





Библиотека сайта rus-linux.net
Contingent: Динамическая система сборки
Оригинал: Contingent: A Fully Dynamic Build System
Авторы: Brandon Rhodes, Daniel Rocco
Дата публикации: July 12, 2016
Перевод: Н.Ромоданов
Дата перевода: январь 2017 г.
Изучаем взаимосвязи
Теперь у нас есть способ отслеживать в системе Contingent задачи и отношения между ними. Однако, если мы внимательно посмотрим на рис.4.2, то мы увидим, что он, на самом деле, требует некоторой корректировки и недостаточно строг: как из файла api.rst создается файл api.html? Как мы узнаем, что в файле index.html нужен заголовок, который нужно взять из самого руководства? И как решается эта зависимость?
Когда мы вручную создавали последовательности графов, то решить эти вопросы нам помогало наше интуитивное понимание этих идей, но, к сожалению, компьютеры не столь интуитивно понятливы и, поэтому нам нужно будет точно указать, что мы хотим.
Какие шаги необходимо выполнить для того, чтобы получить результат из исходных файлов? Как эти шаги определены и выполняются? И как система Contingent может определить взаимозависимости между ними?
В системе Contingent задачи сборки моделируются как функции и аргументы. Функции определяют действия, для которых понятно, как выполнить их в каждом конкретном проекте. Аргументы уточняют специфику: какой исходный документ должен быть прочитан, какой заголовок блога нужен. Когда эти функции выполняются, они могут, в свою очередь, вызывать функции других задач, передавая им любые аргументы, которые потребуются для получения ответа.
Для того, чтобы увидеть, как это работает, мы сейчас на практике реализуем сборку документации, описанную в начале данной главы. Для того, чтобы не утонуть в болоте деталей, мы в этом примере будем работать с упрощенными форматами входных и выходных документов. Наши входные документы будут состоять из заголовка, расположенного в первой строке, и остальной части текста, образующего тело. Перекрестные ссылки будут просто именами исходных файлов, заключенные в обратные кавычки, которые в выходных данных заменяются заголовком из соответствующего документа
Ниже приведен пример с файлами index.txt, api.txt и tutorial.txt,, иллюстративными заголовками, телом документов, а также перекрестными ссылками и упрощенным форматом документа:
>>> index = """ ... Table of Contents ... ----------------- ... * `tutorial.txt` ... * `api.txt` ... """ >>> tutorial = """ ... Beginners Tutorial ... ------------------ ... Welcome to the tutorial! ... We hope you enjoy it. ... """ >>> api = """ ... API Reference ... ------------- ... You might want to read ... the `tutorial.txt` first. ... """
Теперь, когда у нас есть некоторый исходный материал для работы, какие функции потребуются для сборки блога с использованием системы Contingent?
В простых примерах, которые приведены выше, выходные файлы HTML создаются непосредственно из исходных файлов, но в реальной системе, превращение исходных данных выполняется в несколько этапов: чтение исходного текста с диска, анализ этого текста и преобразование его в удобное внутреннее представление, обработка любых директив, которые может указать автор, разрешение перекрестных ссылок или других внешних зависимостей (например, файлов include), и применение одного или нескольких преобразования представлений для перевода внутреннего представления в соответствующую выходную форму.
Система Contingent управляет задачами при помощи группирования их в виде проекта Project и внедрения внутрь процесса сборки специального модуля, который для того, чтобы построить график отношений между всеми задачами, делает пометки каждый раз, когда одна задача вызывает другую.
>>> from contingent.projectlib import Project, Task >>> project = Project() >>> task = project.task
Система сборки для примера, приведенного в начале данной главы, может потребовать выполнить несколько задач.
Наша задача read() будет делать вид, что читает файлы с диска. Поскольку мы, в действительности, указали исходный текст в переменных, то все, что нужно сделать, это преобразовать имя файла в соответствующий текст.
>>> filesystem = {'index.txt': index,
... 'tutorial.txt': tutorial,
... 'api.txt': api}
...
