





Библиотека сайта rus-linux.net
|
|
|

|
Linux Device Drivers, 2nd EditionBy Alessandro Rubini & Jonathan Corbet2nd Edition June 2001 0-59600-008-1, Order Number: 0081 586 pages, $39.95 |
Chapter 8
Hardware ManagementContents:
I/O Ports and I/O Memory
Using I/O Ports
Using Digital I/O Ports
Using I/O Memory
Backward Compatibility
Quick ReferenceWe chose simple digital I/O because it is the easiest form of input/output port. Also, the Centronics parallel port implements raw I/O and is available in most computers: data bits written to the device appear on the output pins, and voltage levels on the input pins are directly accessible by the processor. In practice, you have to connect LEDs to the port to actually see the results of a digital I/O operation, but the underlying hardware is extremely easy to use.
I/O Ports and I/O Memory
Every peripheral device is controlled by writing and reading its registers. Most of the time a device has several registers, and they are accessed at consecutive addresses, either in the memory address space or in the I/O address space.
I/O Registers and Conventional Memory
Despite the strong similarity between hardware registers and memory, a programmer accessing I/O registers must be careful to avoid being tricked by CPU (or compiler) optimizations that can modify the expected I/O behavior.
The problem with hardware caching is the easiest to face: the underlying hardware is already configured (either automatically or by Linux initialization code) to disable any hardware cache when accessing I/O regions (whether they are memory or port regions).
#include <linux/kernel.h>void barrier(void)This function tells the compiler to insert a memory barrier, but has no effect on the hardware. Compiled code will store to memory all values that are currently modified and resident in CPU registers, and will reread them later when they are needed.
#include <asm/system.h>void rmb(void);void wmb(void);void mb(void);These functions insert hardware memory barriers in the compiled instruction flow; their actual instantiation is platform dependent. An rmb (read memory barrier) guarantees that any reads appearing before the barrier are completed prior to the execution of any subsequent read. wmb guarantees ordering in write operations, and the mbinstruction guarantees both. Each of these functions is a superset of barrier.
A typical usage of memory barriers in a device driver may have this sort of form:
writel(dev->registers.addr, io_destination_address); writel(dev->registers.size, io_size); writel(dev->registers.operation, DEV_READ); wmb(); writel(dev->registers.control, DEV_GO);Because memory barriers affect performance, they should only be used where really needed. The different types of barriers can also have different performance characteristics, so it is worthwhile to use the most specific type possible. For example, on the x86 architecture, wmb() currently does nothing, since writes outside the processor are not reordered. Reads are reordered, however, so mb() will be slower than wmb().
Some architectures allow the efficient combination of an assignment and a memory barrier. Version 2.4 of the kernel provides a few macros that perform this combination; in the default case they are defined as follows:
#define set_mb(var, value) do {var = value; mb();} while 0 #define set_wmb(var, value) do {var = value; wmb();} while 0 #define set_rmb(var, value) do {var = value; rmb();} while 0The header file sysdep.h defines macros described in this section for the platforms and the kernel versions that lack them.
Using I/O Ports
I/O ports are the means by which drivers communicate with many devices out there -- at least part of the time. This section covers the various functions available for making use of I/O ports; we also touch on some portability issues.
