





Библиотека сайта rus-linux.net
|
|
|

|
Linux Device Drivers, 2nd EditionBy Alessandro Rubini & Jonathan Corbet2nd Edition June 2001 0-59600-008-1, Order Number: 0081 586 pages, $39.95 |
Chapter 6
Flow of TimeContents:
Time Intervals in the Kernel
Knowing the Current Time
Delaying Execution
Task Queues
Kernel Timers
Backward Compatibility
Quick ReferenceTime Intervals in the Kernel
The first point we need to cover is the timer interrupt, which is the mechanism the kernel uses to keep track of time intervals. Interrupts are asynchronous events that are usually fired by external hardware; the CPU is interrupted in its current activity and executes special code (the Interrupt Service Routine, or ISR) to serve the interrupt. Interrupts and ISR implementation issues are covered in Chapter 9, "Interrupt Handling".
Timer interrupts are generated by the system's timing hardware at regular intervals; this interval is set by the kernel according to the value of
HZ, which is an architecture-dependent value defined in<linux/param.h>. Current Linux versions defineHZto be 100 for most platforms, but some platforms use 1024, and the IA-64 simulator uses 20. Despite what your preferred platform uses, no driver writer should count on any specific value ofHZ.Every time a timer interrupt occurs, the value of the variable
jiffiesis incremented.jiffiesis initialized to 0 when the system boots, and is thus the number of clock ticks since the computer was turned on. It is declared in<linux/sched.h>asunsigned long volatile, and will possibly overflow after a long time of continuous system operation (but no platform features jiffy overflow in less than 16 months of uptime). Much effort has gone into ensuring that the kernel operates properly whenjiffiesoverflows. Driver writers do not normally have to worry aboutjiffiesoverflows, but it is good to be aware of the possibility.Processor-Specific Registers
If you need to measure very short time intervals or you need extremely high precision in your figures, you can resort to platform-dependent resources, selecting precision over portability.
Most modern CPUs include a high-resolution counter that is incremented every clock cycle; this counter may be used to measure time intervals precisely. Given the inherent unpredictability of instruction timing on most systems (due to instruction scheduling, branch prediction, and cache memory), this clock counter is the only reliable way to carry out small-scale timekeeping tasks. In response to the extremely high speed of modern processors, the pressing demand for empirical performance figures, and the intrinsic unpredictability of instruction timing in CPU designs caused by the various levels of cache memories, CPU manufacturers introduced a way to count clock cycles as an easy and reliable way to measure time lapses. Most modern processors thus include a counter register that is steadily incremented once at each clock cycle.
The most renowned counter register is the TSC (timestamp counter), introduced in x86 processors with the Pentium and present in all CPU designs ever since. It is a 64-bit register that counts CPU clock cycles; it can be read from both kernel space and user space.
After including
<asm/msr.h>(for "machine-specific registers''), you can use one of these macros:rdtsc(low,high); rdtscl(low);These lines, for example, measure the execution of the instruction itself:
unsigned long ini, end; rdtscl(ini); rdtscl(end); printk("time lapse: %li\n", end - ini);#include <linux/timex.h> cycles_t get_cycles(void);Despite the availability of an architecture-independent function, we'd like to take the chance to show an example of inline assembly code. To this aim, we'll implement a rdtscl function for MIPS processors that works in the same way as the x86 one.
#define rdtscl(dest) \ __asm__ __volatile__("mfc0 %0,$9; nop" : "=r" (dest))With this macro in place, the MIPS processor can execute the same code shown earlier for the x86.
The short C-code fragment shown in this section has been run on a K7-class x86 processor and a MIPS VR4181 (using the macro just described). The former reported a time lapse of 11 clock ticks, and the latter just 2 clock ticks. The small figure was expected, since RISC processors usually execute one instruction per clock cycle.
