





Библиотека сайта rus-linux.net
Система VisTrails
Глава 23 из 1 тома книги "Архитектура приложений с открытым исходным кодом".
Оригинал: "VisTrails", глава из книги "The Architecture of Open Source Applications"Авторы: Juliana Freire, David Koop, Emanuele Santos, Carlos Scheidegger, Claudio Silva, and Huy T. Vo
Дата публикации: 2012 г.
Перевод: Н.Ромоданов
Дата перевода: март 2013 г.
Creative Commons. Перевод был сделан в соответствие с лицензией Creative Commons. С русским вариантом лицензии можно ознакомиться здесь.
23.3. Внутри системы VisTrails
На рис.23.3 показана схема архитектуры системы VisTrails, изображающая внутренние компоненты, в которых осуществляется поддержка функций пользовательского интерфейса, описанных вышеs. Выполнение рабочего процесса осуществляется под управлением движка Execution Engine, с помощью которого происходит отслеживание вызываемых операций и используемых с ними параметров и выполняется сохранение информации о ходе выполнения рабочего процесса (информация о происхождении данных в хоте выполнения процесса). Система VisTrails также позволяет во время выполнения процесса кэшировать промежуточные результаты в памяти и/или на диске. Как мы покажем в разделе 23.3, повторный запуск происходит только для новых комбинаций модулей и параметров, причем выполнение происходит с помощью обращений к функциям, лежащим глубже (например, к matplotlib). После этого результаты выполнения рабочего процесса вместе с исходными данными о происхождении данных могут добавляться в электронные документы (раздел 23.4).
Информация об изменениях в рабочих процессах накапливается в дереве версий Version Tree, которое может храниться в различных хранилищах данных, в том числе в хранилище файлов XML в локальном каталоге или в реляционной базе данных. В системе VisTrails также предоставляется механизм обработки запросов, который позволяет пользователям изучать информацию о происхождении данных.
Отметим, что, хотя система VisTrails была разработана как интерактивный инструмент, ее также можно использовать в режиме сервера. Как только рабочие процессы будут созданы, их можно будет выполнить на сервере VisTrails. Эта возможность полезна в ряде сценариев, в том числе при создании веб-интерфейса, в котором пользователям дается возможность взаимодействовать с рабочими процессами и запускать рабочие процессы в высокопроизводительных вычислительных средах.
23.3.1. Дерево версий: возможность выбора источника данных
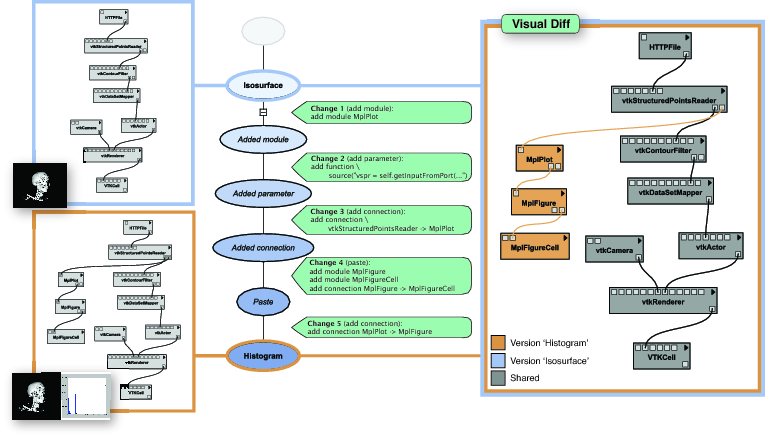
Рис.23.4: Модель происхождения, основанная на изменениях
Новой концепцией, которая была введена с системой VisTrails, является понятие происхождения эволюции рабочего процесса. В отличие от предыдущих систем визуализации, использующих или созданных основе рабочих процессов, в которых понятие происхождения поддерживается только для полученных результатов обработки данных, в системе VisTrails рабочие процессы трактуются как элементы данных первого порядка и сохраняется информация об их происхождении. Наличие понятия эволюции происхождения рабочего процесса поддерживает использование рефлексивных рассуждений. Пользователи могут сразу изучать большое количество цепочек рассуждений, не теряя при этом результатов, а поскольку система сохраняет промежуточные результаты, пользователи могут использовать эту информацию при рассуждениях и делать из нее выводы. В результате также появляется возможность выполнять серии операций, благодаря которым процессы исследований упрощаются. Например, пользователи могут легко перемещаться по пространству рабочих процессов, созданных для данной задачи, визуально сравнивать рабочие процессы и их результаты (смотрите рис 23.4), а также исследовать (огромные) пространства параметров. Кроме того, пользователи могут запрашивать информацию о происхождении и обучаться на собственных примерах.
