





Библиотека сайта rus-linux.net
|
|
|

|
Linux Device Drivers, 2nd EditionBy Alessandro Rubini & Jonathan Corbet2nd Edition June 2001 0-59600-008-1, Order Number: 0081 586 pages, $39.95 |
Chapter 10
Judicious Use of Data TypesContents:
Use of Standard C Types
Assigning an Explicit Size to Data Items
Interface-Specific Types
Other Portability Issues
Linked Lists
Quick ReferenceBefore we go on to more advanced topics, we need to stop for a quick note on portability issues. Modern versions of the Linux kernel are highly portable, running on several very different architectures. Given the multiplatform nature of Linux, drivers intended for serious use should be portable as well.
Use of Standard C Types
Although most programmers are accustomed to freely using standard types like
intandlong, writing device drivers requires some care to avoid typing conflicts and obscure bugs.morgana% misc-progs/datasize arch Size: char shor int long ptr long-long u8 u16 u32 u64 i686 1 2 4 4 4 8 1 2 4 8arch Size: char shor int long ptr long-long u8 u16 u32 u64 i386 1 2 4 4 4 8 1 2 4 8 alpha 1 2 4 8 8 8 1 2 4 8 armv4l 1 2 4 4 4 8 1 2 4 8 ia64 1 2 4 8 8 8 1 2 4 8 m68k 1 2 4 4 4 8 1 2 4 8 mips 1 2 4 4 4 8 1 2 4 8 ppc 1 2 4 4 4 8 1 2 4 8 sparc 1 2 4 4 4 8 1 2 4 8 sparc64 1 2 4 4 4 8 1 2 4 8kernel: arch Size: char short int long ptr long-long u8 u16 u32 u64 kernel: sparc64 1 2 4 8 8 8 1 2 4 8Although you must be careful when mixing different data types, sometimes there are good reasons to do so. One such situation is for memory addresses, which are special as far as the kernel is concerned. Although conceptually addresses are pointers, memory administration is better accomplished by using an unsigned integer type; the kernel treats physical memory like a huge array, and a memory address is just an index into the array. Furthermore, a pointer is easily dereferenced; when dealing directly with memory addresses you almost never want to dereference them in this manner. Using an integer type prevents this dereferencing, thus avoiding bugs. Therefore, addresses in the kernel are
unsigned long, exploiting the fact that pointers andlongintegers are always the same size, at least on all the platforms currently supported by Linux.The C99 standard defines the
intptr_tanduintptr_ttypes for an integer variable which can hold a pointer value. These types are almost unused in the 2.4 kernel, but it would not be surprising to see them show up more often as a result of future development work.Assigning an Explicit Size to Data Items
Sometimes kernel code requires data items of a specific size, either to match predefined binary structures[39] or to align data within structures by inserting "filler'' fields (but please refer to "Data Alignment" later in this chapter for information about alignment issues).
The kernel offers the following data types to use whenever you need to know the size of your data. All the types are declared in
<asm/types.h>, which in turn is included by<linux/types.h>:u8; /* unsigned byte (8 bits) */ u16; /* unsigned word (16 bits) */ u32; /* unsigned 32-bit value */ u64; /* unsigned 64-bit value */These data types are accessible only from kernel code (i.e.,
__KERNEL__must be defined before including<linux/types.h>). The corresponding signed types exist, but are rarely needed; just replaceuwithsin the name if you need them.Interface-Specific Types
Most of the commonly used data types in the kernel have their own
typedefstatements, thus preventing any portability problems. For example, a process identifier (pid) is usuallypid_tinstead ofint. Usingpid_tmasks any possible difference in the actual data typing. We use the expression interface-specific to refer to a type defined by a library in order to provide an interface to a specific data structure.The one ambiguous point we've found in the kernel headers is data typing for I/O functions, which is loosely defined (see the section "Platform Dependencies" in Chapter 8, "Hardware Management"). The loose typing is mainly there for historical reasons, but it can create problems when writing code. For example, one can get into trouble by swapping the arguments to functions like outb; if there were a
port_ttype, the compiler would find this type of error.Other Portability Issues
Time Intervals
When dealing with time intervals, don't assume that there are 100 jiffies per second. Although this is currently true for Linux-x86, not every Linux platform runs at 100 Hz (as of 2.4 you find values ranging from 20 to 1200, although 20 is only used in the IA-64 simulator). The assumption can be false even for the x86 if you play with the