Knowing the Current Time
Kernel code can always retrieve the current time by looking at the value of
jiffies. Usually, the fact that the value represents only the time since the last boot is not relevant to the driver, because its life is limited to the system uptime. Drivers can use the current value ofjiffiesto calculate time intervals across events (for example, to tell double clicks from single clicks in input device drivers). In short, looking atjiffiesis almost always sufficient when you need to measure time intervals, and if you need very sharp measures for short time lapses, processor-specific registers come to the rescue.If your driver really needs the current time, the do_gettimeofday function comes to the rescue. This function doesn't tell the current day of the week or anything like that; rather, it fills a
struct timevalpointer -- the same as used in the gettimeofday system call -- with the usual seconds and microseconds values. The prototype for do_gettimeofday is:#include <linux/time.h> void do_gettimeofday(struct timeval *tv);The source states that do_gettimeofday has "near microsecond resolution'' for many architectures. The precision does vary from one architecture to another, however, and can be less in older kernels. The current time is also available (though with less precision) from the
xtimevariable (astruct timeval); however, direct use of this variable is discouraged because you can't atomically access both thetimevalfieldstv_secandtv_usecunless you disable interrupts. As of the 2.2 kernel, a quick and safe way of getting the time quickly, possibly with less precision, is to call get_fast_time:void get_fast_time(struct timeval *tv);Code for reading the current time is available within the jit ("Just In Time'') module in the source files provided on the O'Reilly FTP site. jit creates a file called /proc/currentime, which returns three things in ASCII when read:
morgana%cd /proc; cat currentime currentime currentimegettime: 846157215.937221 xtime: 846157215.931188 jiffies: 1308094 gettime: 846157215.939950 xtime: 846157215.931188 jiffies: 1308094 gettime: 846157215.942465 xtime: 846157215.941188 jiffies: 1308095Delaying Execution
Device drivers often need to delay the execution of a particular piece of code for a period of time -- usually to allow the hardware to accomplish some task. In this section we cover a number of different techniques for achieving delays. The circumstances of each situation determine which technique is best to use; we'll go over them all and point out the advantages and disadvantages of each.
Long Delays
If you want to delay execution by a multiple of the clock tick or you don't require strict precision (for example, if you want to delay an integer number of seconds), the easiest implementation (and the most braindead) is the following, also known as busy waiting:
unsigned long j = jiffies + jit_delay * HZ; while (jiffies < j) /* nothing */;So let's look at how this code works. The loop is guaranteed to work because
jiffiesis declared asvolatileby the kernel headers and therefore is reread any time some C code accesses it. Though "correct,'' this busy loop completely locks the processor for the duration of the delay; the scheduler never interrupts a process that is running in kernel space. Still worse, if interrupts happen to be disabled when you enter the loop,jiffieswon't be updated, and thewhilecondition remains true forever. You'll be forced to hit the big red button.This implementation of delaying code is available, like the following ones, in the jit module. The /proc/jit* files created by the module delay a whole second every time they are read. If you want to test the busy wait code, you can read /proc/jitbusy, which busy-loops for one second whenever its readmethod is called; a command such as dd if=/proc/jitbusy bs=1 delays one second each time it reads a character.
while (jiffies < j) schedule();If your driver uses a wait queue to wait for some other event, but you also want to be sure it runs within a certain period of time, it can use the timeout versions of the sleep functions, as shown in "Going to Sleep and Awakening" in Chapter 5, "Enhanced Char Driver Operations":
sleep_on_timeout(wait_queue_head_t *q, unsigned long timeout); interruptible_sleep_on_timeout(wait_queue_head_t *q, unsigned long timeout);wait_queue_head_t wait; init_waitqueue_head (&wait); interruptible_sleep_on_timeout(&wait, jit_delay*HZ);In a normal driver, execution could be resumed in either of two ways: somebody calls wake_up on the wait queue, or the timeout expires. In this particular implementation, nobody will ever call wake_up on the wait queue (after all, no other code even knows about it), so the process will always wake up when the timeout expires. That is a perfectly valid implementation, but, if there are no other events of interest to your driver, delays can be achieved in a more straightforward manner with schedule_timeout:
set_current_state(TASK_INTERRUPTIBLE); schedule_timeout (jit_delay*HZ);The previous line (for /proc/jitself) causes the process to sleep until the given time has passed. schedule_timeout, too, expects a time offset, not an absolute number of jiffies. Once again, it is worth noting that an extra time interval could pass between the expiration of the timeout and when your process is actually scheduled to execute.