Let us start with a quick reminder that I/O ports must be allocated before being used by your driver. As we discussed in "I/O Ports and I/O Memory" in Chapter 2, "Building and Running Modules", the functions used to allocate and free ports are:
#include <linux/ioport.h> int check_region(unsigned long start, unsigned long len); struct resource *request_region(unsigned long start, unsigned long len, char *name); void release_region(unsigned long start, unsigned long len);After a driver has requested the range of I/O ports it needs to use in its activities, it must read and/or write to those ports. To this aim, most hardware differentiates between 8-bit, 16-bit, and 32-bit ports. Usually you can't mix them like you normally do with system memory access.[32]
A C program, therefore, must call different functions to access different size ports. As suggested in the previous section, computer architectures that support only memory-mapped I/O registers fake port I/O by remapping port addresses to memory addresses, and the kernel hides the details from the driver in order to ease portability. The Linux kernel headers (specifically, the architecture-dependent header
<asm/io.h>) define the following inline functions to access I/O ports.NOTE: From now on, when we useunsignedwithout further type specifications, we are referring to an architecture-dependent definition whose exact nature is not relevant. The functions are almost always portable because the compiler automatically casts the values during assignment -- their being unsigned helps prevent compile-time warnings. No information is lost with such casts as long as the programmer assigns sensible values to avoid overflow. We'll stick to this convention of "incomplete typing'' for the rest of the chapter.
unsigned inb(unsigned port);void outb(unsigned char byte, unsigned port);Read or write byte ports (eight bits wide). The
portargument is defined asunsigned longfor some platforms andunsigned shortfor others. The return type of inb is also different across architectures.
unsigned inw(unsigned port);void outw(unsigned short word, unsigned port);These functions access 16-bit ports (word wide); they are not available when compiling for the M68k and S390 platforms, which support only byte I/O.
unsigned inl(unsigned port);void outl(unsigned longword, unsigned port);These functions access 32-bit ports.
longwordis either declared asunsigned longorunsigned int, according to the platform. Like word I/O, "long'' I/O is not available on M68k and S390.
The program must be compiled with the -O option to force expansion of inline functions.
The ioperm or iopl system calls must be used to get permission to perform I/O operations on ports. ioperm gets permission for individual ports, while iopl gets permission for the entire I/O space. Both these functions are Intel specific.
String Operations
In addition to the single-shot in and out operations, some processors implement special instructions to transfer a sequence of bytes, words, or longs to and from a single I/O port or the same size. These are the so-called string instructions, and they perform the task more quickly than a C-language loop can do. The following macros implement the concept of string I/O by either using a single machine instruction or by executing a tight loop if the target processor has no instruction that performs string I/O. The macros are not defined at all when compiling for the M68k and S390 platforms. This should not be a portability problem, since these platforms don't usually share device drivers with other platforms, because their peripheral buses are different.
The prototypes for string functions are the following:
void insb(unsigned port, void *addr, unsigned long count);void outsb(unsigned port, void *addr, unsigned long count);Read or write
countbytes starting at the memory addressaddr. Data is read from or written to the single portport.
void insw(unsigned port, void *addr, unsigned long count);void outsw(unsigned port, void *addr, unsigned long count);
void insl(unsigned port, void *addr, unsigned long count);void outsl(unsigned port, void *addr, unsigned long count);
Pausing I/O
Some platforms -- most notably the i386 -- can have problems when the processor tries to transfer data too quickly to or from the bus. The problems can arise because the processor is overclocked with respect to the ISA bus, and can show up when the device board is too slow. The solution is to insert a small delay after each I/O instruction if another such instruction follows. If your device misses some data, or if you fear it might miss some, you can use pausing functions in place of the normal ones. The pausing functions are exactly like those listed previously, but their names end in
_p; they are called inb_p, outb_p, and so on. The functions are defined for most supported architectures, although they often expand to the same code as nonpausing I/O, because there is no need for the extra pause if the architecture runs with a nonobsolete peripheral bus.Platform Dependencies
I/O instructions are, by their nature, highly processor dependent. Because they work with the details of how the processor handles moving data in and out, it is very hard to hide the differences between systems. As a consequence, much of the source code related to port I/O is platform dependent.
- IA-32 (x86)
- IA-64 (Itanium)
- Alpha
- ARM
- M68k
- MIPS
- MIPS64
- PowerPC
All the functions are supported; ports have type
unsigned char *.
- S390
- Super-H
Ports are
unsigned int(memory-mapped), and all the functions are supported.
- SPARC
- SPARC64
How I/O operations are performed on each platform is well described in the programmer's manual for each platform; those manuals are usually available for download as PDF files on the Web.
