





Библиотека сайта rus-linux.net
Масштабируемая Веб-архитектура и распределенные системы
Глава 1 из книги "Архитектура приложений с открытым исходным кодом", том 2.
Оригинал: "Scalable Web Architecture and Distributed Systems",
глава из книги "The Architecture
of Open Source Applications" том 2.
Автор: Кейт Мэтсудейра,
Перевод: © jedi-to-be. Коррекция:
Anastasiaf15,
sunshine_lass,
Amaliya,
fireball,
Goudron.
Перевод впервые был опубликован на сайте Хабрахабр
Балансировщики нагрузки
Наконец, другая критически важная часть любой распределенной системы - балансировщик нагрузки. Балансировщики нагрузки - основная часть любой архитектуры, поскольку их роль заключается в распределении нагрузки между узлами, ответственными за обслуживание запросов. Это позволяет множеству узлов прозрачно обслуживать одну и ту же функцию в системе. (См. рисунок 1.18.) Их основная цель состоит в том, чтобы обрабатывать много одновременных соединений и направлять эти соединения к одному из запрашиваемых узлов, позволяя системе масштабироваться, просто добавляя узлы, чтобы обслужить большее количество запросов.
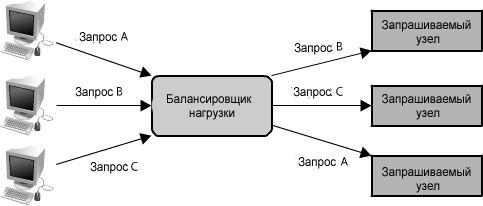
Рисунок 1.18: Балансировщик нагрузки
Существует много различных алгоритмов для обслуживания запросов, включая выбор случайного узла, циклического алгоритма или даже выбор узла на основе определенных критериев, таких как использование центрального процессора или оперативной памяти. Балансировщики нагрузки могут быть реализованы как аппаратные устройства или программное обеспечение. Среди балансировщиков нагрузки на программном обеспечении с открытым исходным кодом наиболее широкое распространение получил HAProxy.
В распределенной системе балансировщики нагрузки часто находятся на <переднем краю> системы, так что все входящие запросы проходят непосредственно через них. Весьма вероятно, что в сложной распределенной системе запросу придется пройти через несколько балансировщиков, как показано на
рисунке 1.19.
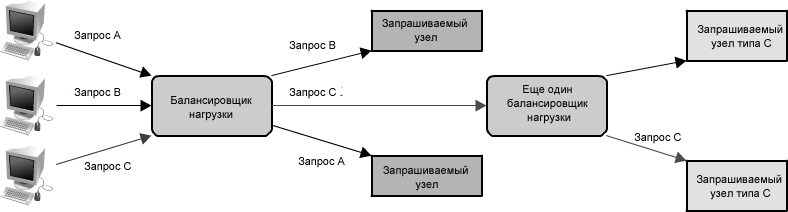
Рисунок 1.19: Множественные балансировщики нагрузки
Как и прокси, некоторые балансировщики нагрузки могут также направлять запросы по-разному, в зависимости от типа запроса. Они также известны как реверсивные (обратные) прокси.
Управление данными, специфичными для определенного сеанса пользователя, является одной из проблем при использовании балансировщиков нагрузок. На сайте электронной коммерции, когда у Вас есть только один клиент, очень просто позволить пользователям помещать вещи в свою корзину и сохранять ее содержимое между визитами (это важно, так как вероятность продажи товара значительно возрастает, если по возвращении пользователя на сайт, продукт все еще находится в его корзине). Однако если пользователь направлен к одному узлу для первого сеанса, и затем к другому узлу во время его следующего посещения, то могут возникать несоответствия, так как новый узел может не иметь данных относительно содержимого корзины этого пользователя. (Разве вы не расстроитесь, если поместите упаковку напитка Mountain Dew в Вашу корзину, и, когда вернетесь, ее там уже не будет?) Одно из решений может состоять в том, чтобы сделать сеансы <липкими>, так чтобы пользователь был всегда направлен к тому же узлу. Однако использование в своих интересах некоторых функций надежности, таких как автоматическая отказоустойчивость, будет существенно затруднено. В этом случае корзина пользователя всегда будет иметь содержание, но если их липкий узел станет недоступным, то будет необходим особый подход, и предположение о содержании корзины не будет больше верно (хотя, стоит надеяться, что это предположение не будет встроено в приложение). Конечно, данную проблему можно решить при помощи других стратегий и инструментов, как описанных в этой главе, таких как службы, так и многих других (как кэши браузера, cookie и перезапись URL).
