





Библиотека сайта rus-linux.net
Библиотека Warp
Глава 11 из книги "Производительность приложений с открытым исходным кодом".
Оригинал: Warp
Авторы: Kazu Yamamoto, Michael Snoyman, Andreas Voellmy
Перевод: Н.Ромоданов
Парсер HTTP-запроса
Кроме большого количество вопросов, касающихся эффективного распараллеливания и ввода/вывода в многоядерной среде, для библиотеки Warp также нужна уверенность в том, что каждое ядро выполняет свои задачи эффективно. В этой связи наиболее важным компонентом является процессор запросов HTTP. Его задачей является получение потока байтов, поступающих из входного сокета, разбор строки запроса и отдельных заголовков, и передача без изменений тела запроса в приложение для обработки. Он должен принять эту информацию и создать структуру данных, которое приложение (будь то приложение Yesod, сервер mighty или что-то еще) будет использовать для формирования своего ответа.
Само тело запроса заставляет решать некоторые интересные задачи. Warp обеспечивает полную поддержку работы с конвейером и разбиение тела запроса на отдельные фрагменты. В результате Warp должен соединять вместе любые отдельные части тела запроса перед тем, как передавать их в приложение. Благодаря конвейеру через одно подключение может быть передано большое количество запросов. Поэтому Warp должен обеспечить, чтобы приложение не приняло слишком много данных, поскольку в противном случае может быть удалена жизненно важная информация следующего запроса. Также нужно обеспечить, чтобы были удалены все данные, оставшиеся от тела запроса; в противном случае, остаток будет анализироваться как начало следующего запроса, в результате чего будет сформирован недопустимый или непонятный запрос.
В качестве примера, рассмотрим следующий теоретически возможный запрос от клиента:
POST /some/path HTTP/1.1 Transfer-Encoding: chunked Content-Type: application/x-www-form-urlencoded 0008 message= 000a helloworld 0000 GET / HTTP/1.1
Парсер HTTP должен извлечь имя пути /some/path и заголовок Content-Type и передавать их в приложение. Когда приложение начинает читать тело запроса, остатки частей заголовка (например, 0008 и 000a) должны быть убраны и вместо них должно быть представлено фактическое содержимое, то есть message=helloworld. Также нужно обеспечить, чтобы байты, расположенные после завершающим элементом (0000), считываться не будут с тем, чтобы не было влияния на следующий запрос, поступающий по конвейеру.
Пишем парсер
Язык Haskell известен своими мощными возможностями разбора. В нем есть генераторы традиционных анализаторов, а также библиотеки, как, например, Parsec и Attoparsec. Модули текстовой обработки, имеющиеся в Parsec и Attoparsec, работают в режиме, полностью совместимом с Unicode. Однако, гарантировано, что заголовки HTTP должны быть в коде ASCII, так осведомленность о том, что допустим Unicode, излишняя и нам она не требуется.
В Attoparsec также предоставляется двоичный интерфейс, предназначенный для парсинга данных, который мог бы позволить избежать накладных расходов, связанных с Unicode. Но та эффективность, которая реализована в Attoparsec, по-прежнему требует больших накладных расходов чет та, что возможна в парсере, который создан вручную. Поэтому в Warp мы не пользовались никакими библиотеками анализаторов. Вместо этого, мы выполняем весь разбор вручную.
В результате встает еще один вопрос: каким образом мы должны представлять фактически используемые двоичные данные? Ответом будет тип ByteString, который, по существу, состоит из трех частей: указателя на некоторый фрагмент памяти, смещения от начала этой памяти данных, о которых идет речь, и размера наших данных.
Информация о смещении может показаться излишней. Мы могли бы настаивать, чтобы указатель нашей памяти указывал вместо этого на начало самих данных. Тем не менее, за счет добавления смещения, у нас появляется возможность совместного использования данных несколькими процессами. Несколько строк ByteString могут все указывать на один и тот же самый фрагмент памяти и пользоваться его различными частями (что также известно как сплайсинг или расслоение данных). Не требуется беспокоиться о повреждении данных, т.к. строки ByteString точно также, как и большинство данных языка Haskell, не мутируемые. После того, как перестанет использоваться последний указатель на эту область памяти, буфер памяти будет освобожден.
