





Библиотека сайта rus-linux.net
Масштабируемая Веб-архитектура и распределенные системы
Глава 1 из книги "Архитектура приложений с открытым исходным кодом", том 2.
Оригинал: "Scalable Web Architecture and Distributed Systems",
глава из книги "The Architecture
of Open Source Applications" том 2.
Автор: Кейт Мэтсудейра,
Перевод: © jedi-to-be. Коррекция:
Anastasiaf15,
sunshine_lass,
Amaliya,
fireball,
Goudron.
Перевод впервые был опубликован на сайте Хабрахабр
1.2 Основы
При рассмотрении архитектуры системы есть несколько вопросов, которые необходимо осветить, например: какие компоненты стоит использовать, как они совмещаются друг с другом, и на какие компромиссы можно пойти. Вложение денег в масштабирование без очевидной необходимости в ней не может считаться разумным деловым решением. Однако, некоторая предусмотрительность в планировании может существенно сэкономить время и ресурсы в будущем.
Данный раздел посвящается некоторым базовым факторам, которые являются важнейшими для почти всех больших веб-приложений: сервисы, избыточность, сегментирование, и обработка отказов. Каждый из этих факторов предполагает выбор и компромиссы, особенно в контексте принципов, описанных в предыдущем разделе. Для пояснения приведем пример.
Вообразите систему, где пользователи имеют возможность загрузить свои изображения на центральный сервер, и при этом изображения могут запрашиваться через ссылку на сайт или API, аналогично Flickr или Picasa. Для упрощения описания давайте предположим, что у этого приложения есть две основные задачи: возможность загружать (записывать) изображения на сервер и запрашивать изображения. Безусловно, эффективная загрузка является важным критерием, однако приоритетом будет быстрая доставка по запросу пользователей (например, изображения могут быть запрошены для отображения на веб-странице или другим приложением). Эта функциональность аналогична той, которую может обеспечить веб-сервер или граничный сервер Сети доставки контента (Content Delivery Network, CDN). Сервер CDN обычно хранит объекты данных во многих расположениях, таким образом, их географическое/физическое размещение оказывается ближе к пользователям, что приводит к росту производительности.
Другие важные аспекты системы:
Рисунок 1.1 представляет собой упрощенную схему функциональности.
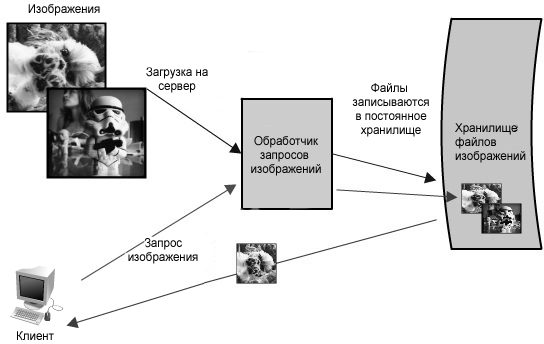
Рисунок 1.1: Упрощенная схема архитектуры для приложения хостинга изображений
В этом примере хостинга изображений система должна быть заметно быстрой, ее данные надежно сохранены, и все эти атрибуты хорошо масштабируемы. Создание небольшой версии этого приложения представляло бы из себя стандартную задачу, и для его размещения достаточно было бы единственного сервера. Однако, подобная ситуация не представляла бы интереса для данной главы. Давайте предположим, что нам необходимо создать что-то такое же масштабное, как Flickr.
Деконструкция системы на ряд комплементарных сервисов изолирует работу одних частей от других. Эта абстракция помогает устанавливать четкие отношения между службой, ее базовой средой и потребителями службы. Создание четкой схемы может помочь локализовать проблемы, но также и позволяет каждой части масштабироваться независимо друг от друга. Этот вид сервисно-ориентированного дизайна систем для обслуживания широкого круга запросов аналогичен объектно-ориентированному подходу в программировании.
В нашем примере все запросы загрузки и получения изображения обработаны одним и тем же сервером; однако, поскольку система должна масштабироваться, целесообразно выделить эти две функции в их собственные сервисы.
Предположим, что в будущем служба находится в интенсивном использовании; такой сценарий помогает лучше проследить, как более длительные записи влияют на время для считывания изображения (так как две функции будут конкурировать за совместно используемые ресурсы). В зависимости от архитектуры этот эффект может быть существенным. Даже если скорость отдачи и приема будут одинаковы (что не характерно для большинства сетей IP, поскольку они разработаны для соотношения скорости приема к скорости отдачи как минимум 3:1), считываемые файлы будут обычно извлекаться из кэша, и записи должны, в конечном счете, попасть на диск (и возможно подвергнуться многократной перезаписи в похожих ситуациях). Даже если все данные будут в памяти или читаться с дисков (таких как твердотельные диски SSD), то записи в базу данных почти всегда будут медленнее, чем чтения из нее. (Pole Position, инструмент с открытым исходным кодом для сравнительного тестирования баз данных, http://polepos.org/ и результаты http://polepos.sourceforge.net/results/PolePositionClientServer.pdf.).
