRELOAD динамического компоновщика в случае, когда дополнительные объекты DSO, которых не было на этапе компоновки, добавляются на этапе выполнения приложения. Но в плохо спроектированном коде подмена определений может привести к серьезным проблемам. Дополнительно об этом смотрите в разделе 1.5.4.
Если взглянуть на алгоритм, то видно, что производительность при каждом поиске зависит, среди прочих факторов, от длины хэш-цепочки и количества объектов в области поиска. Циклы по длине хэш-цепочки и по количеству объектов были описаны выше. Длины хэш-цепочек зависят от количества символов и от выбранного размера хэш-таблицы. Поскольку хэш-функция, используемая на начальном этапе работы алгоритма, никогда не должна изменяться, нам ничего не остается, как только управление этими двумя переменными. Во многих компоновщиках не уделяется должное внимание выбору подходящего размера для таблицы. В компоновщике GNU, если ему передается параметр -O (замечание: этот параметр должен получить компоновщик, а не компилятор), делается попытка оптимизировать размер хэш-таблицы с целью получить цепочки минимальной длины.
Замечание относительно текущей реализации оптимизации хэш-таблицы: В компоновщике из набора утилит GNU есть простая специальная эвристика, которая для коротких цепочек часто помогает получать таблицы маленького размера. В больших проекта из-за этого могут существенно возрасти начальные затраты. Общее потребление памяти иногда значительно сокращается, что рано или поздно может дать компенсацию, но, все же, рекомендуется проверять эффективность оптимизации. Вскоре будет разработана новая реализация компоновщика, в которой имеется улучшенный алгоритм.
Для измерения эффективности хеширования двух чисел важно следующее:
- средняя длина цепочки при успешном поиске;
- средняя длина цепочки при неудачном поиске.
Кажется странным говорить о неудачном поиске, но, фактически, это является правилом. Обратите внимание, что "неудачный" означает неудачный поиск только в текущих объектах. Количество успешных поисков более важно только для объектов, в которых реализовано практически, что необходимо найти. В системе Linux к этой категории, в основном, относятся только два объекта: библиотека языка C и сам динамический компоновщик.
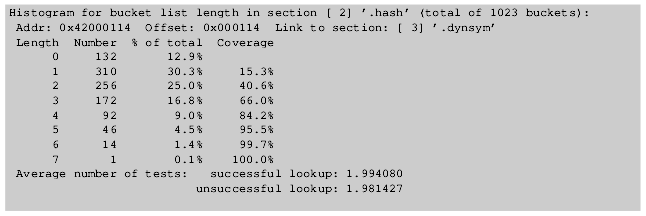
Рис.3: Результат, выдаваемый командой eu-readelf -I libc.so
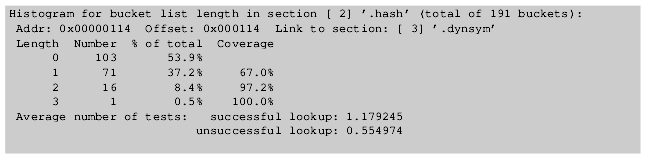
Рис.4: Результат, выдаваемый командой eu-readelf -I libnss files.so
Некоторые версии программы readelf непосредственно вычисляют значения и результат аналогичен показанному на рис.3 и 4. Данные в этих примерах указывают нам на несколько вещей. В зависимости от количества символов (2027 и 106) выбираемый размер таблицы будет существенно различаться. Для меньшей таблицы компоновщик может позволить себе иметь в хэш-таблице до 53,9% "лишних" записей, в которых нет данных. Для системы, совместимой с gABI, это только 412 байта. Если же такое количество накладных расходов допустить для двоичной библиотеки libc.so, то размер таблицы может быть 4 килобайта или даже больше. Разница большая. В компоновщике есть встроенная функция для подсчета затрат, которая также учитывает размер таблицы.
Увеличенный относительный размер таблицы означает, что у нас хэш-цепочки будут существенно короче. Это особенно актуально для цепочек средней длины при неудачном поиске. Среднее значение для небольшой таблицы составляет только 28% от среднего значения для большой таблицы.
Все, что должны показать эти числа, это эффект уменьшения числа символов в динамической таблице символов. При существенном уменьшении числа символов у компоновщика гораздо больше шансов снизить влияние того, что используется субоптимальная функция хэширования.
Еще один фактор, влияющий на затраты в алгоритме поиска, связан с самими строками. Для имен символов, которые хранятся в таблице строк, представляющей собой табличные структуры данных с символами, применяется простое сравнение строк. Строки хранятся в формате языка C; они заканчиваются символом NUL и поле, указывающее первоначальную длину, не используется. Это означает, что сравнение строк должно продолжаться до тех пор, пока не будет найден первый несовпадающий символ, либо - до конца строки. Такой подход плох в случае длинных строк с общими префиксами. К сожалению, эта ситуация не редкость.

В схеме трансформации имен, использовавшейся в компиляторе GNU C++ до версии 3.0, применялась схема трансформации, в которой первым шло имя члена вместе с определением списка параметров, а затем шли другие части имени, такие как пространства имен и имена вложенных классов. В результате если имена членов класса были различными, то имена символов имели отличия в самом начале. На рис.5. приведен пример описанной выше схемы трансформации имен для двух функций-членов класса.