Такое сочетание идеально подходит для нашего случая. Когда клиент отправляет запрос через сокет, Warp будет читать данные относительно большими кусками (в настоящее время 4096 байт). В большинстве случаев, этого достаточно, чтобы вместить всю строку запроса и все его заголовки. Затем Warp будет использовать свой собственный сделанный вручную парсер для того, чтобы разделить этот большой кусок данных на строки. Это можно сделать эффективно по следующим причинам:
- Нам в буфере памяти нужно найти только символы новой строки. В библиотеке, работающей с байтовыми строкам, предлагаются такие вспомогательные функции, которые реализованы при помощи низкоуровневых функций языка C, например,
memchr. (На самом деле, это немного сложнее из-за того, что заголовки состоят из нескольких строк, но тот же самый базовый принцип все еще применим). - Для хранения данных не нужно выделять дополнительные буферы памяти. Мы просто выполняем сплайсинг первоначального буфера. На рис.11.9 продемонстрирован сплайсинг отдельных компонентов в большом куске данных. Нужно обратить внимание на следующий момент: мы, на самом деле, имеем в конечном итоге ситуацию, которая более эффективна, чем идиоматичный язык С. В языке C, строки заканчиваются символом null, поэтому при сплайсинге потребуется выделять новый буфер памяти, копировать данные из старого буфера и добавлять символ null.
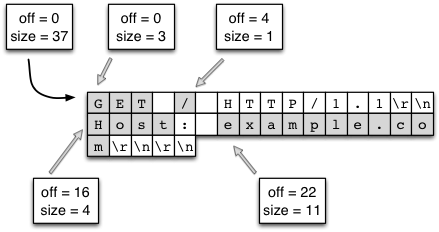
Рис.11.9: Сплайсинг строк ByteString
Как только буфер разбивается на строки, мы для того, чтобы превратить строки в пары ключ/значение, выполняем аналогичный маневр. Для строки запроса, мы анализируем запрашиваемый путь довольно глубоко. Предположим, у нас есть следующий запрос:
GET /buenos/d%C3%ADas HTTP/1.1
В этом случае нам необходимо было бы выполнить следующие действия:
- Разделить на отдельные части метод запроса, путь и версию.
- Разбить путь вместе с прямой косой чертой на отдельные лексемы, что в конечном итоге превратилось бы в ["
buenos", "d%C3%ADas"]. - Декодировать отдельные части, имеющие процент, что в конечном итоге превратилось бы в ["
buenos", "d\195\173as"]. - Выполнить UTF8-декодирование каждого куска и, наконец, получить Unicode-текст: ["
buenos", "días"].
В этом процессе мы достигаем повышения производительности за счет следующего:
- Как и проверка символа новой строки, поиск прямой косой черты является очень эффективной операцией.
- Для превращения шестнадцатеричных символов в числовые значения мы используем эффективную поисковую таблицу. В этот коде выполняется однопроходный поиск в памяти, не требующий ветвлений.
- UTF8-декодирование является очень хорошо оптимизированной операцией в текстовом пакете. Кроме того, в текстом пакете такие данные представлены в эффективном упакованном виде.
- Из-за «ленивого выполнения» операций в языке Haskell, такое вычисление будет выполняться только по требованию. Если приложению не потребуется текстовое представление пути, то ни один из этих шагов выполнен не будет.
Заключительной частью разбора, который мы выполняем, является конечная сборка лексем. Во многих отношениях, эта операция является простейшей формой анализа. Мы анализируем отдельное шестнадцатеричное число, а затем читаем указанное количество байтов. Эти байты непосредственно передаются в приложение (без какого-либо копирования в буфер).
Пакет conduit
В этой статье уже несколько раз упоминался принцип прохождения тела запроса в приложение. Также говорилось, что приложение передает ответ обратно на сервер, а сервер, получающий данные, получает и отправляет их через сокет. Последнее, что не обсуждалось, это промежуточное ПО (или средний слой — прим.пер.), которое состоит из компонентов, находящихся между сервером и приложением и изменяющих запрос или ответ. Определение промежуточного слоя следующее:
type Middleware = Application -> Application
Если интуитивно, то промежуточный слой будет представлять собой некоторое «внутреннее» приложение, выполняющее предварительную обработку запроса, передаваемого во внутреннее приложение с тем, чтобы получить от него ответ, а затем выполнить постобработку ответа. Для наших целей хорошим примером будет промежуточное ПО архиватора gzip, который автоматически сжимает тело ответа.
Предпосылкой создания таких промежуточных слоев является необходимость изменений как входящих, так и исходящих потоков данных. Исторически в мире Haskell стандартным подходом был ленивый ввод/вывод (lazy I/O) В случае ленивого ввода/вывода мы рассматриваем поток значений в виде одной ясной структуры данных. Поскольку большая часть данных запрашивается из этой структуры, то операции ввода/вывода выполняются для того, чтобы получить данные из этого источника данных. Ленивый ввод/вывода позволяет достичь высокого уровня составления различных композиций. Нодля сервера с высокой пропускной способностью, такой ввод/вывод представляет собой основное препятствие: финализация ресурса при ленивом вводе/выводе недетерминирована. Сервера, находящемуся под высокой нагрузкой, для того, чтобы использовать ленивый ввод/вывод, нужно быстро обрабатывать файловые дескрипторы.