>>> @task
... def read(filename):
... return filesystem[filename]
Задача parse() интерпретирует исходный текст содержимого файла в соответствие со спецификациями формата нашего документа. Наш формат очень прост: на первой строке отображается название документа, а остальная часть содержания считается телом документа.
>>> @task ... def parse(filename): ... lines = read(filename).strip().splitlines() ... title = lines[0] ... body = '\n'.join(lines[2:]) ... return title, body
Т.к. формат документа весьма прост, использование синтаксического анализатора (parser-а) выглядит несколько глупо, но он иллюстрирует распределение обязанностей, выполнение которых возлагается на парсеры. (Синтаксический анализ, в целом, очень интересная тема, и во многих книгах он описан либо частично, либо полностью). В таких системах, как, например, Sphinx, парсер должен понимать большое количество лексем, используемых для разметки документов, директив и команд, определенных в системе, и превращать входной текст во что-то такое, с чем сможет работать остальная часть системы.
Обратите внимание на место между parse() и read() — первая задача при синтаксическом анализе состоит в передаче имени файла задаче read(), которая должна найти файл и вернуть содержимое этого файла.
Задача title_of() берет имя исходного файла и возвращает заголовок документа:
>>> @task ... def title_of(filename): ... title, body = parse(filename) ... return title
Эта задача хорошо иллюстрирует разделение обязанностей между частями системы обработки документов. Функция title_of() работает непосредственно c представлением документа в памяти, в данном случае, с кортежем, а не пытается самостоятельно выполнить синтаксический анализ только для того, чтобы найти название. Функция parse()является единственной, которая создает представление документа в памяти в соответствии со спецификациями системы, а остальные функции, которые осуществляют сборку блога, например, title_of(), просто используют результат ее работы для решения своих задач.
Если вы двигаетесь от ортодоксальных объектно-ориентированных традиций, такая функционально ориентированная конструкция может выглядеть немного странно. С точки зрения объектно-ориентированного подхода В решении ОО, функция parse()должна была бы возвращать некоторый объект вида Document, в котором в качестве метода или свойства была бы функция title_of(). На самом деле именно так работает система Sphinx: ее подсистема синтаксического анализа Parser создает объект "дерево документа Docutils", который используется другими частями системы.
Что касается различных конструктивных парадигм, то система Contingent не столь самоуверенна и одинаково хорошо поддерживает любой подход. Для данной главы мы пытаемся все сделать как можно проще.
Последняя задача, render(), превращает представление документа, которое находится в памяти, в документ в выходном формате. Это, по сути, действие, обратное действию parse(). В то время, как функция parse() берет входной документ и, согласно спецификации, преобразует его в его представление в памяти, функция render()берет представление документа в памяти и формирует выходной документ, соответствующий некоторой спецификации.
>>> import re
>>>
>>> LINK = '<a href="{}">{}</a>'
>>> PAGE = '<h1>{}</h1>\n<p>\n{}\n<p>'
>>>
>>> def make_link(match):
... filename = match.group(1)
... return LINK.format(filename, title_of(filename))
...
>>> @task
... def render(filename):
... title, body = parse(filename)
... body = re.sub(r'`([^`]+)`', make_link, body)
... return PAGE.format(title, body)
Ниже приведен пример работы с вызовом каждого этапа описанной выше логики – для того, чтобы получить выходной файл, выполняется рендеринг файла tutorial.txt:
>>> print(render('tutorial.txt'))
<h1>Beginners Tutorial</h1>
<p>
Welcome to the tutorial!
We hope you enjoy it.
<p>
На рис.4.3 проиллюстрирован граф задач, в котором транзитивно соединены все задачи, выполнение которых необходимо для получения выходного документа - от чтения входного файла, разбора и преобразования документа и до его рендеринга:

Рис.4.3. Граф задач
Рис.4.3 для этой главы нарисован не вручную, а был сформирован с помощью системы Contingent! Для объекта Project можно создать такой граф, т. к. в этом объекте есть свой собственный стек вызовов, похожий на стек исполнения фреймов, который позволяет языку Python запоминать какая функция должна продолжать работать после того, как произойдет единичный возврат из вызова.
