





Библиотека сайта rus-linux.net
Система VTK
Глава 24 из 1 тома книги "Архитектура приложений с открытым исходным кодом".
Оригинал: VTK, глава из книги "The Architecture of Open Source Applications" том 1.
Автор: Berk Geveci и Will Schroeder
Перевод: Н.Ромоданов
24.2.2. Представление данных
Одна из сильных сторон системы VTK является возможность с ее помощью представлять сложные формы данных. Эти формы данных варьируются от простых таблиц до сложных структур, таких как сетки конечных-элементов. Все эти формы данных являются подклассами класса vtkDataObject так, как это показано на рис.24.1 (обратите внимание, это частичная диаграмма наследования многие классы объектов данных).
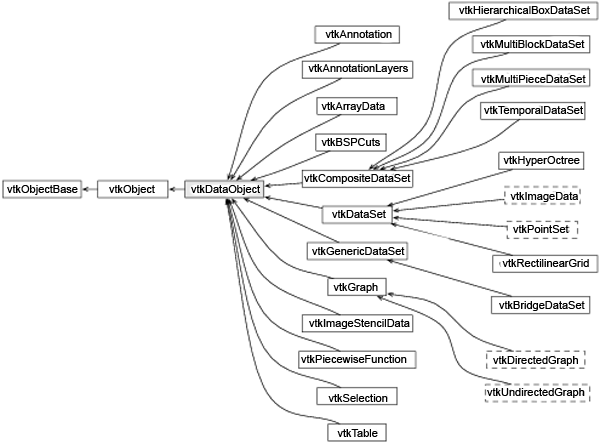
Рис.24.1: Классы объектов данных
Одной из наиболее важных характеристик класса vtkDataObject является то, что он может быть обработан в конвейере визуализации (следующий раздел). Среди многих показанных классов, есть только несколько, которые обычно используются в большинстве реальных приложений. Класс vtkDataSet и производные классы используются для научной визуализации (рис.24.2). Например, класс vtkPolyData используется для представления полигональных сеток; класс vtkUnstructuredGrid — для представления сеток, а класс vtkImageData - для представления двухмерных и трехмерных пиксельных и воксельных данных.
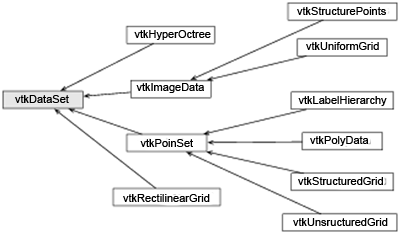
Рис.24.2: Классы наборов данных
24.2.3. Конвейерная архитектура
Система VTK состоит из нескольких основных подсистем. Вероятно, подсистема в большей мере ассоциируется с пакетами визуализации, с помощью которых формируется архитектуру потоков данных/конвейеров. Концептуально конвейерная архитектура состоит из трех основных классов объектов: объектов, используемых для представления данных (объекты класса vtkDataObject — смотрите выше), объектов, используемых для обработки, преобразования, фильтрации или отображения объектов данных из одной формы в другую (vtkAlgorithm), и объектов, используемых для работы конвейера (vtkExecutive), управление которым осуществляется согласно связному графу, в котором чередуются объекты данных и процессов (т.е. конвейеров). На рис.24.3 показан типичный конвейер.
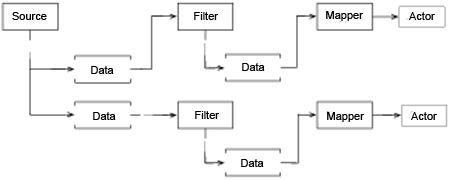
Рис.24.3: Типичный конвейер
Несмотря на концептуальную простоту, действительная реализация конвейерной архитектурой является сложной задачей. Одной из причин этого является то, что представление данных может быть сложным. Например, некоторые наборы данных состоят из иерархии или групп данных, поэтому для обработке всех данных потребуется нетривиальная итерация или рекурсия. Чтобы справиться с составной сложностью с помощью параллельной обработки (независимо от того, касается ли это совместно используемой памяти или масштабируемых подходов распределенной обработки), необходимо разбивать данных на части, причем может потребоваться, чтобы части перекрывались друг с другом с тем, чтобы можно было непрерывно вычислять граничную информацию, например, производные.