Также можно было бы использовать абстракцию более низкого уровня, по существу, имеющую дело непосредственно с функциями чтения и записи. Но одно из преимуществ языка Haskell состоит в его высокоуровневом подходе, позволяющим нам рассматривать поведении нашего кода. Также неясно, как подобное решение коснется некоторых общих проблем, возникающих при создании веб-приложений. Например, часто нужно иметь буфер, откуда мы за один шаг читаем определенное количество данных (например, обрабатывая заголовок запроса), а оставшуюся часть данных читаем из буфера с помощью другого фрагмента кода (например, веб-приложения).
Чтобы решить этой дилемму, протокол WAI (и, следовательно Warp) создавались на основе пакета conduit. В этом пакете предлагается абстракция потоков данных. В нем поддерживается большинство композиционных возможностей ленивого ввода/вывода, обеспечивается буферизация решения и гарантируется детерминированность обработки ресурсов. В тех частях вашего кода, который выполняет ввод/вывод, поддерживаются исключения, когда они уместны, вместо того, чтобы упрятывать в структуру данных, объявляемой идеальной.
В Warp входящий поток байтов, поступающий от клиента, представлен в виде источника данных Source, а запись данных, отправляемых клиенту, происходит в объект Sink. Приложение Application получает источник данных Source с телом запроса и выдает ответ точно также в виде источника Source. Промежуточные слои также могут перехватывать различные источники данных Source в теле запросов и применять к ним преобразования. На рис.11.10 показано, как промежуточный слой встраивается между Warp и приложением. Возможность составлять различные композиции, имеющаяся в пакете conduit, позволяет легко и эффективно выполнять эту операцию.
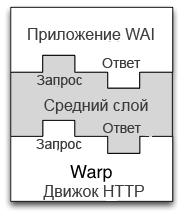
Рис.11.10:Промежуточный слой
При разработке примера с gzip в промежуточном слое пакет conduit позволяет создать промежуточный слой, который работает почти оптимальным образом. Исходный источник данных Source, предоставляемый приложением, подключен к gzip Conduit. Поскольку каждая новая порция данных поступает от исходного источника данных Source, она поступает в библиотеку zlib, заполняя буфер сжатыми байтам. Когда этот буфер будет заполнен, его содержимое будет переслано либо в другой промежуточный слой, либо в Warp. Затем Warp берет этот сжатый буфер и отправляет его через сокет к клиенту. В этот момент буфер может либо использоваться повторно, либо его память можно освободить. Таким образом, мы используем память оптимальным образом, не создаем в случае сбоя в сети никаких дополнительных данных и уменьшаем нагрузку по сбору мусора в системе времени выполнения.
Сам пакет conduit является большой темой и поэтому он не будет рассматриваться более подробно. Достаточно сказать, что на данный момент использование этого пакета в Warp является фактором, способствующим высокой производительности.
Защита от атак Slowloris
У нас есть одна заключительная проблема: атаки вида Slowloris. Это вариант атак отказа в обслуживании (Denial of Service - DoS), где каждый клиент посылает очень небольшой объем информации. Поступая таким образом, клиент имеет возможность на том же самом аппаратном обеспечении и при той же самой пропускной способности поддерживать большее количество соединений. Поскольку для каждого открытого подключения нагрузка на веб-сервер увеличивается на одну и ту же постоянную величину независимо от количества переданных байтов, то такая атака может быть эффективной. Поэтому в Warp нужно определять, когда при сетевом подключении посылается недостаточное количество данных, и нужно удалять такие подключения.
Менеджер тайм-аутов, который является истинным сердцем защиты от атак Slowloris, мы более подробно будем рассматривать ниже. Когда дело доходит до обработки запроса, нашим единственным требованием является обращение к обработчику тайм-аута с целью больше узнать о данных, которые были получены от клиента. В Warp все это делается на уровне промежуточного слоя conduit. Как уже упоминалось, входящие данные представлены в качестве источника Source. Когда используется источник Source, то каждый раз, когда поступает новая порция данных, включается обработчик тайм-аута. Поскольку включение этого обработчика является совсем недорогой операцией (по существу, только запись в память), то защита от атак вида Slowloris не оказывается существенного влияния на производительность отдельных обработчиков подключений.
Продолжение статьи: Композер HTTP-ответа.