Using Digital I/O Ports
The sample code we use to show port I/O from within a device driver acts on general-purpose digital I/O ports; such ports are found in most computer systems.
A digital I/O port, in its most common incarnation, is a byte-wide I/O location, either memory-mapped or port-mapped. When you write a value to an output location, the electrical signal seen on output pins is changed according to the individual bits being written. When you read a value from the input location, the current logic level seen on input pins is returned as individual bit values.
An Overview of the Parallel Port
Because we expect most readers to be using an x86 platform in the form called "personal computer,'' we feel it is worth explaining how the PC parallel port is designed. The parallel port is the peripheral interface of choice for running digital I/O sample code on a personal computer. Although most readers probably have parallel port specifications available, we summarize them here for your convenience.
The signal levels used in parallel communications are standard transistor-transistor logic (TTL) levels: 0 and 5 volts, with the logic threshold at about 1.2 volts; you can count on the ports at least meeting the standard TTL LS current ratings, although most modern parallel ports do better in both current and voltage ratings.
WARNING: The parallel connector is not isolated from the computer's internal circuitry, which is useful if you want to connect logic gates directly to the port. But you have to be careful to do the wiring correctly; the parallel port circuitry is easily damaged when you play with your own custom circuitry unless you add optoisolators to your circuit. You can choose to use plug-in parallel ports if you fear you'll damage your motherboard.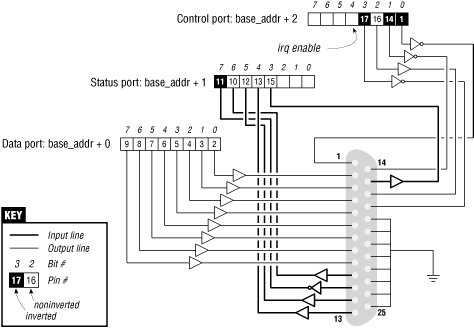
Figure 8-1. The pinout of the parallel port
A Sample Driver
To watch what happens on the parallel connector, and if you have a bit of an inclination to work with hardware, you can solder a few LEDs to the output pins. Each LED should be connected in series to a 1-K resistor leading to a ground pin (unless, of course, your LEDs have the resistor built in). If you connect an output pin to an input pin, you'll generate your own input to be read from the input ports.
while (count--) { outb(*(ptr++), address); wmb(); }You can run the following command to light your LEDs:
echo -n "any string" > /dev/short0dd if=/dev/short0 bs=1 count=1 | od -t x1The short driver performs an absolute minimum of hardware control, but is adequate to show how the I/O port instructions are used. Interested readers may want to look at the source for the parport and parport_pc modules to see how complicated this device can get in real life in order to support a range of devices (printers, tape backup, network interfaces) on the parallel port.
Using I/O Memory
Despite the popularity of I/O ports in the x86 world, the main mechanism used to communicate with devices is through memory-mapped registers and device memory. Both are called I/O memory because the difference between registers and memory is transparent to software.
According to the computer platform and bus being used, I/O memory may or may not be accessed through page tables. When access passes though page tables, the kernel must first arrange for the physical address to be visible from your driver (this usually means that you must call ioremap before doing any I/O). If no page tables are needed, then I/O memory locations look pretty much like I/O ports, and you can just read and write to them using proper wrapper functions.
Remember from Chapter 2, "Building and Running Modules" that device memory regions must be allocated prior to use. This is similar to how I/O ports are registered and is accomplished by the following functions:
int check_mem_region(unsigned long start, unsigned long len); void request_mem_region(unsigned long start, unsigned long len, char *name); void release_mem_region(unsigned long start, unsigned long len);if (check_mem_region(mem_addr, mem_size)) { printk("drivername: memory already in use\n"); return -EBUSY; } request_mem_region(mem_addr, mem_size, "drivername"); [...] release_mem_region(mem_addr, mem_size);Directly Mapped Memory
Several computer platforms reserve part of their memory address space for I/O locations, and automatically disable memory management for any (virtual) address in that memory range.