Short Delays
Sometimes a real driver needs to calculate very short delays in order to synchronize with the hardware. In this case, using the
jiffiesvalue is definitely not the solution.The kernel functions udelay and mdelay serve this purpose.[27] Their prototypes are
[27] The
uin udelay represents the Greek letter mu and stands for micro.#include <linux/delay.h> void udelay(unsigned long usecs); void mdelay(unsigned long msecs);The functions are compiled inline on most supported architectures. The former uses a software loop to delay execution for the required number of microseconds, and the latter is a loop around udelay, provided for the convenience of the programmer. The udelay function is where the BogoMips value is used: its loop is based on the integer value
loops_per_second, which in turn is the result of the BogoMips calculation performed at boot time.Although mdelay is not available in Linux 2.0, sysdep.h fills the gap.
Task Queues
One feature many drivers need is the ability to schedule execution of some tasks at a later time without resorting to interrupts. Linux offers three different interfaces for this purpose: task queues, tasklets (as of kernel 2.3.43), and kernel timers. Task queues and tasklets provide a flexible utility for scheduling execution at a later time, with various meanings for "later''; they are most useful when writing interrupt handlers, and we'll see them again in "Tasklets and Bottom-Half Processing", in Chapter 9, "Interrupt Handling". Kernel timers are used to schedule a task to run at a specific time in the future and are dealt with in "Kernel Timers", later in this chapter.
The Nature of Task Queues
A queue element is described by the following structure, copied directly from
<linux/tqueue.h>:struct tq_struct { struct tq_struct *next; /* linked list of active bh's */ int sync; /* must be initialized to zero */ void (*routine)(void *); /* function to call */ void *data; /* argument to function */ };The "bh'' in the first comment means bottom half. A bottom half is "half of an interrupt handler''; we'll discuss this topic thoroughly when we deal with interrupts in "Tasklets and Bottom-Half Processing", in Chapter 9, "Interrupt Handling". For now, suffice it to say that a bottom half is a mechanism provided by a device driver to handle asynchronous tasks which, usually, are too large to be done while handling a hardware interrupt. This chapter should make sense without an understanding of bottom halves, but we will, by necessity, refer to them occasionally.
DECLARE_TASK_QUEUE(name);This macro declares a task queue with the given
name, and initializes it to the empty state.
int queue_task(struct tq_struct *task, task_queue *list);
void run_task_queue(task_queue *list);
How Task Queues Are Run
A task queue, as we have already seen, is in practice a linked list of functions to call. When run_task_queue is asked to run a given queue, each entry in the list is executed. When you are writing functions that work with task queues, you have to keep in mind when the kernel will call run_task_queue; the exact context imposes some constraints on what you can do. You should also not make any assumptions regarding the order in which enqueued tasks are run; each of them must do its task independently of the other ones.
One other feature of the current implementation of task queues is that a task can requeue itself in the same queue from which it was run. For instance, a task being run from the timer tick can reschedule itself to be run on the next tick by calling queue_task to put itself on the queue again. Rescheduling is possible because the head of the queue is replaced with a
NULLpointer before consuming queued tasks; as a result, a new queue is built once the old one starts executing.Predefined Task Queues
The easiest way to perform deferred execution is to use the queues that are already maintained by the kernel. There are a few of these queues, but your driver can use only three of them, described in the following list. The queues are declared in
<linux/tqueue.h>, which you should include in your source.