Каждый раз, когда происходит обращение к новой задаче, система Contingent предполагает, что эта задача будет вызвана и результат ее работы будет использован в задаче, которая в настоящее время находится на вершине стека. Для поддержки работы со стеком при вызове задачи T потребуется несколько дополнительных шагов:
- Задача T помещается в стек.
- Происходит выполнение задачи T; она может вызывать любые другие задачи, если это необходимо.
- Задача T выталкивается из стека.
- Возвращается результат ее работы.
Для перехвата вызовов задач в объекте Project используется ключевая особенность языка Python: декораторы функций (function decorators) . Декоратор разрешается обрабатывать или трансформировать функцию в тот момент, когда она определяется. В декораторе Project.task эта возможность используется для того, чтобы упаковать каждую задачу внутри другой функции, обертки (функции wrapper), и обеспечить четкое разделение обязанностей между функцией-оберткой, которая от имени объекта Project будет беспокоиться о графе и управление стеком, и функциями нашей задачи, которые сосредоточены на обработке документов. Шаблон декоратора задачи task выглядит следующим образом:
from functools import wraps
def task(function):
@wraps(function)
def wrapper(*args):
# wrapper body, that will call function()
return wrapper
Это совершенно типичное объявление декоратора в языке Python. Затем его можно будет применить к функции, указав перед ее определением def, с помощью которого создается функция, ее имя после символа @:
@task
def title_of(filename):
title, body = parse(filename)
return title
Когда это определение будет завершено, имя title_of будет указывать на версию функции, которая уже будет находиться в обертке. Функция-обертка может получить доступ к исходному варианту функции с помощью имени function, обращаясь к нему в соответствующие моменты времени. Тело обертки в системе Contingent работает приблизительно следующим образом:
def task(function):
@wraps(function)
def wrapper(*args):
task = Task(wrapper, args)
if self.task_stack:
self._graph.add_edge(task, self.task_stack[-1])
self._graph.clear_inputs_of(task)
self._task_stack.append(task)
try:
value = function(*args)
finally:
self._task_stack.pop()
return value
return wrapper
Эта обертка выполняет несколько важных шагов:
- Упаковывать задачу - функцию плюс ее аргументы - в маленький объект для удобства. Здесь с помощью wrapper именуется обвернутая версия функции задачи.
- Если эта задача была вызвана с помощью той задачи, которая уже выполняется полным ходом, то добавляем ребро, указывая тот факт, что вход в эту задачу происходит из уже запущенной задачи.
- Забудьте все, что мы могли бы знать о задаче перед этим, поскольку на этот раз могут приниматься новые решения - например, если исходный текст руководства по API больше не упоминается в документе Tutoria, то функция его рендеринга render() больше не будет обращаться к функции title_of() документа Tutorial.
- В случае, если в ходе выполнения своей работы эта задача будет вызывать еще задачи, то помещаем эту задачу на вершину стека задач.
- Вызываем задачу внутри блока try...finally для того, чтобы гарантировать, что даже в случае возникновения исключения мы правильно удалим завершенную задачу из стека.
- Возвращаем значение, которое было возвращено задачей, поэтому задача, которая вызвала эту обертку не сможет определить, что была вызвана не сама по себе просто необходимая нам функция задачи.
Выполнение шагов 4 и 5 поддерживается самим стеком задача, который затем используется на шаге 2 для последующего отслеживания того, ради чего в первую очередь и строится стек задач.