Other platforms have other means to offer directly mapped address ranges: some of them have special address spaces to dereference physical addresses (for example, SPARC64 uses a special "address space identifier'' for this aim), and others use virtual addresses set up to bypass processor caches.
unsigned readb(address);unsigned readw(address);unsigned readl(address);These macros are used to retrieve 8-bit, 16-bit, and 32-bit data values from I/O memory. The advantage of using macros is the typelessness of the argument:
addressis cast before being used, because the value "is not clearly either an integer or a pointer, and we will accept both'' (from asm-alpha/io.h). Neither the reading nor the writing functions check the validity ofaddress, because they are meant to be as fast as pointer dereferencing (we already know that sometimes they actually expand into pointer dereferencing).
void writeb(unsigned value, address);void writew(unsigned value, address);void writel(unsigned value, address);Like the previous functions, these functions (macros) are used to write 8-bit, 16-bit, and 32-bit data items.
memset_io(address, value, count);
memcpy_fromio(dest, source, num);memcpy_toio(dest, source, num);These functions move blocks of data to and from I/O memory and behave like the C library routine memcpy.
Some 64-bit platforms also offer readq and writeq, for quad-word (eight-byte) memory operations on the PCI bus. The quad-wordnomenclature is a historical leftover from the times when all real processors had 16-bit words. Actually, the Lnaming used for 32-bit values has become incorrect too, but renaming everything would make things still more confused.
Reusing short for I/O Memory
For example, this is how we used short to light the debug LEDs on a MIPS development board:
mips.root#./short_load use_mem=1 base=0xb7ffffc0mips.root#echo -n 7 > /dev/short0The following fragment shows the loop used by short in writing to a memory location:
while (count--) { writeb(*(ptr++), address); wmb(); }Software-Mapped I/O Memory
The MIPS class of processors notwithstanding, directly mapped I/O memory is pretty rare in the current platform arena; this is especially true when a peripheral bus is used with memory-mapped devices (which is most of the time).
The most common hardware and software arrangement for I/O memory is this: devices live at well-known physical addresses, but the CPU has no predefined virtual address to access them. The well-known physical address can be either hardwired in the device or assigned by system firmware at boot time. The former is true, for example, of ISA devices, whose addresses are either burned in device logic circuits, statically assigned in local device memory, or set by means of physical jumpers. The latter is true of PCI devices, whose addresses are assigned by system software and written to device memory, where they persist only while the device is powered on.
Either way, for software to access I/O memory, there must be a way to assign a virtual address to the device. This is the role of the ioremap function, introduced in "vmalloc and Friends". The function, which was covered in the previous chapter because it is related to memory use, is designed specifically to assign virtual addresses to I/O memory regions. Moreover, kernel developers implemented ioremap so that it doesn't do anything if applied to directly mapped I/O addresses.