- The scheduler queue
The scheduler queue is unique among the predefined task queues in that it runs in process context, implying that the tasks it runs have a bit more freedom in what they can do. In Linux 2.4, this queue runs out of a dedicated kernel thread called keventdand is accessed via a function called schedule_task. In older versions of the kernel, keventd was not used, and the queue (
tq_scheduler) was manipulated directly.
tq_timerThis queue is run by the timer tick. Because the tick (the function do_timer) runs at interrupt time, any task within this queue runs at interrupt time as well.
tq_immediateThe immediate queue is run as soon as possible, either on return from a system call or when the scheduler is run, whichever comes first. The queue is consumed at interrupt time.
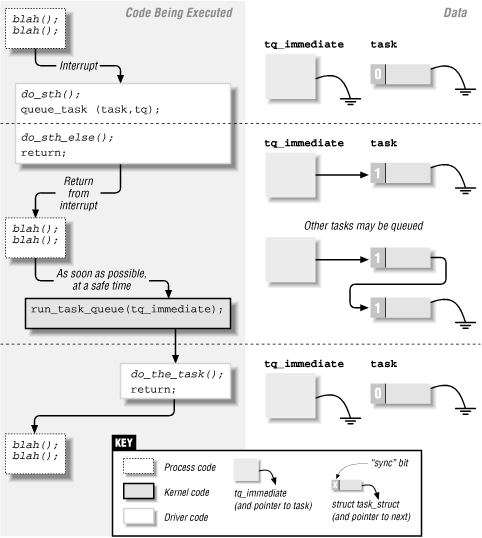
Figure 6-1. Timeline of task-queue usage
How the examples work
Examples of deferred computation are available in the jiq ("Just In Queue") module, from which the source in this section has been extracted. This module creates /proc files that can be read using dd or other tools; this is similar to jit.
DECLARE_WAIT_QUEUE_HEAD (jiq_wait);struct tq_struct jiq_task; /* global: initialized to zero */ /* these lines are in jiq_init() */ jiq_task.routine = jiq_print_tq; jiq_task.data = (void *)&jiq_data;The scheduler queue
The scheduler queue is, in some ways, the easiest to use. Because tasks executed from this queue do not run in interrupt mode, they can do more things; in particular, they can sleep. Many parts of the kernel use this queue to accomplish a wide variety of tasks.
As of kernel 2.4.0-test11, the actual task queue implementing the scheduler queue is hidden from the rest of the kernel. Rather than use queue_task directly, code using this queue must call schedule_task to put a task on the queue:
int schedule_task(struct tq_struct *task);int jiq_read_sched(char *buf, char **start, off_t offset, int len, int *eof, void *data) { jiq_data.len = 0; /* nothing printed, yet */ jiq_data.buf = buf; /* print in this place */ jiq_data.jiffies = jiffies; /* initial time */ /* jiq_print will queue_task() again in jiq_data.queue */ jiq_data.queue = SCHEDULER_QUEUE; schedule_task(&jiq_task); /* ready to run */ interruptible_sleep_on(&jiq_wait); /* sleep till completion */ *eof = 1; return jiq_data.len; }Reading /proc/jiqsched produces output like the following:
time delta interrupt pid cpu command 601687 0 0 2 1 keventd 601687 0 0 2 1 keventd 601687 0 0 2 1 keventd 601687 0 0 2 1 keventd 601687 0 0 2 1 keventd 601687 0 0 2 1 keventd 601687 0 0 2 1 keventd 601687 0 0 2 1 keventd 601687 0 0 2 1 keventdIn this case, we see that the task is always running under the keventd process. It also runs very quickly -- a task that resubmits itself to the scheduler queue can run hundreds or thousands of times within a single timer tick. Even on a very heavily loaded system, the latency in the scheduler queue is quite small.