Объекты алгоритмов также вносят свои особые сложности. Для некоторых алгоритмов может потребоваться несколько входных потоков и / или они могут создавать несколько потоков выходных данных различных типов. Некоторые из них могут обрабатывать данные локально (например, вычислять центр ячейки), а для других требуется глобальная информация, например, при вычислении гистограммы. Во всех случаях, алгоритмы воспринимают свои входные данные как неизменяемые, они их только читают для того, чтобы создать свои выходные данные. Это связанно с тем, что данные могут предлагаться в качестве входных данных для нескольких алгоритмов, и будет не очень хорошо, когда один алгоритм будет портить входные данные другого алгоритма.
Наконец, сложность выполнения алгоритма может зависеть от конкретных особенностей стратегии выполнения. В некоторых случаях у нас есть возможность кэшировать промежуточные результаты, получаемые между фильтрами. Это в случае, если в конвейере что-то будет изменено, сведет к минимуму количество повторных расчетов, которые должны быть выполнены. С другой стороны, наборы данных, используемые для визуализации, могут быть огромными, и, в таком случае, мы, возможно, захотим избавиться от данных, если они больше не нужны для вычислений. Наконец, существуют сложные стратегии исполнения, например, обработка данных с несколькими вариантами точности, что требует, чтобы конвейер работал в итеративном режиме.
Чтобы продемонстрировать некоторые из этих концепций и затем объяснять конвейерную архитектуру, рассмотрим следующий пример на языке C++:
vtkPExodusIIReader *reader = vtkPExodusIIReader::New();
reader->SetFileName("exampleFile.exo");
vtkContourFilter *cont = vtkContourFilter::New();
cont->SetInputConnection(reader->GetOutputPort());
cont->SetNumberOfContours(1);
cont->SetValue(0, 200);
vtkQuadricDecimation *deci = vtkQuadricDecimation::New();
deci->SetInputConnection(cont->GetOutputPort());
deci->SetTargetReduction( 0.75 );
vtkXMLPolyDataWriter *writer = vtkXMLPolyDataWriter::New();
writer->SetInputConnection(deci->GetOuputPort());
writer->SetFileName("outputFile.vtp");
writer->Write();
В этом примере объект reader читает большой неструктурированный сеточный файл данных (или сетку). Следующий фильтр создает из сетки изоповерхность. Фильтр vtkQuadricDecimation уменьшает размер изоповерхности, которая является полигональным набором, уменьшая для этого количество составляющих элементов (т.е., уменьшая количество треугольников, представляющих собой изоконтур). Наконец, после прореживания новый файл с уменьшенным количеством данных записывается обратно на диск. Фактическая работа конвейера происходит тогда, когда объект writer вызывает метод Write (т.е. в момент запроса данных).
Как показано в этом примере, механизм выполнения конвейеров в системе VTK запускается при запросе данных. Когда некоторому процессу, например, объекту writer или mapper (объекту, осуществляющему рендеринг данных), требуются данные, он запрашивает их в качестве входа. Если во входном фильтре уже есть соответствующие данные, то фильтр просто возвращает управление выполнением в запрашиваемый процесс. Однако, если на входе нет соответствующих данных, их необходимо вычислить. Следовательно, нужно сначала запросить данных на вход. Этот процесс будет продолжаться в направлении, обратном движению данных по конвейеру, до тех пор, пока не будет достигнут фильтр или источник данных, у которого есть «соответствующие данные», или до тех пор, пока не будет достигнуто начало конвейера, после чего фильтры будут выполнены в правильном порядке, а данные поступят в то место конвейера, где они были запрошены.