HZvalue (as some people do), and nobody knows what will happen in future kernels. Whenever you calculate time intervals using jiffies, scale your times usingHZ(the number of timer interrupts per second). For example, to check against a timeout of half a second, compare the elapsed time againstHZ/2. More generally, the number of jiffies corresponding tomsecmilliseconds is alwaysmsec*HZ/1000. This detail had to be fixed in many network drivers when porting them to the Alpha; some of them didn't work on that platform because they assumedHZto be 100.Page Size
When playing games with memory, remember that a memory page is
PAGE_SIZEbytes, not 4 KB. Assuming that the page size is 4 KB and hard-coding the value is a common error among PC programmers -- instead, supported platforms show page sizes from 4 KB to 64 KB, and sometimes they differ between different implementations of the same platform. The relevant macros arePAGE_SIZEandPAGE_SHIFT. The latter contains the number of bits to shift an address to get its page number. The number currently is 12 or greater, for 4 KB and bigger pages. The macros are defined in<asm/page.h>; user-space programs can use getpagesize if they ever need the information.int order = (14 - PAGE_SHIFT > 0) ? 14 - PAGE_SHIFT : 0; buf = get_free_pages(GFP_KERNEL, order);Byte Order
Be careful not to make assumptions about byte ordering. Whereas the PC stores multibyte values low-byte first (little end first, thus little-endian), most high-level platforms work the other way (big-endian). Modern processors can operate in either mode, but most of them prefer to work in big-endian mode; support for little-endian memory access has been added to interoperate with PC data and Linux usually prefers to run in the native processor mode. Whenever possible, your code should be written such that it does not care about byte ordering in the data it manipulates. However, sometimes a driver needs to build an integer number out of single bytes or do the opposite.
You'll need to deal with endianness when you fill in network packet headers, for example, or when you are dealing with a peripheral that operates in a specific byte ordering mode. In that case, the code should include
<asm/byteorder.h>and should check whether__BIG_ENDIANor__LITTLE_ENDIANis defined by the header.You could code a bunch of
#ifdef __LITTLE_ENDIANconditionals, but there is a better way. The Linux kernel defines a set of macros that handle conversions between the processor's byte ordering and that of the data you need to store or load in a specific byte order. For example:u32 __cpu_to_le32 (u32); u32 __le32_to_cpu (u32);Data Alignment
The last problem worth considering when writing portable code is how to access unaligned data -- for example, how to read a four-byte value stored at an address that isn't a multiple of four bytes. PC users often access unaligned data items, but few architectures permit it. Most modern architectures generate an exception every time the program tries unaligned data transfers; data transfer is handled by the exception handler, with a great performance penalty. If you need to access unaligned data, you should use the following macros:
#include <asm/unaligned.h> get_unaligned(ptr); put_unaligned(val, ptr);To show how alignment is enforced by the compiler, the dataalign program is distributed in the misc-progs directory of the sample code, and an equivalent kdataalign module is part of misc-modules. This is the output of the program on several platforms and the output of the module on the SPARC64:
arch Align: char short int long ptr long-long u8 u16 u32 u64 i386 1 2 4 4 4 4 1 2 4 4 i686 1 2 4 4 4 4 1 2 4 4 alpha 1 2 4 8 8 8 1 2 4 8 armv4l 1 2 4 4 4 4 1 2 4 4 ia64 1 2 4 8 8 8 1 2 4 8 mips 1 2 4 4 4 8 1 2 4 8 ppc 1 2 4 4 4 8 1 2 4 8 sparc 1 2 4 4 4 8 1 2 4 8 sparc64 1 2 4 4 4 8 1 2 4 8 kernel: arch Align: char short int long ptr long-long u8 u16 u32 u64 kernel: sparc64 1 2 4 8 8 8 1 2 4 8Linked Lists
Operating system kernels, like many other programs, often need to maintain lists of data structures. The Linux kernel has, at times, been host to several linked list implementations at the same time. To reduce the amount of duplicated code, the kernel developers have created a standard implementation of circular, doubly-linked lists; others needing to manipulate lists are encouraged to use this facility, introduced in version 2.1.45 of the kernel.