The timer queue
The timer queue is different from the scheduler queue in that the queue (
tq_timer) is directly available. Also, of course, tasks run from the timer queue are run in interrupt mode. Additionally, you're guaranteed that the queue will run at the next clock tick, thus eliminating latency caused by system load.int jiq_read_timer(char *buf, char **start, off_t offset, int len, int *eof, void *data) { jiq_data.len = 0; /* nothing printed, yet */ jiq_data.buf = buf; /* print in this place */ jiq_data.jiffies = jiffies; /* initial time */ jiq_data.queue = &tq_timer; /* reregister yourself here */ queue_task(&jiq_task, &tq_timer); /* ready to run */ interruptible_sleep_on(&jiq_wait); /* sleep till completion */ *eof = 1; return jiq_data.len; }The following is what head /proc/jiqtimerreturned on a system that was compiling a new kernel:
time delta interrupt pid cpu command 45084845 1 1 8783 0 cc1 45084846 1 1 8783 0 cc1 45084847 1 1 8783 0 cc1 45084848 1 1 8783 0 cc1 45084849 1 1 8784 0 as 45084850 1 1 8758 1 cc1 45084851 1 1 8789 0 cpp 45084852 1 1 8758 1 cc1 45084853 1 1 8758 1 cc1 45084854 1 1 8758 1 cc1 45084855 1 1 8758 1 cc1The immediate queue
The last predefined queue that can be used by modularized code is the immediate queue. This queue is run via the bottom-half mechanism, which means that one additional step is required to use it. Bottom halves are run only when the kernel has been told that a run is necessary; this is accomplished by "marking'' the bottom half. In the case of
tq_immediate, the necessary call is mark_bh(IMMEDIATE_BH). Be sure to call mark_bh after the task has been queued; otherwise, the kernel may run the task queue before your task has been added.time delta interrupt pid cpu command 45129449 0 1 8883 0 head 45129453 4 1 0 0 swapper 45129453 0 1 601 0 X 45129453 0 1 601 0 X 45129453 0 1 601 0 X 45129453 0 1 601 0 X 45129454 1 1 0 0 swapper 45129454 0 1 601 0 X 45129454 0 1 601 0 X 45129454 0 1 601 0 X 45129454 0 1 601 0 X 45129454 0 1 601 0 X 45129454 0 1 601 0 X 45129454 0 1 601 0 XPlease note that you should not reregister your task in this queue (although we do it in jiqimmed for explanatory purposes). The practice gains nothing and may lock the computer hard if run on some version/platform pairs. Some implementations used to rerun the queue until it was empty. This was true, for example, for version 2.0 running on the PC platform.
Running Your Own Task Queues
Declaring a new task queue is not difficult. A driver is free to declare a new task queue, or even several of them; tasks are queued just as we've seen with the predefined queues discussed previously.
DECLARE_TASK_QUEUE(tq_custom);queue_task(&custom_task, &tq_custom);run_task_queue(&tq_custom);Tasklets
Shortly before the release of the 2.4 kernel, the developers added a new mechanism for the deferral of kernel tasks. This mechanism, called tasklets, is now the preferred way to accomplish bottom-half tasks; indeed, bottom halves themselves are now implemented with tasklets.
Software support for tasklets is part of
<linux/interrupt.h>, and the tasklet itself must be declared with one of the following:void jiq_print_tasklet (unsigned long); DECLARE_TASKLET (jiq_tasklet, jiq_print_tasklet, (unsigned long) &jiq_data);When your driver wants to schedule a tasklet to run, it calls tasklet_schedule:
tasklet_schedule(&jiq_tasklet);The output from /proc/jiqtasklet looks like this:
time delta interrupt pid cpu command 45472377 0 1 8904 0 head 45472378 1 1 0 0 swapper 45472379 1 1 0 0 swapper 45472380 1 1 0 0 swapper 45472383 3 1 0 0 swapper 45472383 0 1 601 0 X 45472383 0 1 601 0 X 45472383 0 1 601 0 X 45472383 0 1 601 0 X 45472389 6 1 0 0 swapperThe tasklet subsystem provides a few other functions for advanced use of tasklets:
void tasklet_disable(struct tasklet_struct *t);
void tasklet_enable(struct tasklet_struct *t);
void tasklet_kill(struct tasklet_struct *t);
Kernel Timers
The ultimate resources for time keeping in the kernel are the timers. Timers are used to schedule execution of a function (a timer handler) at a particular time in the future. They thus work differently from task queues and tasklets in that you can specify when in the future your function will be called, whereas you can't tell exactly when a queued task will be executed. On the other hand, kernel timers are similar to task queues in that a function registered in a kernel timer is executed only once -- timers aren't cyclic.