Здесь следует пояснить, что означает «соответствующие данные». По умолчанию после того, как в VTK выполняется источник данных или фильтр, его выходные данные помещаются конвейером в кэш с тем, чтобы в будущем избежать ненужных вычислений. Это сделано для того, чтобы минимизировать количество вычислений и/или объем ввода/вывода за счет использования памяти, причем такое поведения является настраиваемым. В конвейере кэшируются не только объекты данных, но также метаданные об условиях, при которых эти объекты данных были получены. В этих метаданных есть метка времени (т.е. ComputeTime), которая создается в тот момент, когда объект данных был вычислен. Таким образом, в простейшем случае, «соответствующие данные» это такие данные, которые были вычислены после того, как были внесены изменения во все конвейерные объекты, находящиеся по конвейеру раньше конкретного места. Такое поведение проще продемонстрировать с помощью следующих примеров. Давайте в конце предыдущей программы VTK добавим следующие строки:
vtkXMLPolyDataWriter *writer2 = vtkXMLPolyDataWriter::New();
writer2->SetInputConnection(deci->GetOuputPort());
writer2->SetFileName("outputFile2.vtp");
writer2->Write();
Как объяснялось ранее, первый вызов writer->Write будет причиной того, что произойдет выполнение всего конвейера. Когда вызывается writer2->Write(), конвейер, когда он сравнит временную метку кэша со временем изменений прореживающего фильтра (deci), контурного фильтра и объекта reader, он поймет, что на выходе прореживающего фильтра находятся обновленные данные. Таким образом, запрос данных не должен распространяться ранее, чем до обращения к writer2. Теперь, давайте рассмотрим следующие изменения.
cont->SetValue(0, 400);
vtkXMLPolyDataWriter *writer2 = vtkXMLPolyDataWriter::New();
writer2->SetInputConnection(deci->GetOuputPort());
writer2->SetFileName("outputFile2.vtp");
writer2->Write();
Сейчас при выполнении конвейера будет понятно, что после того, как последний раз были вычислены выходные данные контурного и прореживающего фильтров, контурный фильтр был изменен. Таким образом, кэш для этих двух фильтров устарел, и эти фильтры должны быть вычислены повторно. Однако, поскольку объект reader, находящийся перед контурным фильтром, изменен не был, данные, находящиеся в его кэше, остаются действительными, и, следовательно, объект reader повторно выполняться не должен.
Сценарий, описанный здесь, является простейшим примером конвейера, выполнение которого осуществляется по запросу. Конвейер системы VTK является гораздо более сложным. Когда фильтру или процессу требуются данные, то может предоставляться дополнительная информация, указывающая конкретные подмножества данных. Например, фильтр может выполнять вспомогательный анализ, запрашивая только часть потока данных. Давайте для демонстрации изменим наш предыдущий пример.
vtkXMLPolyDataWriter *writer = vtkXMLPolyDataWriter::New();
writer->SetInputConnection(deci->GetOuputPort());
writer->SetNumberOfPieces(2);
writer->SetWritePiece(0);
writer->SetFileName("outputFile0.vtp");
writer->Write();
writer->SetWritePiece(1);
writer->SetFileName("outputFile1.vtp");
writer->Write();
Здесь объект writer делает запрос на загрузку и обработку двух частей потока данных, независимых друг от друга, который направляется к началу конвейера. Вы могли заметить, что простая логика выполнения, описанная ранее, здесь работать не будет. По этой логике когда функция Write вызывается во второй раз, конвейер не должен повторно осуществлять выполнение, т.к. ничего в начале конвейера не изменилось. Поэтому для решения этого более сложного случая, в механизме исполнения закладывается дополнительная логика, позволяющая обрабатывать частей запросов, таких как этот запрос. В действительности выполнение конвейера в системе VTK состоит из нескольких проходов. Вычисление объектов данных, на самом деле, является последним проходом. Проход, который был выполнен до этого, является запрашивающим проходом. Это тот проход, в котором потребители данных и фильтры могут сообщить в начало конвейера, что им нужно от предстоящего вычисления. В приведенном выше примере объект writer передаст на свой вход, что ему нужно часть с номером 0. Этот запрос будет, на самом деле, передан вплоть до объекта reader. Когда конвейер будет выполняться, reader будет знать, что он должен читать подмножества данных. Кроме того, в метаданных объекта будет запомнена информация о том, какая часть соответствующих данных закэширована. В следующий раз, когда фильтр запрашивает данные со своего входа, эти метаданные будут сравниваться с текущим запросом. Таким образом, в этом примере конвейер будет выполнять повторный пересчет с тем, чтобы обработать запрос других данных.
Есть несколько типов запросов, которые может делать фильтр. К ним относятся запросы конкретного шага по времени, конкретного структурного расширения или количества скрытых слоев (т.е. граничных слоев, необходимых для вычисления информации о соседних данных). Кроме того, во время запрашивающего прохода, каждый фильтр по мере того, как через него проходит запрос, может его изменять. Например, фильтр, который не в состоянии обрабатывать потоки (например, streamline фильтр) может игнорировать частичный запрос и может запросить все данные.
Продолжение статьи: Подсистема рендеринга