





Библиотека сайта rus-linux.net
SQLAlchemy
Глава 20 из книги "Архитектура приложений с открытым исходным кодом", том 2.Оригинал: SQLAlchemy
Автор: Michael Bayer
Перевод: А. Панин
20.7. Методы выполнения запросов и загрузки данных
Query. Стандартный процесс инициализации объекта Query начинается с включения примитивов (entites), которые формируют список классов, используемых для отображения и/или индивидуальных SQL-запросов, которые должны быть выполнены. Он также содержит ссылку на объект Session, который представляет соединение с одной или большим количеством баз данных, а также кэш данных, который был собран при осуществлении транзакций в ходе использования этих соединений. Ниже представлен элементарный пример использования этих объектов:
from sqlalchemy.orm import Session session = Session(engine) query = session.query(User)
Мы создаем объект Query, который использует экземпляры класса User, относящиеся к новому объекту сессии Session, который мы создали. Объект Query использует генеративный шаблон проектирования builder таким же образом, как и описанная ранее конструкция select, где дополнительные критерии и модификаторы ассоциировались с конструкциями выражений для выполнения одного вызова метода в каждый момент времени. Когда итеративная операция выполняется в отношении объекта Query, он создает конструкцию SQL-запроса SELECT, выполняет этот запрос с помощью базы данных, после чего интерпретирует результирующий набор строк как результирующие данные объектно-реляционного отображения в соответствии с набором изначально запрашиваемых элементов.
Объект Query производит жесткое разделение между частями операции, относящимися к формированию SQL-запросов (SQL rendering) и частями операции, относящимися к загрузке данных (data loading). Первый случай относится к созданию запроса SELECT, а второй - к интерпретации полученных после выполнения SQL-запроса строк как конструкций объектно-реляционного отображения. Фактически данные могут обрабатываться без выполнения шага, заключающегося в формировании SQL-запроса, так как объект Query может интерпретировать результаты выполнения текстового запроса, сформированного пользователем вручную.
И в процессе формирования SQL-запроса, и в процессе загрузки данных используется рекурсивный обход графа, образованного наборами объектов Mapper, причем каждый содержащий данные столбца или SQL-запроса объект ColumnProperty рассматривается как узел, а каждый объект RelationshipProperty, который включается в запрос с помощью так называемой стратегии "eager-load" - как ребро графа, ведущее к другой представленной объектом Mapper вершине. Обход и выполнение действия при достижении каждого из узлов в конечном счете является задачей каждого объекта LoaderStrategy, ассоциированного с каждым объектом MapperProperty, осуществляющим добавление столбцов и объединений к запросу SELECT, создаваемому на этапе формирования запроса и создающему функции языка Python для обработки результирующих строк на этапе загрузки данных.
Все функции языка Python, создающиеся на этапе загрузки данных, получают по строке из базы данных по мере извлечения и в результате производят возможные изменения состояния отображенного атрибута в памяти. Они создаются для определенного атрибута в соответствии с условием, базирующимся на исследовании первой строки из полученного набора результирующих данных, а так же на параметрах загрузки. Если загрузка атрибута не производится, пригодной для вызова функции не создается.
Рисунок 20.12 иллюстрирует обход нескольких объектов LoaderStrategy при сценарии загрузки данных в соответствии со стратегией "joined eager loading" с указанием на их объединение с формируемым SQL-запросом, который появляется в ходе вызова метода _compile_context объекта Query. На нем также показан процесс генерации функций обработки строк (row population functions), которые получают результирующие строки и задают отдельные атрибуты объектов, причем сам этот процесс инициируется с помощью метода instances объекта Query.
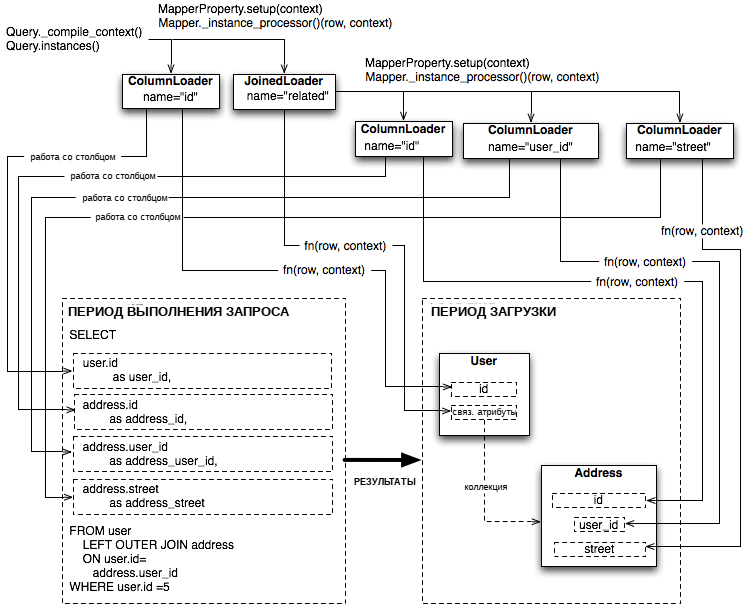
Рисунок 20.12: Обход объектов при использовании стратегий загрузки, включая стратегию "joined eager load"
Ранее в SQLAlchemy использовался подход, заключающийся в сборе результатов, полученных после вызовов фиксированных, ассоциированных с каждой стратегией методов объектов для получения каждой строки таблицы и выполнения соответствующих действий. Система загрузки с возможностью вызова функций была впервые представлена в версии 0.5 и позволила значительно повысить производительность системы, так как большое количество решений в отношении обработки строк таблицы могло быть принято прямо перед началом их обработки вместо повторного принятия решений для каждой строки, а также большое количество не имеющих эффекта вызовов функций могло быть устранено.
Продолжение статьи: Сессия и индивидуальное отображение