The kernel timers are organized in a doubly linked list. This means that you can create as many timers as you want. A timer is characterized by its timeout value (in jiffies) and the function to be called when the timer expires. The timer handler receives an argument, which is stored in the data structure, together with a pointer to the handler itself.
The data structure of a timer looks like the following, which is extracted from
<linux/timer.h>):struct timer_list { struct timer_list *next; /* never touch this */ struct timer_list *prev; /* never touch this */ unsigned long expires; /* the timeout, in jiffies */ unsigned long data; /* argument to the handler */ void (*function)(unsigned long); /* handler of the timeout */ volatile int running; /* added in 2.4; don't touch */ };These are the functions used to act on timers:
void init_timer(struct timer_list *timer);
void add_timer(struct timer_list *timer);This function inserts a timer into the global list of active timers.
int mod_timer(struct timer_list *timer, unsigned long expires);
int del_timer(struct timer_list *timer);
int del_timer_sync(struct timer_list *timer);
An example of timer usage can be seen in the jiq module. The file /proc/jitimer uses a timer to generate two data lines; it uses the same printing function as the task queue examples do. The first data line is generated from the read call (invoked by the user process looking at /proc/jitimer), while the second line is printed by the timer function after one second has elapsed.
The code for /proc/jitimer is as follows:
struct timer_list jiq_timer; void jiq_timedout(unsigned long ptr) { jiq_print((void *)ptr); /* print a line */ wake_up_interruptible(&jiq_wait); /* awaken the process */ } int jiq_read_run_timer(char *buf, char **start, off_t offset, int len, int *eof, void *data) { jiq_data.len = 0; /* prepare the argument for jiq_print() */ jiq_data.buf = buf; jiq_data.jiffies = jiffies; jiq_data.queue = NULL; /* don't requeue */ init_timer(&jiq_timer); /* init the timer structure */ jiq_timer.function = jiq_timedout; jiq_timer.data = (unsigned long)&jiq_data; jiq_timer.expires = jiffies + HZ; /* one second */ jiq_print(&jiq_data); /* print and go to sleep */ add_timer(&jiq_timer); interruptible_sleep_on(&jiq_wait); del_timer_sync(&jiq_timer); /* in case a signal woke us up */ *eof = 1; return jiq_data.len; }Running head /proc/jitimer gives the following output:
time delta interrupt pid cpu command 45584582 0 0 8920 0 head 45584682 100 1 0 1 swapperAnother pattern that can cause race conditions is modifying timers by deleting them with del_timer, then creating a new one with add_timer. It is better, in this situation, to simply use mod_timer to make the necessary change.
Backward Compatibility
Task queues and timing issues have remained relatively constant over the years. Nonetheless, a few things have changed and must be kept in mind.