Если у системы только несколько узлов, то такие приемы, как DNS-карусель, скорее всего окажутся более практичными, чем балансировщики загрузки, которые могут быть дорогими и увеличивать сложность системы добавлением ненужного уровня. Конечно, в больших системах есть все виды различных алгоритмов планирования и выравнивания нагрузки, включая как простые вроде случайного выбора или карусельного алгоритма, так и более сложные механизмы, которые принимают во внимание производительность особенности модели использования системы. Все эти алгоритмы позволяют распределить трафик и запросы, и могут обеспечить полезные инструменты надежности, такие как автоматическая отказоустойчивость или автоматическое удаление поврежденного узла (например, когда он перестает отвечать на запросы). Однако, эти расширенные функции могут сделать диагностику проблем громоздкой. Например, в ситуациях с высокой нагрузкой, балансировщики нагрузки будут удалять узлы, которые могут работать медленно или превышать время ожидания (из-за шквала запросов), что только усугубит ситуацию для других узлов. В этих случаях важен обширный контроль потому, что даже если кажется, что полный системный трафик и нагрузка снижаются (так как узлы обслуживают меньшее количество запросов) - отдельные узлы могут оказаться нагруженными до предела.
Балансировщики нагрузки - это простой способ нарастить мощность системы. Как и другие методы, описанные в этой статье, он играет существенную роль в архитектуре распределенной системы. Балансировщики нагрузки также обеспечивают критическую функцию проверки работоспособности узлов. Если по результатам такой проверки узел не отвечает или перегружен, то он может быть удален из пула обработки запросов, и, благодаря избыточности Вашей системы, нагрузка будет перераспределена между оставшимися рабочими узлами.
Очереди
До сих пор нами было рассмотрено множество способов быстрого считывания данных. В то же время еще одной важной частью масштабирования уровня данных является эффективное управление записями. Когда системы просты и характеризуются минимальными загрузками обработки и маленькими базами данных, запись может быть предсказуемо быстра. Однако, в более сложных системах данный процесс может занять неопределенно длительное время. Так, например, данные, возможно, придется записать в нескольких местах на различных серверах или индексах, или система может просто находится под высокой нагрузкой. В тех случаях, когда записи или даже просто любая задача занимают длительное время, достижение производительности и доступности требует встраивания асинхронности в систему. Распространенный способ сделать это - организовать очередь запросов.
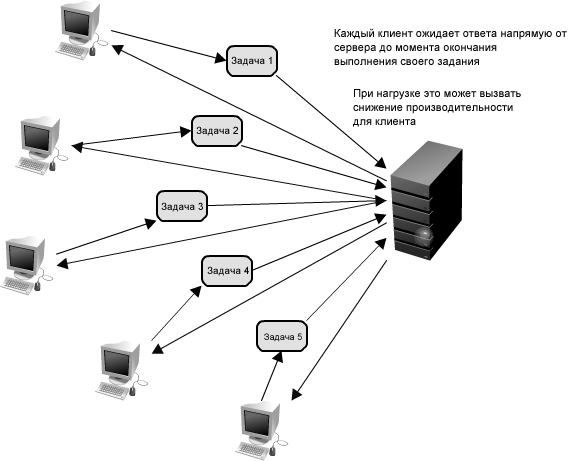
Рисунок 1.20: Синхронный запрос
Представьте себе систему, в которой каждый клиент запрашивает задачу удаленного обслуживания. Каждый из этих клиентов отправляет свой запрос серверу, который выполняет задачи как можно быстрее и возвращает их результаты соответствующим клиентам. В маленьких системах, где один сервер (или логическая служба) может обслуживать поступающих клиентов так же быстро, как они прибывают, ситуации такого рода должны работать нормально. Однако, когда сервер получает больше запросов, чем он может обработать, тогда каждый клиент вынужден ожидать завершения обработки запросов других клиентов, прежде чем ответ на его собственный запрос будет сгенерирован. Это - пример синхронного запроса, изображенного на рисунке 1.20.