Другая потенциальная проблема с этим дизайном состоит в том, что у веб-сервера, такого как Apache или lighttpd обычно существует верхний предел количества одновременных соединений, которые он в состоянии обслужить (значение по умолчанию - приблизительно 500, но оно может быть намного выше), и при высоком трафике записи могут быстро израсходовать этот предел. Так как чтения могут быть асинхронными или использовать в своих интересах другую оптимизацию производительности как gzip-сжатие или передача с делением на порции, веб-сервер может переключить чтения подачи быстрее и переключиться между клиентами, обслуживая гораздо больше запросов, чем максимальное число соединений (с Apache и максимальным количеством соединений, установленном в 500, вполне реально обслуживать несколько тысяч запросов чтения в секунду). Записи, с другой стороны, имеют тенденцию поддерживать открытое соединение на протяжении всего времени загрузки. Так передача файла размером 1 МБ на сервер могла занять больше 1 секунды в большинстве домашних сетей, в результате веб-сервер сможет обработать только 500 таких одновременных записей.
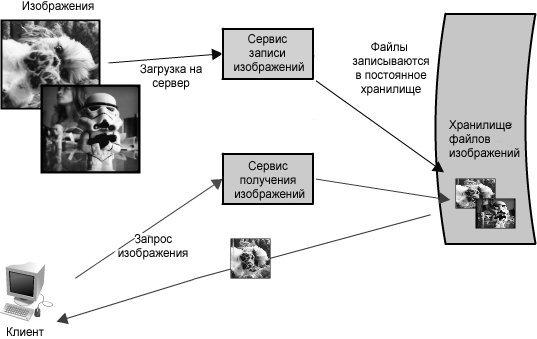
Рисунок 1.2: Разделение чтения и записи
Предвидение подобной потенциальной проблемы свидетельствует о необходимости разделения чтения и записи изображений в независимые службы, показанные на рисунке 1.2. Это позволит не только масштабировать каждую из них по отдельности (так как вероятно, что мы будем всегда делать больше чтений, чем записей), но и быть в курсе того, что происходит в каждой службе. Наконец, это разграничит проблемы способные возникнуть в будущем, что упростит диагностику и оценку проблемы медленного доступа на чтение.
Преимущество этого подхода состоит в том, что мы в состоянии решить проблемы независимо друг от друга - при этом нам не придется думать о необходимости записи и получении новых изображений в одном контексте. Обе из этих служб все еще используют глобальный корпус изображений, но при использовании методов соответствующих определенной службе, они способны оптимизировать свою собственную производительность (например, помещая запросы в очередь, или кэшируя популярные изображения - более подробно об этом речь пойдет далее). Как с точки зрения обслуживания, так и стоимости каждая служба может быть масштабирована независимо по мере необходимости. И это является положительным фактором, поскольку их объединение и смешивание могло бы непреднамеренно влиять на их производительность, как в сценарии, описанном выше.
Конечно, работа вышеупомянутой модели будет оптимальной, в случае наличия двух различных конечных точек (фактически, это очень похоже на несколько реализаций провайдеров "облачного" хранилища и Сетей доставки контента). Существует много способов решения подобных проблем, и в каждом случае можно найти компромисс.
К примеру, Flickr решает эту проблему чтения-записи, распределяя пользователи между разными модулями, таким образом, что каждый модуль может обслуживать только ограниченное число определенных пользователей, и когда количество пользователи увеличиваются, больше модулей добавляется к кластеру (см. презентацию масштабирования Flickr,
http://mysqldba.blogspot.com/2008/04/mysql-uc-2007-presentation-file.html). В первом примере проще масштабировать аппаратные средства на основе фактической нагрузки использования (число чтений и записей во всей системе), тогда как масштабировние Flickr просиходит на основе базы пользователей(однако, здесь используется предположение равномерного использования у разных пользователей, таким образом, мощность нужно планировать с запасом). В прошлом недоступность или проблема с одной из служб приводили в нерабочее состояние функциональность целой системы (например, никто не может записать файлы), тогда недоступность одного из модулей Flickr будет влиять только на пользователей, относящихся к нему. В первом примере проще выполнить операции с целым набором данных - например, обновляя службу записи, чтобы включить новые метаданные, или выполняя поиск по всем метаданным изображений - тогда как с архитектурой Flickr каждый модуль должен был быть подвергнут обновлению или поиску (или поисковая служба должна быть создана, чтобы сортировать те метаданные, которые фактически для этого и предназначены).