Рис.5: Трансформированные имена, используемые в схеме gcc версий, ниже третьей

Рис.6: Трансформированные имена, используемые в обычной схеме интерфейса ABI языка C++
В новой схеме трансформации, используемой в сегодняшней версии gcc и во всех других компиляторах, которые совместимы с обычныи интерфейсом ABI языка C++, имена начинаются с пространства имен и имен классов и заканчиваться именами членов класса. На рис. 6 показан результат для маленького примера. Трансформированные имена двух функций-членов класса отличаются только после 43-го символа. В случае, если эти два символа попадут в одну и ту же хэш-группу, то это, действительно, будет плохим примером производительности {Примечание 4}.
Примечание 4: Некоторые спрашивают, "а почему бы не искать с конца?". Вспомните, что это строки на языке C это не строки языка PASCAL. Мы не знаем длину и, следовательно, нам для определения длины придется прочитать каждый отдельный символ строки. Результат может быть еще хуже.
В языке Ада имеются подобные проблемы. В стандартной библиотеке языка Ada для gcc во всех символах используется префикс ada, затем идут имена пакетов и подпакетов, за которыми идет имя функции. На рис. 7 показан короткий фрагмент списка символов из этой библиотеки. Первые 23 символа одинаковы для всех имен.

Рис 7: Имена из стандартной библиотеки Ada
Вызывает беспокойство длина строк в обеих схемах трансформации, поскольку когда происходит поиск символа, в сравнении участвует каждая строка. Имена в примере даже не чересчур длинные. Если заглянуть в стандартную библиотеку С++, можно найти много имен длиннее 120 символов, причем это не самые длинные имена. В других системных библиотеках длина названий компонентов превышает 200 символов и они очень сложные, длина имен компонентов в "хорошо спроектированных" проектах C++ с большим количеством пространств имен, шаблонов и вложенных классов может превышать 1000 символов. Это — плюс один балл с точки зрения проектирования и минус сто баллов с точки зрения производительности.
Зная о возможностях хеш-функций и особенностях поиска строк, давайте посмотрим на реальный пример: пакет OpenOffice.org. В пакете содержится 144 отдельных объектов DSO. Во время запуска выполняется около 20000 перемещений. Многие из перемещений осуществляются в результате вызова dlopen и, поэтому, не могут быть существенно оптимизированы с помощью предварительной компоновки [7]. В качестве обоснованного значения нагрузки в момент запуска можно использовать количество сравнений строк, необходимых для разрешения символов. Сейчас мы вычислим это значение.
Средняя длина цепочки при неудачном поиске во всех объектах DSO пакета OpenOffice.org версии 1.0 для IA-32 будет равно 1,1931. Это означает, что при поиске каждого символа динамический компоновщик должен выполнить в среднем 72 × 1,1931 = 85,9032 сравнений строк. Для 20000 символов общая сумма будет составлять 1 718 064 сравнений строк. Средняя длина экспортируемого символа, определяемого в объектах DSO пакета OpenOffice.org, равна 54,13. Даже если мы предположим, что прежде, чем будет найдено несовпадение, будет выполнено только 20% операций поиска строк (что будет оптимистичным предположением, поскольку по крайней мере один раз имя каждого символа полностью сравнивается на совпадение), это должно означать, что, в общей сложности необходимо загрузить из памяти и сравнить более 18,5 миллионов символов. Неудивительно, что запуск происходит так медленно, тем более что мы игнорировали другие затраты.
Чтобы подсчитать количество операций поиска, которые выполняет динамический компоновщик, можно воспользоваться помощью самого динамического компоновщика. Если для переменной окружения LD DEBUG установлено значение symbols, то можно будет подсчитать только количество строк, которые начинаются с symbol=. Лучше всего с помощью переменной LD DEBUG OUTPUT перенаправить выход динамического компоновщика в файл. После это можно, умножив значение счетчика на среднюю длину хэш цепочки, получить количество сравнений. Поскольку в собранных выходных данных содержится имя просмотренного файла, даже можно будет получить более точный результат с помощью умножения на точную длину хэш цепочки объекта.
Изменение любого из следующих факторов - "количество экспортируемых символов", "длина символьных строк", "количество и длина общих префиксов ", "количество объектов DSO" и "оптимизация размера хэш-таблицы" - может резко сократить затраты. В целом, процент времени, затрачиваемый динамическим компоновщиком на перемещения, составляет около 50-70% в случае, если двоичный модуль уже находится в кэше файловой системы, и около 20-30% в случае, если файл должен быть загружен с диска {Примечание 5}. Поэтому стоит потратить время на рассмотрение этого и в оставшейся части статьи мы рассмотрим методы, связанные с этими вопросами. Итак, вспомним: для того, чтобы получить окончательный продукт, передаем компоновщику параметр -O1.
Примечание 5: Предполагается, что в этих значения не учтено время предварительной компоновки.
| Предыдущий раздел: | Следующий раздел: | |
| Назад | Оглавление | Вперед |