





Библиотека сайта rus-linux.net
Разбор документов XML со скоростью света
Глава 4 из книги "Производительность приложений с открытым исходным кодом".
Оригинал: Parsing XML at the Speed of Light
Автор: Arseny Kapoulkine
Перевод: А.Панин
Структуры данных для объектной модели документа
Документ XML имеет древовидную структуру. Он содержит один или несколько узлов; каждый узел может содержать также один или несколько узлов; узлы могут представлять различные типы данных XML, такие, как элементы или текст; узлы элементов также могут содержать один или несколько атрибутов.
При реализации каждого из представлений данных узла обычно сталкиваются компромиссом между потреблением памяти и производительностью различных операций. Например, семантически узел содержит коллекцию дочерних узлов; эта коллекция может быть представлена в структуре данных. По отдельности эти данные могут храниться в форме массива или связанного списка. Представление в форме массива позволит осуществлять быстрый доступ к элементам на основе индексов; представление в форме связанного списка позволит осуществлять вставки и удаления элементов в течение равных интервалов времени.13
Библиотека pugixml представляет и узлы, и коллекции атрибутов в форме связанных списков. Почему не в форме массивов? Двумя главными преимуществами массивов являются быстрый доступ к элементам на основе индексов (который не особенно важен в случае библиотеки pugixml) и компактное расположение элементов в памяти (которое может быть достигнуто с помощью других средств).
Быстрый доступ к элементам на основе индексов обычно не является необходимым, так как коду, с помощью которого производится обработка дерева документа XML, приходится либо обходить все дочерние узлы, либо извлекать специфический узел, который идентифицируется значением атрибута (т.е., "получать дочерний узел со значением атрибута 'id', эквивалентным 'X'").14 Доступ на основе индексов также не является надежным решением при работе с изменяемым документом XML: например, добавление комментариев XML изменит индексы последующих узлов в том же поддереве.
Компактное расположение в памяти зависит от алгоритма резервирования памяти. При использовании подходящего алгоритма связанные списки могут быть эффективными настолько же, насколько эффективны массивы, при условии того, что память для хранения узлов в списке будет резервироваться последовательно. (Подробнее об этом будет написано ниже).
struct Node {
Node* children;
size_t children_size;
size_t children_capacity;
};
struct Node {
Node* first_child;
Node* last_child;
Node* prev_sibling;
Node* next_sibling;
};
Здесь указатель last_child необходим для поддержки обратной итерации и реализации алгоритма добавления элементов с коэффициентом масштабирования 0(1).
Следует отметить, что при использовании данной архитектуры достаточно просто осуществлять поддержку различных типов узлов для сокращения потребления памяти; например, узлу элемента требуется список атрибутов, но при этом текстовому узлу такой список не требуется. Подход с использованием массива заставляет использовать для всех типов узлов структуры одинакового размера, что делает невозможным проведение данной эффективной оптимизации.
Библиотека pugixml реализует подход с использованием связанных списков. Из-за этого коэффициент масштабирования алгоритма модификации узлов всегда равен 0(1). Более того, подход с использованием массива принудил бы нас к резервированию блоков памяти различных размеров, начиная с десятков байт и заканчивая мегабайтами в случае обработки отдельного узла со множеством дочерних узлов; в то же время при подходе с использованием связанных списков существует только несколько различных размеров структур узлов для резервирования. Проектирование быстрой системы резервирования памяти для резервирования блоков фиксированных размеров обычно проще проектирования быстрой системы резервирования памяти для резервирования блоков памяти произвольных размеров, что является еще одной причиной выбора этой стратегии при разработке pugixml.
last_child, но алгоритм доступа к последнему дочернему узлу все так же характеризуется коэффициентом масштабирования 0(1) из-за того, что список дочерних элементов становится частично циклическим благодаря указателю prev_sibling_cyclic:
struct Node {
Node* first_child;
Node* prev_sibling_cyclic;
Node* next_sibling;
};
first_childуказывает на первый дочерний узел текущего узла или имеет значениеNULLв случае, когда у текущего узла нет дочерних узлов.prev_sibling_cyclicуказывает на дочерний узел расположенного по соседству слева от текущего узла родительского узла (дочерний узел родительского узла, находящегося прямо перед текущим узлом в документе). В том случае если текущий узел расположен слева от всех других (т.е., если узел является первым дочерним узлом для родительского),prev_sibling_cyclicуказывает на последний дочерний узел родительского узла или на самого себя, если узел является единственным дочерним. Указательprev_sibling_cyclicне может иметь значениеNULL.next_siblingуказывает на правый дочерний узел для текущего узла, либо его значение равноNULLв том случае, когда узел является последним дочерним узлом своего родительского узла.
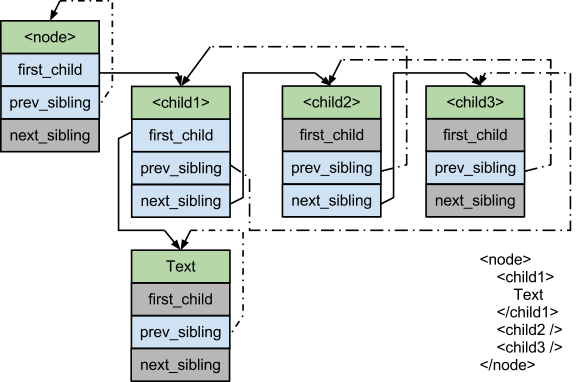
Рисунок 4.4 - Пример поддерева, представленного с использованием частично циклических связанных списков
Node* last_child(Node* node) {
return (node->first_child) ?
node->first_child->prev_sibling_cyclic : NULL;
}
Node* prev_sibling(Node* node) {
return (/node->prev_sibling_cyclic->next_sibling) ?
node->prev_sibling_cyclic : NULL;
}
Подход с использованием массива и подход с использованием связанного списка с применением техники частично циклического списка дочерних узлов становятся эквивалентными в плане потребления памяти. Использование 32-битных типов с целью сокращения размера структур позволяет использовать меньшие по размеру структуры данных узлов в массивах на 64-битных системах.16 В случае библиотеки pugixml другие достоинства связанных списков были более существенными, чем затраты на реализацию.
После рассмотрения структур данных самое время поговорить о последнем элементе головоломки - алгоритме резервирования памяти.
Продолжение статьи: Метод резервирования памяти на основе стека.