Такой вид синхронного поведения может значительно ухудшить производительность клиента; фактически простаивая, клиент вынужден ожидать, пока не получит ответ на запрос. Добавление дополнительных серверов с целью справиться с нагрузкой системы, по сути, не решает проблемы; даже с эффективным выравниванием нагрузки на месте, чрезвычайно трудно обеспечить равномерное и справедливое распределение нагрузки необходимое для максимизации производительности клиента. Более того, если сервер для обработки этого запроса недоступен (или он вышел из строя), то клиент, подключенный к нему, также перестанет работать. Эффективное решение этой проблемы требует абстракции между запросом клиента и фактической работой, выполняемой для его обслуживания.
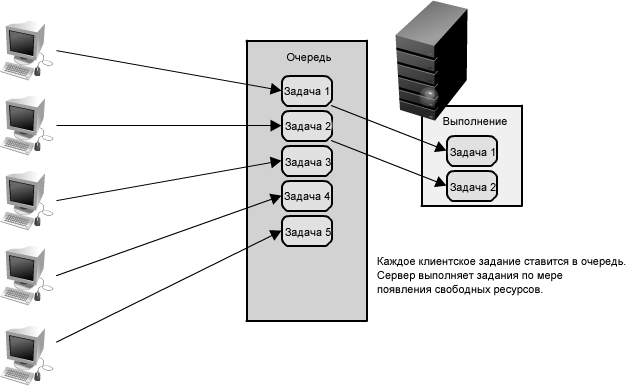
Рисунок 1.21: Использование очередей для управления запросами
Очереди входа. Механизм работы очереди очень прост: задача приходит, попадает в очередь, и затем <рабочие> принимают следующую задачу, как только у них появляется возможность обработать ее. (См. рисунок 1.21.) Эти задачи могут представлять собой простые записи в базу данных или что-то столь же сложное как генерация изображения предварительного просмотра для документа. Когда клиент отправляет запросы постановки задач в очередь, ему больше не требуется ожидать результатов выполнения; вместо этого запросы нуждаются только в подтверждении факта их получения должным образом. Это подтверждение может позже служить ссылкой на результаты работы, когда клиент затребует их.
Очереди позволяют клиентам работать асинхронным способом, обеспечивая стратегическую абстракцию запроса клиента и ответа на него. С другой стороны, в синхронной системе, нет никакого дифференцирования между запросом и ответом, и поэтому ими нельзя управлять отдельно. В асинхронной системе клиент ставит задачу, служба отвечает сообщением, подтверждая, что задача была получена, и затем клиент может периодически проверять состояние задачи, только запрашивая результат, как только это завершилось. В то время как клиент выполнения асинхронного запроса, он свободен для того, чтобы заниматься другой работой, и даже выполнять асинхронные запросы других служб. Последнее - это пример того, как очереди и сообщения работают в распределенных системах.
Очереди также обеспечивают некоторую защиту от приостановок обслуживания и отказов. Например, довольно просто создать очень устойчивую очередь, которая может повторить запросы на обслуживание, которые перестали работать из-за кратковременных отказов сервера. Более предпочтительно использовать очередь, чтобы реализовывать гарантии качества обслуживания, чем показывать клиентам временные перебои в работе сервиса, требуя сложной и часто противоречивой обработки ошибок на стороне клиентов.
Очереди - основной принцип в управлении распределенной передачей между различными частями любой крупномасштабной распределенной системы, и есть много способов реализовать их. Есть довольно много реализаций очередей с открытым исходным кодом как RabbitMQ, ActiveMQ, BeanstalkD, но некоторые также используют службы как Zookeeper, или даже хранилища данных как Redis.
1.4. Заключение
Разработка эффективных систем с быстрым доступом к большому количеству данных является очень интересной темой, и существует еще значительное число хороших инструментов, которые позволяют адаптировать все виды новых приложений. Эта глава коснулась всего лишь нескольких примеров, но в реальности их гораздо больше - и создание новых инноваций в этой области будет только продолжаться.
Эта работа распространяется под неизменённой лицензией Creative Commons Attribution 3.0. См. подробности в полном описании лицензии.
Далее: К началу статьи