interruptible_sleep_on_timeout(my_queue, timeout);current->timeout = jiffies + timeout; interruptible_sleep_on(my_queue);extern inline void schedule_timeout(int timeout) { current->timeout = jiffies + timeout; current->state = TASK_INTERRUPTIBLE; schedule(); current->timeout = 0; }In 2.0, there were a couple of additional functions for putting functions into task queues. queue_task_irq could be called instead of queue_task in situations in which interrupts were disabled, yielding a (very) small performance benefit. queue_task_irq_off is even faster, but does not function properly in situations in which the task is already queued or is running, and can thus only be used where those conditions are guaranteed not to occur. Neither of these two functions provided much in the way of performance benefits, and they were removed in kernel 2.1.30. Using queue_task in all cases works with all kernel versions. (It is worth noting, though, that queue_task had a return type of
voidin 2.2 and prior kernels.)Prior to 2.4, the schedule_task function and associated keventd process did not exist. Instead, another predefined task queue,
tq_scheduler, was provided. Tasks placed intq_schedulerwere run in the schedule function, and thus always ran in process context. The actual process whose context would be used was always different, however; it was whatever process was being scheduled on the CPU at the time.tq_schedulertypically had larger latencies, especially for tasks that resubmitted themselves. sysdep.h provides the following implementation for schedule_task on 2.0 and 2.2 systems:extern inline int schedule_task(struct tq_struct *task) { queue_task(task, &tq_scheduler); return 1; }The in_interrupt function did not exist in Linux 2.0. Instead, a global variable
intr_countkept track of the number of interrupt handlers running. Queryingintr_countis semantically the same as calling in_interrupt, so compatibility is easily implemented in sysdep.h.Quick Reference
This chapter introduced the following symbols:
#include <linux/param.h>HZThe
HZsymbol specifies the number of clock ticks generated per second.
#include <linux/sched.h>volatile unsigned long jiffiesThe
jiffiesvariable is incremented once for each clock tick; thus, it's incrementedHZtimes per second.
#include <asm/msr.h>rdtsc(low,high);rdtscl(low);Read the timestamp counter or its lower half. The header and macros are specific to PC-class processors; other platforms may need
asmconstructs to achieve similar results.
extern struct timeval xtime;
#include <linux/time.h>void do_gettimeofday(struct timeval *tv);void get_fast_time(struct timeval *tv);The functions return the current time; the former is very high resolution, the latter may be faster while giving coarser resolution.
#include <linux/delay.h>void udelay(unsigned long usecs);void mdelay(unsigned long msecs);The functions introduce delays of an integer number of microseconds and milliseconds. The former should be used to wait for no longer than one millisecond; the latter should be used with extreme care because these delays are both busy-loops.
int in_interrupt();Returns nonzero if the processor is currently running in interrupt mode.
#include <linux/tqueue.h>DECLARE_TASK_QUEUE(variablename);
void queue_task(struct tq_struct *task, task_queue *list);
void run_task_queue(task_queue *list);
task_queue tq_immediate, tq_timer;These predefined task queues are run as soon as possible (for
tq_immediate), or after each timer tick (fortq_timer).
int schedule_task(struct tq_struct *task);
#include <linux/interrupt.h>DECLARE_TASKLET(name, function, data)DECLARE_TASKLET_DISABLED(name, function, data)Declare a tasklet structure that will call the given function (passing it the given
unsigned longdata) when the tasklet is executed. The second form initializes the tasklet to a disabled state, keeping it from running until it is explicitly enabled.
void tasklet_schedule(struct tasklet_struct *tasklet);
tasklet_enable(struct tasklet_struct *tasklet);tasklet_disable(struct tasklet_struct *tasklet);These functions respectively enable and disable the given tasklet. A disabled tasklet can be scheduled, but will not run until it has been enabled again.
void tasklet_kill(struct tasklet_struct *tasklet);
#include <linux/timer.h>void init_timer(struct timer_list * timer);
void add_timer(struct timer_list * timer);This function inserts the
timerinto the global list of pending timers.
int mod_timer(struct timer_list *timer, unsigned long expires);This function is used to change the expiration time of an already scheduled timer structure.
int del_timer(struct timer_list * timer);
int del_timer_sync(struct timer_list *timer);This function is similar to del_timer, but guarantees that the function is not currently running on other CPUs.

|
|

|
Back to: Linux Device Drivers, 2nd Edition
oreilly.com Home | O'Reilly Bookstores | How to Order | O'Reilly Contacts
International | About O'Reilly | Affiliated Companies | Privacy Policy
╘ 2001, O'Reilly & Associates, Inc.