Поскольку каждая задача заменяется своей копией, в которой уже есть обертка, то обычный вызов и работа со стеком задач будет в качестве невидимого побочного эффекта создавать граф взаимосвязей. Именно поэтому мы были так аккуратны, когда помещали в обертку каждый определяемый нами шаг обработки:
@task
def read(filename):
# тело задачи read
@task
def parse(filename):
# тело задачи parse
@task
def title_of(filename):
# тело задачи title_of
@task
def render(filename):
# тело задачи render
Когда мы вызываем анализатор parse('tutorial.txt'), то, благодаря таким оберткам , декоратор устанавливает наличие связи между задачами анализа parse и чтения read. Мы можем задать вопрос о наличии взаимосвязи путем создания еще одного кортежа Task и спросить, какова будет последовательность действий в случае, если выходные данные этой задачи изменятся:
>>> task = Task(read, ('tutorial.txt',))
>>> print(task)
read('tutorial.txt')
>>> project._graph.immediate_consequences_of(task)
[parse('tutorial.txt')]
После того, как файл tutorial.txt будет повторно прочитан и будет обнаружено, что он изменился, нам потребуется для этого файла повторно выполнить процедуру parse(). А что произойдет, если мы пересоздадим весь набор документов? Сможет ли система Contingent изучить весь процесс сборки?
>>> for filename in 'index.txt', 'tutorial.txt', 'api.txt':
... print(render(filename))
... print('=' * 30)
...
<h1>Table of Contents</h1>
<p>
* <a href="tutorial.txt">Beginners Tutorial</a>
* <a href="api.txt">API Reference</a>
<p>
==============================
<h1>Beginners Tutorial</h1>
<p>
Welcome to the tutorial!
We hope you enjoy it.
<p>
==============================
<h1>API Reference</h1>
<p>
You might want to read
the <a href="tutorial.txt">Beginners Tutorial</a> first.
<p>
==============================
Это сработало! Если посмотреть на результат, то можно видеть, что в результате наших преобразований названия документов были заменены с помощью директив, указанных в наших исходных документах, что указывает, что системе Contingent удалось обнаружить связи между различными задачами, необходимыми для создания наших документов.
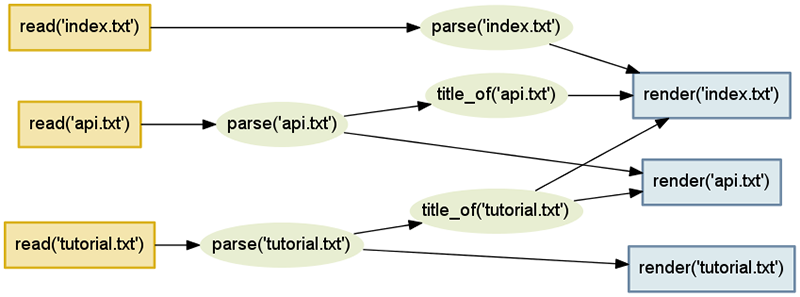
Рис.4.4. Полный набор взаимосвязей между нашими входными файлами и нашими выходными файлами в формате HTML.
Объект Project, наблюдая через механизм обертки задач task за тем, как одни задачи вызывают другие, автоматически изучит граф со входными документами и последовательностью действий. Поскольку в распоряжении системы Contingent имеется полный граф последовательностей действий, она будет знать о том, какие результирующие документы нужно будет пересобрать в случае, если будут изменены некоторые входные документы.
После того, как будет выполнена первоначальная сборка документов, системе Contingent необходимо будет следить за изменениями входных документов. После того, как пользователь закончит очередное редактирование документа и запустит команду "Сохранить", необходимо будет вызвать метод чтения read() и выбрать правильную последовательность действий.
Для этого нам потребуется пройти граф в обратном порядке начиная от одного из документов, который был создан. Как вы помните, он был построен с помощью выполнения задачи render() для документа API Reference, а метод read() был вызван в конце выполнения метода parse(). Теперь мы двигаемся в другом направлении: мы знаем, что теперь метод read()вернет другое содержимое, и нам нужно выяснить, на какие документы это в дальнейшем окажет влияние.
Процесс выявления последовательности действий является рекурсивным, так как каждое следующее действие может потребовать выполнения дополнительных задач, которые зависят от этого действия. Мы могли бы выполнить эту рекурсию вручную с помощью повторных обращений к графу. (Обратите внимание, что мы здесь, пользуясь тем, что в языке Python введенные команды сохраняют последнее полученное значение в переменной с именем _, которое можно будет использовать в последующих выражениях).
