





Библиотека сайта rus-linux.net
ITK
Глава 9 из книги "Архитектура приложений с открытым исходным кодом", том 2.Оригинал: ITK
Авторы: Luis Ibanez, Brad King
Перевод: А.Панин
Конвейер данных
- Объединение фильтров: Фильтры изображений из набора могут быть объединены один с другим, составляя цепочку обработки, в рамках которой над исходными изображениями производится последовательность операций.
- Исследование эффекта от изменения параметров: Как только фильтры объединяются в цепочку, становится достаточно просто изменить параметры любого фильтра цепочки и исследовать эффект, оказываемый на результирующее изображение благодаря изменению этих параметров.
- Потоковая передача данных из памяти: Изображения большого размера могут быть обработаны путем модификации исключительно блоков изображения в каждый момент времени. Таким образом становится возможной обработка изображений большого размера, которые не могут быть размещены в оперативной памяти каким-либо образом.
На Рисунках 9.1 и 9.2 уже было продемонстрировано упрощенное представление конвейера данных с точки зрения обработки изображений. Фильтры изображений обычно имеют числовые параметры, которые используются для управления поведением фильтра. В любой момент, когда значение одного из числовых параметров фильтра изменяется, конвейер данных устанавливает отметку "устаревшее" для результирующего изображения и располагает информацией о том, что этот определенный фильтр и все фильтры после него, использовавшие его вывод, должны быть повторно применены к изображению. Эта возможность конвейера данных упрощает исследование эффекта от изменения параметров фильтров при использовании минимального объема вычислительных мощностей для проведения каждого эксперимента.
Процесс обновления данных конвейера может быть реализован таким образом, что в каждый момент времени будут обрабатываться только части изображений. Это необходимый механизм для поддержки функции потоковой передачи данных. На практике этот процесс контролируется путем внутренней передачи спецификации RequestRegion от следующего в цепочке фильтра к используемому. Это взаимодействие осуществляется с помощью внутреннего API и не раскрывается для разработчиков приложений.
Для рассмотрения более конкретного примера, предположим, что если фильтр размытия изображения Гаусса ожидает изображение разрешением 100x100 пикселей на входе, которое должно быть сформировано медианным фильтром изображения, то фильтр размытия может запросить у медианного фильтра создание только четверти изображения, которая будет представлена фрагментом размером 100x25 пикселей. Этот запрос впоследствии может быть передан дальше по цепочке с учетом того, что каждый промежуточный фильтр может добавить дополнительную границу к размеру фрагмента изображения для предоставления запрошенного выходного размера этого фрагмента. Потоковая передача данных будет рассмотрена более подробно ниже.
И изменение параметров заданного фильтра, и изменение определенного фрагмента изображения путем обработки с помощью фильтра приведут к установлению отметки "устаревшее" на результирующее изображение, указывающей на необходимость повторного использования заданного и всех следующих за ним в цепочке фильтров из состава конвейера данных.
Объекты процесса и данных
Для сохранения базовой структуры конвейера были спроектированы два основных типа объектов. Это DataObject и ProcessObject. Объект DataObject является абстракцией над классами для хранения данных; например, изображений и геометрических сеток. Объект ProcessObject является абстракцией над фильтрами изображений и фильтрами сеток, с помощью которых обрабатываются данные. Объекты ProcessObject принимают объекты DataObject в качестве исходных данных и проводят с ними какие-либо алгоритмические трансформации, подобные проиллюстрированным на Рисунке 9.2.
Объекты DataObject генерируются объектами ProcessObject. Эта цепочка обычно начинается с чтения данных для объекта DataObject с диска, например, с помощью объекта ImageFileReader, являющегося одним из типов объекта ProcessObject. Объект ProcessObject, создавший заданный объект DataObject, является единственным объектом, который может модифицировать данный объект DataObject. Этот результирующий объект DataObject объединен с входом другого объекта ProcessObject, находящегося далее в цепочке.