To use the list mechanism, your driver must include the file
<linux/list.h>. This file defines a simple structure of typelist_head:struct list_head { struct list_head *next, *prev; };struct todo_struct { struct list_head list; int priority; /* driver specific */ /* ... add other driver-specific fields */ };struct list_head todo_list; INIT_LIST_HEAD(&todo_list);Alternatively, lists can be initialized at compile time as follows:
LIST_HEAD(todo_list);Several functions are defined in
<linux/list.h>that work with lists:
list_add(struct list_head *new, struct list_head *head);
list_add_tail(struct list_head *new, struct list_head *head);
list_del(struct list_head *entry);
list_empty(struct list_head *head);
list_splice(struct list_head *list, struct list_head *head);This function joins two lists by inserting
listimmediately afterhead.
list_entry(struct list_head *ptr, type_of_struct, field_name);struct todo_struct *todo_ptr = list_entry(listptr, struct todo_struct, list);The list_entry macro takes a little getting used to, but is not that hard to use.
void todo_add_entry(struct todo_struct *new) { struct list_head *ptr; struct todo_struct *entry; for (ptr = todo_list.next; ptr != &todo_list; ptr = ptr->next) { entry = list_entry(ptr, struct todo_struct, list); if (entry->priority < new->priority) { list_add_tail(&new->list, ptr); return; } } list_add_tail(&new->list, &todo_struct) }Figure 10-1 shows how the simple
struct list_headis used to maintain a list of data structures.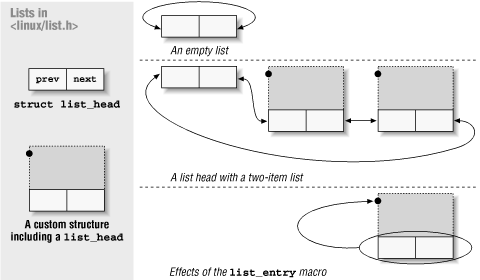
Figure 10-1. The list_head data structure
Although not all features exported by the list.has it appears in Linux 2.4 are available with older kernels, our sysdep.h fills the gap by declaring all macros and functions for use in older kernels.
Quick Reference
The following symbols were introduced in this chapter.
#include <linux/types.h>typedef u8;typedef u16;typedef u32;typedef u64;These types are guaranteed to be 8-, 16-, 32-, and 64-bit unsigned integer values. The equivalent signed types exist as well. In user space, you can refer to the types as
__u8,__u16, and so forth.
#include <asm/page.h>PAGE_SIZEPAGE_SHIFTThese symbols define the number of bytes per page for the current architecture and the number of bits in the page offset (12 for 4-KB pages and 13 for 8-KB pages).
#include <asm/byteorder.h>__LITTLE_ENDIAN__BIG_ENDIANOnly one of the two symbols is defined, depending on the architecture.
#include <asm/byteorder.h>u32 __cpu_to_le32 (u32);u32 __le32_to_cpu (u32);Functions for converting between known byte orders and that of the processor. There are more than 60 such functions; see the various files in include/linux/byteorder/ for a full list and the ways in which they are defined.
#include <asm/unaligned.h>get_unaligned(ptr);put_unaligned(val, ptr);Some architectures need to protect unaligned data access using these macros. The macros expand to normal pointer dereferencing for architectures that permit you to access unaligned data.
#include <linux/list.h>list_add(struct list_head *new, struct list_head *head);list_add_tail(struct list_head *new, struct list_head *head);list_del(struct list_head *entry);list_empty(struct list_head *head);list_entry(entry, type, member);list_splice(struct list_head *list, struct list_head *head);

|
|

|
Back to: Linux Device Drivers, 2nd Edition
oreilly.com Home | O'Reilly Bookstores | How to Order | O'Reilly Contacts
International | About O'Reilly | Affiliated Companies | Privacy Policy
╘ 2001, O'Reilly & Associates, Inc.