Что касается этих систем - не существует никакой панацеи, но всегда следует исходить из принципов, описанных в начале этой главы: определить системные потребности (нагрузка операциями "чтения" или "записи" или всем сразу, уровень параллелизма, запросы по наборам данных, диапазоны, сортировки, и т.д.), провести сравнительное эталонное тестирование различных альтернатив, понять условия потенциального сбоя системы и разработать комплексный план на случай возникновения отказа.
Данный раздел посвящается некоторым базовым факторам, которые являются важнейшими для почти всех больших веб-приложений: сервисы, избыточность, сегментирование, и обработка отказов. Каждый из этих факторов предполагает выбор и компромиссы, особенно в контексте принципов, описанных в предыдущем разделе. Для пояснения приведем пример.
Пример: Приложение хостинга изображений
Вы, вероятно, когда-либо уже размещали изображения в сети. Для больших сайтов, которые обеспечивают хранение и доставку множества изображений, есть проблемы в создании экономически эффективной, высоконадежной архитектуры, которая характеризуется низкими задержками ответов (быстрое извлечение).Вообразите систему, где пользователи имеют возможность загрузить свои изображения на центральный сервер, и при этом изображения могут запрашиваться через ссылку на сайт или API, аналогично Flickr или Picasa. Для упрощения описания давайте предположим, что у этого приложения есть две основные задачи: возможность загружать (записывать) изображения на сервер и запрашивать изображения. Безусловно, эффективная загрузка является важным критерием, однако приоритетом будет быстрая доставка по запросу пользователей (например, изображения могут быть запрошены для отображения на веб-странице или другим приложением). Эта функциональность аналогична той, которую может обеспечить веб-сервер или граничный сервер Сети доставки контента (Content Delivery Network, CDN). Сервер CDN обычно хранит объекты данных во многих расположениях, таким образом, их географическое/физическое размещение оказывается ближе к пользователям, что приводит к росту производительности.
Другие важные аспекты системы:
- Количество хранимых изображений может быть безгранично, таким образом, масштабируемость хранения необходимо рассматривать именно с этой точки зрения.
- Должна быть низкая задержка для загрузок/запросов изображения.
- Если пользователь загружает изображение на сервер, то его данные должны всегда оставаться целостными и доступными.
- Система должна быть простой в обслуживании (управляемость).
- Так как хостинг изображений не приносит большой прибыли, система должна быть экономически эффективной.
Рисунок 1.1 представляет собой упрощенную схему функциональности.
Рисунок 1.1: Упрощенная схема архитектуры для приложения хостинга изображений
В этом примере хостинга изображений система должна быть заметно быстрой, ее данные надежно сохранены, и все эти атрибуты хорошо масштабируемы. Создание небольшой версии этого приложения представляло бы из себя стандартную задачу, и для его размещения достаточно было бы единственного сервера. Однако, подобная ситуация не представляла бы интереса для данной главы. Давайте предположим, что нам необходимо создать что-то такое же масштабное, как Flickr.
Сервисы
При рассмотрении дизайна масштабируемой системы, бывает полезным разделить функциональность и подумать о каждой части системы как об отдельной службе с четко определенным интерфейсом. На практике считается, что системы разработанные таким образом имеют Service-Oriented Architecture (SOA). Для этих типов систем у каждой службы существует свой собственный отличный функциональный контекст, и взаимодействие с чем-либо за пределами этого контекста происходит через абстрактный интерфейс, обычно общедоступный API другой службы.Деконструкция системы на ряд комплементарных сервисов изолирует работу одних частей от других. Эта абстракция помогает устанавливать четкие отношения между службой, ее базовой средой и потребителями службы. Создание четкой схемы может помочь локализовать проблемы, но также и позволяет каждой части масштабироваться независимо друг от друга. Этот вид сервисно-ориентированного дизайна систем для обслуживания широкого круга запросов аналогичен объектно-ориентированному подходу в программировании.
В нашем примере все запросы загрузки и получения изображения обработаны одним и тем же сервером; однако, поскольку система должна масштабироваться, целесообразно выделить эти две функции в их собственные сервисы.
Предположим, что в будущем служба находится в интенсивном использовании; такой сценарий помогает лучше проследить, как более длительные записи влияют на время для считывания изображения (так как две функции будут конкурировать за совместно используемые ресурсы). В зависимости от архитектуры этот эффект может быть существенным. Даже если скорость отдачи и приема будут одинаковы (что не характерно для большинства сетей IP, поскольку они разработаны для соотношения скорости приема к скорости отдачи как минимум 3:1), считываемые файлы будут обычно извлекаться из кэша, и записи должны, в конечном счете, попасть на диск (и возможно подвергнуться многократной перезаписи в похожих ситуациях). Даже если все данные будут в памяти или читаться с дисков (таких как твердотельные диски SSD), то записи в базу данных почти всегда будут медленнее, чем чтения из нее. (Pole Position, инструмент с открытым исходным кодом для сравнительного тестирования баз данных, http://polepos.org/ и результаты http://polepos.sourceforge.net/results/PolePositionClientServer.pdf.).
