





Библиотека сайта rus-linux.net
Обработка больших объемов данных в биоинформатике
Глава 12 из книги "Производительность приложений с открытым исходным кодом".
Оригинал: Working with Big Data in Bioinformatics
Авторы: Eric McDonald, C. Titus Brown
Перевод: А.Панин
Операции со структурой Bloom Filter
Хэш-таблицы структуры Bloom Filter потребляют большую часть основной памяти (обратитесь к Рисунку 12.1) и, следовательно, не могут быть успешно разделены на отдельные копии между потоками. Напротив, единый набор таблиц должен разделяться между всеми потоками. Это обстоятельство подразумевает наличие соперничества между потоками за эти ресурсы. Барьеры доступа к памяти [8] или другая форма блокировок требуется для предотвращения ситуации, когда два или более потоков пытаются получить доступ к одному и тому же адресу памяти в одно и то же время. Мы используем атомарные аддитивные операции для увеличения значений счетчиков в хэш-таблицах. Эти атомарные операции [9] поддерживаются на множестве платформ несколькими наборами компиляторов, причем компиляторы от проекта GNU не являются исключением, и не привязаны к какой-либо определенной схеме реализации потоков или библиотеке. Они устанавливают барьеры доступа к памяти для предназначенных для обновления операндов, добавляя таким образом возможность безопасного использования потоков при выполнении определенной операции.
Проблема с производительностью, на которую мы не обратили внимание, заключается во времени записи данных из хэш-таблиц в хранилище данных после завершения подсчета k-меров. Мы не считали, ее высокоприоритетной, так как время записи является постоянным для структуры Bloom Filter заданного размера и не зависит от объема исходных данных. Для определенного набора данных объемом в 5 ГБ, который мы использовали для тестирования производительности, мы выяснили, что подсчет k-меров занимал более чем в шесть раз больше времени, чем запись данных из хэш-таблиц. Для наборов данных больших объемов соотношение становится более весомым. Ввиду этого, мы были также очень заинтересованы в повышении производительности описанной операции. Одной из возможностей оптимизации являлась амортизация затрат ресурсов на запись данных в ходе фазы подсчета k-меров. Сайт для сокращения строк URL bit.ly использует реализацию структуры Bloom Filter под названием dablooms [10], которая выполняет эту оптимизацию путем отображения в память хэш-таблицы результирующего файла. Применение их идеи вместе с конвейерными обновлениями хэш-таблиц позволило бы нам асинхронно записывать данные в моменты пиковой нагрузки в течение времени жизни процесса и сократить общее время сохранения данных при завершении исполнения приложения. Но наши выходные данные не являются простыми таблицами со счетчиками, а включают также заголовок с некоторыми метаданными; в свете этого обстоятельства, реализация механизма отображения файла в память является задачей, которую нужно решать вдумчиво и осторожно.
Масштабирование
Стоило ли выполнять работу для того, чтобы производительность утилит из состава khmer подвергались масштабированию? Да. Конечно же, мы не достигли идеального линейного увеличения скорости работы. Но при этом на данный момент при каждом удвоении количества ядер центральных процессоров мы наблюдаем ускорение приложения в 1,9 раза.
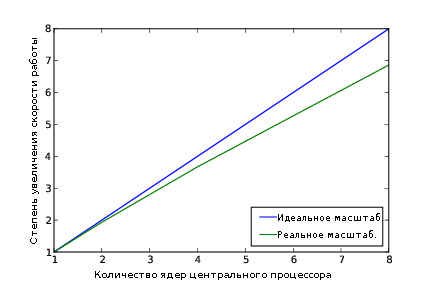
Рисунок 12.4 - Коэффициент ускорения приложения при работе с количеством ядер центральных процессоров в диапазоне от 1 до 8
При разговоре о параллельных вычислениях следует учитывать Закон Амдала [11] и Закон убывающей отдачи. Наиболее часто употребляемая формулировка Закона Амадала в контексте параллельных вычислений выглядит следующим образом:
Использование более быстрых систем хранения данных, таких, как твердотельные накопители (solid-state drives - SSDs) вместо жестких дисков (hard-disk drives - HDDs) позволяет повысить производительность операций ввода/вывода (и, таким образом, уменьшить значение (1-P)), но этот метод оптимизации производительности выходит за рамки оптимизаций программного обеспечения. Хотя мы не можем сделать многого с аппаратным обеспечением, мы все же можем попробовать улучшить значение параметра I. Мы считаем, что имеется возможность дополнительной оптимизации наших методов доступа к разделяемым ресурсам, таким, как память для хранения данных хэш-таблиц, а также что мы можем лучше оптимизировать метод использования объектов состояния каждого из потоков. Выполнение двух этих действий наверняка позволит нам улучшить значение параметра I.
Продолжение статьи: Заключение.