The functions are called according to the following definition:
#include <asm/io.h> void *ioremap(unsigned long phys_addr, unsigned long size); void *ioremap_nocache(unsigned long phys_addr, unsigned long size); void iounmap(void * addr);/* Remap a not (necessarily) aligned port region */ void *short_remap(unsigned long phys_addr) { /* The code comes mainly from arch/any/mm/ioremap.c */ unsigned long offset, last_addr, size; last_addr = phys_addr + SHORT_NR_PORTS - 1; offset = phys_addr & ~PAGE_MASK; /* Adjust the begin and end to remap a full page */ phys_addr &= PAGE_MASK; size = PAGE_ALIGN(last_addr) - phys_addr; return ioremap(phys_addr, size) + offset; } /* Unmap a region obtained with short_remap */ void short_unmap(void *virt_add) { iounmap((void *)((unsigned long)virt_add & PAGE_MASK)); }ISA Memory Below 1 MB
One of the most well-known I/O memory regions is the ISA range as found on personal computers. This is the memory range between 640 KB (
0xA0000) and 1 MB (0x100000). It thus appears right in the middle of regular system RAM. This positioning may seem a little strange; it is an artifact of a decision made in the early 1980s, when 640 KB of memory seemed like more than anybody would ever be able to use.#define ISA_BASE 0xA0000 #define ISA_MAX 0x100000 /* for general memory access */ /* this line appears in silly_init */ io_base = ioremap(ISA_BASE, ISA_MAX - ISA_BASE);case M_8: while (count) { *ptr = readb(add); add++; count--; ptr++; } break;case M_32: while (count >= 4) { writel(*(u32 *)ptr, add); add+=4; count-=4; ptr+=4; } break;case M_memcpy: memcpy_fromio(ptr, add, count); break;Because ioremap was used to provide access to the ISA memory area, silly must invoke iounmap when the module is unloaded:
iounmap(io_base);isa_readb and Friends
Probing for ISA Memory
Even though most modern devices rely on better I/O bus architectures, like PCI, sometimes programmers must still deal with ISA devices and their I/O memory, so we'll spend a page on this issue. We won't touch high ISA memory (the so-called memory hole in the 14 MB to 16 MB physical address range), because that kind of I/O memory is extremely rare nowadays and is not supported by the majority of modern motherboards or by the kernel. To access that range of I/O memory you'd need to hack the kernel initialization sequence, and that is better not covered here.
unsigned char oldval, newval; /* values read from memory */ unsigned long flags; /* used to hold system flags */ unsigned long add, i; void *base; /* Use ioremap to get a handle on our region */ base = ioremap(ISA_REGION_BEGIN, ISA_REGION_END - ISA_REGION_BEGIN); base -= ISA_REGION_BEGIN; /* Do the offset once */ /* probe all the memory hole in 2-KB steps */ for (add = ISA_REGION_BEGIN; add < ISA_REGION_END; add += STEP) { /* * Check for an already allocated region. */ if (check_mem_region (add, 2048)) { printk(KERN_INFO "%lx: Allocated\n", add); continue; } /* * Read and write the beginning of the region and see what happens. */ save_flags(flags); cli(); oldval = readb (base + add); /* Read a byte */ writeb (oldval^0xff, base + add); mb(); newval = readb (base + add); writeb (oldval, base + add); restore_flags(flags); if ((oldval^newval) == 0xff) { /* we reread our change: it's RAM */ printk(KERN_INFO "%lx: RAM\n", add); continue; } if ((oldval^newval) != 0) { /* random bits changed: it's empty */ printk(KERN_INFO "%lx: empty\n", add); continue; } /* * Expansion ROM (executed at boot time by the BIOS) * has a signature where the first byte is 0x55, the second 0xaa, * and the third byte indicates the size of such ROM */ if ( (oldval == 0x55) && (readb (base + add + 1) == 0xaa)) { int size = 512 * readb (base + add + 2); printk(KERN_INFO "%lx: Expansion ROM, %i bytes\n", add, size); add += (size & ~2048) - 2048; /* skip it */ continue; } /* * If the tests above failed, we still don't know if it is ROM or * empty. Since empty memory can appear as 0x00, 0xff, or the low * address byte, we must probe multiple bytes: if at least one of * them is different from these three values, then this is ROM * (though not boot ROM). */ printk(KERN_INFO "%lx: ", add); for (i=0; i<5; i++) { unsigned long radd = add + 57*(i+1); /* a "random" value */ unsigned char val = readb (base + radd); if (val && val != 0xFF && val != ((unsigned long) radd&0xFF)) break; } printk("%s\n", i==5 ? "empty" : "ROM"); }Detecting memory doesn't cause collisions with other devices, as long as you take care to restore any byte you modified while you were probing. It is worth noting that it is always possible that writing to another device's memory will cause that device to do something undesirable. In general, this method of probing memory should be avoided if possible, but it's not always possible when dealing with older hardware.