Другая потенциальная проблема с этим дизайном состоит в том, что у веб-сервера, такого как Apache или lighttpd обычно существует верхний предел количества одновременных соединений, которые он в состоянии обслужить (значение по умолчанию - приблизительно 500, но оно может быть намного выше), и при высоком трафике записи могут быстро израсходовать этот предел. Так как чтения могут быть асинхронными или использовать в своих интересах другую оптимизацию производительности как gzip-сжатие или передача с делением на порции, веб-сервер может переключить чтения подачи быстрее и переключиться между клиентами, обслуживая гораздо больше запросов, чем максимальное число соединений (с Apache и максимальным количеством соединений, установленном в 500, вполне реально обслуживать несколько тысяч запросов чтения в секунду). Записи, с другой стороны, имеют тенденцию поддерживать открытое соединение на протяжении всего времени загрузки. Так передача файла размером 1 МБ на сервер могла занять больше 1 секунды в большинстве домашних сетей, в результате веб-сервер сможет обработать только 500 таких одновременных записей.
Рисунок 1.2: Разделение чтения и записи
Предвидение подобной потенциальной проблемы свидетельствует о необходимости разделения чтения и записи изображений в независимые службы, показанные на рисунке 1.2. Это позволит не только масштабировать каждую из них по отдельности (так как вероятно, что мы будем всегда делать больше чтений, чем записей), но и быть в курсе того, что происходит в каждой службе. Наконец, это разграничит проблемы способные возникнуть в будущем, что упростит диагностику и оценку проблемы медленного доступа на чтение.
Преимущество этого подхода состоит в том, что мы в состоянии решить проблемы независимо друг от друга - при этом нам не придется думать о необходимости записи и получении новых изображений в одном контексте. Обе из этих служб все еще используют глобальный корпус изображений, но при использовании методов соответствующих определенной службе, они способны оптимизировать свою собственную производительность (например, помещая запросы в очередь, или кэшируя популярные изображения - более подробно об этом речь пойдет далее). Как с точки зрения обслуживания, так и стоимости каждая служба может быть масштабирована независимо по мере необходимости. И это является положительным фактором, поскольку их объединение и смешивание могло бы непреднамеренно влиять на их производительность, как в сценарии, описанном выше.
Конечно, работа вышеупомянутой модели будет оптимальной, в случае наличия двух различных конечных точек (фактически, это очень похоже на несколько реализаций провайдеров "облачного" хранилища и Сетей доставки контента). Существует много способов решения подобных проблем, и в каждом случае можно найти компромисс.
К примеру, Flickr решает эту проблему чтения-записи, распределяя пользователи между разными модулями, таким образом, что каждый модуль может обслуживать только ограниченное число определенных пользователей, и когда количество пользователи увеличиваются, больше модулей добавляется к кластеру (см. презентацию масштабирования Flickr,
http://mysqldba.blogspot.com/2008/04/mysql-uc-2007-presentation-file.html). В первом примере проще масштабировать аппаратные средства на основе фактической нагрузки использования (число чтений и записей во всей системе), тогда как масштабировние Flickr просиходит на основе базы пользователей(однако, здесь используется предположение равномерного использования у разных пользователей, таким образом, мощность нужно планировать с запасом). В прошлом недоступность или проблема с одной из служб приводили в нерабочее состояние функциональность целой системы (например, никто не может записать файлы), тогда недоступность одного из модулей Flickr будет влиять только на пользователей, относящихся к нему. В первом примере проще выполнить операции с целым набором данных - например, обновляя службу записи, чтобы включить новые метаданные, или выполняя поиск по всем метаданным изображений - тогда как с архитектурой Flickr каждый модуль должен был быть подвергнут обновлению или поиску (или поисковая служба должна быть создана, чтобы сортировать те метаданные, которые фактически для этого и предназначены).
Что касается этих систем - не существует никакой панацеи, но всегда следует исходить из принципов, описанных в начале этой главы: определить системные потребности (нагрузка операциями "чтения" или "записи" или всем сразу, уровень параллелизма, запросы по наборам данных, диапазоны, сортировки, и т.д.), провести сравнительное эталонное тестирование различных альтернатив, понять условия потенциального сбоя системы и разработать комплексный план на случай возникновения отказа.
Далее: Избыточность