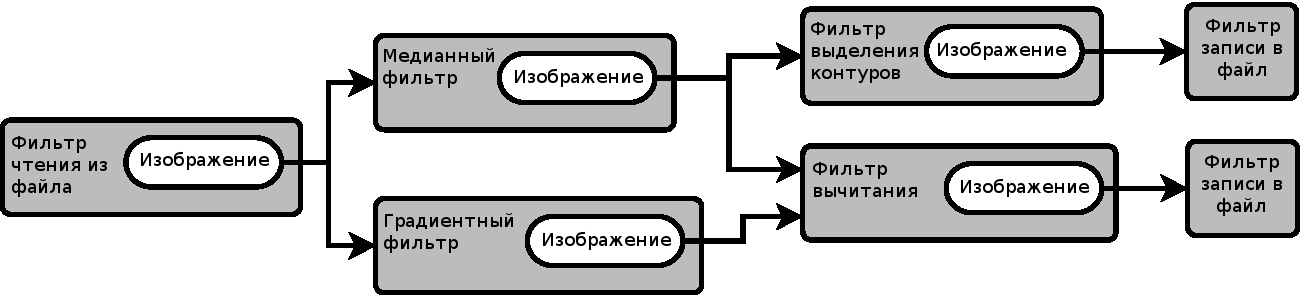
Рисунок 9.5: Взаимодействия между объектами ProcessObject и DataObject
Эта последовательность проиллюстрирована на Рисунке 9.5. Один и тот же объект DataObject может быть передан на вход множества объектов ProcessObject, как показано на рисунке, где объект DataObject создается путем чтения из файла в начале конвейера. В данном случае объект для чтения из файла является экземпляром класса ImageFileReader, а объект DataObject, создаваемый в результате чтения - экземпляром класса Image. Для некоторых фильтров также свойственно требовать по два объекта DataObject в качестве входных данных, как в случае фильтра вычитания, показанного в правой части того же рисунка.
ProcessObject и DataObject является побочным эффектом процесса формирования конвейера. С точки зрения разработчика приложений элементы конвейера связаны друг с другом путем использования последовательности вызовов, затрагивающих объекты ProcessObject и аналогичных следующим:
writer->SetInput ( canny->GetOutput() ); canny->SetInput ( median->GetOutput() ); median->SetInput ( reader->GetOutput() );
Однако, во внутреннем представлении результатом этих вызовов является не соединение объекта ProcessObject со следующим объектом ProcessObject, а объединение предыдущего объекта ProcessObject с объектом DataObject, созданным следующим объектом ProcessObject.
- Объект
ProcessObjectхранит список указателей на результирующие объектыDataObject. Результирующие объектыDataObjectнаходятся в распоряжении и контролируются объектомProcessObject, с помощью которого они были созданы. - Объект
ProcessObjectхранит список указателей на объектыDataObject, содержащие исходные данные. ОбъектыDataObject, содержащие исходные данные, находятся в распоряжении и контролируются предыдущим объектомProcessObject. - Объект
DataObjectхранит указатель на создавший его объектProcessObject. Следовательно, объектProcessObjectтакже владеет и контролирует объектDataObject.
Этот набор внутренних связей используется позднее для выполнения запросов к последующим и предыдущим фильтрам в рамках конвейера. В ходе всех этих взаимодействий объект ProcessObject удерживает контроль и распоряжается объектом DataObject, который он создал. Последующие фильтры получают доступ к информации о заданном объекте DataObject с помощью ссылок в форме указателей, которые создаются в результате вызовов методов SetInput() и GetOutput() без получения контроля над входными данными. В практических целях фильтры должны рассматривать входные данные как объекты, предназначенные только для чтения. Такое поведение устанавливается на уровне API с помощью ключевого слова const языка C++ для аргументов методов SetInput(). Как правило, в рамках ITK создается корректный в отношении констант внешний API, даже с учетом того, что во внутреннем представлении константы иногда переназначаются некоторыми операциями конвейера.
Продолжение статьи: Иерархия классов конвейера