Backward Compatibility
Hardware memory barriers didn't exist in version 2.0 of the kernel. There was no need for such ordering instructions on the platforms then supported. Including sysdep.h in your driver will fix the problem by defining hardware barriers to be the same as software barriers.
In Linux 2.0, ioremap and iounmap were called vremapand vfree, respectively. The parameters and the functionality were the same. Thus, a couple of definitions that map the functions to their older counterpart are often enough.
extern inline void *ioremap(unsigned long phys_addr, unsigned long size) { if (phys_addr >= 0xA0000 && phys_addr + size <= 0x100000) return (void *)phys_addr; return vremap(phys_addr, size); } extern inline void iounmap(void *addr) { if ((unsigned long)addr >= 0xA0000 && (unsigned long)addr < 0x100000) return; vfree(addr); }Quick Reference
This chapter introduced the following symbols related to hardware management.
#include <linux/kernel.h>void barrier(void)This "software'' memory barrier requests the compiler to consider all memory volatile across this instruction.
#include <asm/system.h>void rmb(void);void wmb(void);void mb(void);Hardware memory barriers. They request the CPU (and the compiler) to checkpoint all memory reads, writes, or both, across this instruction.
#include <asm/io.h>unsigned inb(unsigned port);void outb(unsigned char byte, unsigned port);unsigned inw(unsigned port);void outw(unsigned short word, unsigned port);unsigned inl(unsigned port);void outl(unsigned doubleword, unsigned port);These functions are used to read and write I/O ports. They can also be called by user-space programs, provided they have the right privileges to access ports.
unsigned inb_p(unsigned port);...The statement
SLOW_DOWN_IOis sometimes needed to deal with slow ISA boards on the x86 platform. If a small delay is needed after an I/O operation, you can use the six pausing counterparts of the functions introduced in the previous entry; these pausing functions have names ending in_p.
void insb(unsigned port, void *addr, unsigned long count);void outsb(unsigned port, void *addr, unsigned long count);void insw(unsigned port, void *addr, unsigned long count);void outsw(unsigned port, void *addr, unsigned long count);void insl(unsigned port, void *addr, unsigned long count);void outsl(unsigned port, void *addr, unsigned long count);The "string functions'' are optimized to transfer data from an input port to a region of memory, or the other way around. Such transfers are performed by reading or writing the same port
counttimes.
#include <linux/ioport.h>int check_region(unsigned long start, unsigned long len);void request_region(unsigned long start, unsigned long len, char *name);void release_region(unsigned long start, unsigned long len);Resource allocators for I/O ports. The checkfunction returns 0 for success and less than 0 in case of error.
int check_mem_region(unsigned long start, unsigned long len);void request_mem_region(unsigned long start, unsigned long len, char *name);void release_mem_region(unsigned long start, unsigned long len);These functions handle resource allocation for memory regions.
#include <asm/io.h>void *ioremap(unsigned long phys_addr, unsigned long size);void *ioremap_nocache(unsigned long phys_addr, unsigned long size);void iounmap(void *virt_addr);ioremap remaps a physical address range into the processor's virtual address space, making it available to the kernel. iounmap frees the mapping when it is no longer needed.
#include <linux/io.h>unsigned readb(address);unsigned readw(address);unsigned readl(address);void writeb(unsigned value, address);void writew(unsigned value, address);void writel(unsigned value, address);memset_io(address, value, count);memcpy_fromio(dest, source, nbytes);memcpy_toio(dest, source, nbytes);These functions are used to access I/O memory regions, either low ISA memory or high PCI buffers.

|
|

|
Back to: Linux Device Drivers, 2nd Edition
oreilly.com Home | O'Reilly Bookstores | How to Order | O'Reilly Contacts
International | About O'Reilly | Affiliated Companies | Privacy Policy
╘ 2001, O'Reilly & Associates, Inc.