>>> task = Task(read, ('api.txt',))
>>> project._graph.immediate_consequences_of(task)
[parse('api.txt')]
>>> t1, = _
>>> project._graph.immediate_consequences_of(t1)
[render('api.txt'), title_of('api.txt')]
>>> t2, t3 = _
>>> project._graph.immediate_consequences_of(t2)
[]
>>> project._graph.immediate_consequences_of(t3)
[render('index.txt')]
>>> t4, = _
>>> project._graph.immediate_consequences_of(t4)
[]
Эта рекурсивная задача непрерывно выполняет поиск действий, которые нужно выполнить непосредственно за текущим действием, и останавливает свою работу только в том случае, когда для всех задач не будет таких действий; это базовая операция, выполнение которой осуществляется непосредственно с помощью метода, имеющегося в классе Graph:
>>> # Secretly adjust pprint to a narrower-than-usual width:
>>> _pprint = pprint
>>> pprint = lambda x: _pprint(x, width=40)
>>> pprint(project._graph.recursive_consequences_of([task]))
[parse('api.txt'),
render('api.txt'),
title_of('api.txt'),
render('index.txt')
На самом деле, метод recursive_consequences_of() пытается выполнить чуть более интеллектуально. Если некоторая задача повторно присутствует в последовательности действий подчиненных задач, то метод сообщает о первой задаче только один раз и перемещает ее ближе к концу списка с тем, чтобы она была указана только после того, как будут указаны все задачи, в которых она используется. Эта логика базируется на классической топологической сортировке в глубину, алгоритме, как оказывается, довольно легко написать на языке Python с помощью скрытой вспомогательной рекурсивной функции. Подробности смотрите в исходном коде graphlib.py.
Если, когда будет обнаружено изменение, мы аккуратно перезапустим каждую задачу в соответствие с рекурсивной последовательностью их вызовов, система Contingent сможет избежать ситуацию, когда восстановлено будет слишком мало. Однако наша вторая задача состоит в том, чтобы избежать ситуации, когда действий по восстановлению будет слишком много. Обратимся снова к рис.4.4. Мы хотим, чтобы каждый раз, когда меняется файл tutorial.txt, не восстанавливать все три документа, поскольку большинство изменений, вероятно, не будут влиять на заголовок документа, а будут влиять только на его содержимое. Как это можно достигнуть?
Решение состоит в том, чтобы создать граф пересборки, который будет зависеть кэширования. Когда мы будем двигаться на шаг вперед по рекурсивной последовательности изменений, мы будем вызывать только задачи, которые отличаются от тех, что вызывались в прошлый раз.
Такая оптимизация затронет окончательную структуру данных. Мы передадим объекту Project множество _todo, с помощью которого будем запомнить каждую задачу, для которой изменилось, по меньшей мере, одно входное значение, и которую, следовательно, необходимо выполнить повторно. Поскольку в множестве _todo указаны что только задачи, результат работы которых устарел, процесс сборки может пропускать выполнение некоторых задач, если они не указываются в этом множестве.
Опять же, удобный и унифицированный дизайн языка Python позволяет очень легко закодировать эти функции. Поскольку объекты задач хешируемые, множество _todo может быть просто множеством, элементы которое — задачи запоминаются по их идентификатору — это гарантирует, что задача никогда не появляется дважды — а _cache возвращаемых значений предыдущих запусков может быть словарем dict с указанием задач в качестве ключей.
Точнее, этап пересборки должен выполняться в цикле до тех пор, пока множество _todo не пусто. Во время каждого прохода по циклу должно выполняться следующее:
- Вызывается метод recursive_consequences_of() и в каждую задачу передается все, перечисленное в _todo. Возвращаемым результатом будет не только список для самих задач, указанных в _todo, но и для каждой задачи, до которой рекурсивно дойдет вызов - другими словами для каждой задачи, для которой может понадобиться повторное выполнение в случае, если на данный момент выдаваемый ей результат будет другим.
- Для каждой задачи, указанной в списке, проверяется, указана ли она в списке _todo. Если нет, то мы можем ее не запускать, поскольку ни одна из задач, которые мы заново вызвали перед ней, не привело к появлению нового возвращаемого значения, которое требует перевычисления этой задачи.
- Но для любой задачи, которая будет, на самом деле, указана в _todo к тому моменту времени, когда мы дойдем до ее выполнения, нам нужно выяснить, должны ли мы ее перезапускать и вновь вычислять возвращаемое ей значение. Если с помощью функции-обертки будет выяснено, что возвращаемое значение этой задачи не соответствует старому закэшированному значению, то прежде, чем мы доберемся до этой задачи в списке рекурсивных обращений, она будет автоматически добавлены к списку _todo.
К тому времени, когда мы достигнем конца списка, все задачи, которые, возможно, требуется повторно выполнить, будут уже, на самом деле, повторно выполнены. Но на всякий случай, мы проверим список _todo и повторим действия в случае, если он еще не пуст. Даже для очень быстро меняющихся деревьев зависимостей, он должен быть быстро исчерпан. Только для цикла, где, например, для задачи A требуются результат работы задачи B, для которой самой необходимы выходные данные задачи A, сборка может происходить в бесконечном цикле, причем в случае, если возвращаемые значения этих задач никогда не стабилизируются. К счастью, реальные задачи сборки, как правило, без циклов.
Давайте на примере проследим поведение этой системы.
Предположим, что вы отредактировали файл tutorial.txt и изменили содержимое как заголовка, так и тела контента. Мы можем смоделировать это, изменив значение в нашем словаре filesystem:
>>> filesystem['tutorial.txt'] = """ ... The Coder Tutorial ... ------------------ ... This is a new and improved ... introductory paragraph. ... """
Теперь, когда содержимое изменилось, мы можем попросить объект Project повторно запустить задачу read() при помощи его менеджера контекста cache_off(), который для данной задачи и данного аргумента временно отключает свою готовность вернуть старый закэшированный результат:
>>> with project.cache_off():
... text = read('tutorial.txt')
Теперь текст руководства будет считан в кэш. Сколько зависимых от этого изменения задач нужно будет теперь повторно выполнить?
Для того, чтобы помочь нам ответить на этот вопрос, в классе Project имеется простое средство, которое подскажет нам, какие задачи выполняются в процессе пересборки. Поскольку указанные выше изменения в файле tutorial.txt влияют как на тело, и на название, то нужно будет повторно выполнить все задачи:
>>> project.start_tracing()
>>> project.rebuild()
>>> print(project.stop_tracing())
calling parse('tutorial.txt')
calling render('tutorial.txt')
calling title_of('tutorial.txt')
calling render('api.txt')
calling render('index.txt')
Если вернуться обратно к рис.4.4, то можно увидеть, что, как и следовало ожидать, это будут все задачи, которая должны быть выполнены непосредственно или опосредовано за задачей read('tutorial.txt').
А что, если мы отредактируем этот файл снова, но на этот раз оставим заголовок тем же самым?
>>> filesystem['tutorial.txt'] = """
... The Coder Tutorial
... ------------------
... Welcome to the coder tutorial!
... It should be read top to bottom.
... """
>>> with project.cache_off():
... text = read('tutorial.txt')
Это небольшое ограниченное изменение не должно оказывать никакого влияния на другие документы.
>>> project.start_tracing()
>>> project.rebuild()
>>> print(project.stop_tracing())
calling parse('tutorial.txt')
calling render('tutorial.txt')
calling title_of('tutorial.txt')
Ура! Был пересобран только один документ. Тот факт, что задача title_of() для каждого нового входного документа возвращает, тем не менее, одно и то же значение, означает, что изменения не влияют на все задачи, идущие далее, и их не надо вызывать повторно вызова.
Перейти к следующей части статьи.
Перейти к началу статьи.