Информация об эволюции рабочих потоков собирается при помощи модели происхождения, базирующейся на изменениях. Как показано на рисунке 23.4, в системе VisTrails операции или изменения, которые применяются к рабочим процессам (например, добавление модуля, изменение параметров и т. д.), хранятся точно также, как транзакции в журнале транзакций баз данных. Эта информация сохраняется в виде дерева, в котором каждый узел соответствует версии рабочего потока, а ребро между родительским и дочерним узлом, представляет собой изменение, которое было применено к родительскому узлу для того, чтобы получить дочерний узел. При рассмотрении этого дерева мы пользуемся терминами «дерево версий» и vistrail (сокращение от visual trail — визуальный след) как взаимозаменяемыми. Обратите внимание, что модель, базирующаяся на изменениях, одинаковым образом сохраняет изменения значений параметров и изменения определений рабочего потока. Такой последовательности изменений достаточно, чтобы определить происхождение получаемых результатов данных, а также собрать информацию том, как с течением времени развивается рабочий процесс. Модель проста и компактна — для нее требуется существенно меньше места, чем альтернативному варианту хранения нескольких версий рабочих потоков.
Есть ряд преимуществ, которые можно получить при использовании такой модели. На рис.23.4 показаны функциональные возможности визуального отображения различий, которые в системе VisTrails предоставляются при сравнении двух рабочих процессов. Хотя процессы представлены в виде графов, использующих модель, основанную на изменениях, сравнение двух рабочих процессов становится очень простым: достаточно пройти по дереву версий и идентифицировать последовательность действий, которая потребовалась бы для того, чтобы преобразовать один рабочий процесс в другой.
Другим важным преимуществом модели происхождения, основанной на изменениях, является то, что используемое дерево версий может использоваться в качестве механизма поддержки совместной работы. Поскольку разработка рабочих процессов является крайне сложной задачей, она часто требует участие в работе сразу нескольких пользователей. С помощью дерева версий не только предоставляется интуитивно понятный способ визуализации вклада различных пользователей (например, с помощью окрашивания узлов в зависимости от того, какой пользователь создал соответствующий рабочий процесс), но и благодаря однородности модели можно использовать простые алгоритмы, позволяющие синхронизировать изменения, выполняемыми многими пользователями.
Во время выполнения рабочего процесса можно легко собрать и сохранить информацию о происхождении данных. После того, как выполнение будет завершено, также важно сохранить взаимосвязь между полученными данными и информацией о их происхождении, т.е. о том, какой рабочий процесс, какие параметры и какие исходные файлы использовались для получения результирующих данных. Если файлы данных или информация о происхождении данных перемещаются или изменяются, то становится трудно найти данные, связанные с информацией о происхождении, или найти информацию о происхождении, связанную с данными. В системе VisTrails предоставляется механизм долговременного хранения данных, с помощью которого осуществляется управление входными, промежуточными и выходными файлами данных, а также сохраняется взаимосвязь между информацией о происхождении данных и данными. Этот механизм обеспечивает лучшую поддержку при выполнении повторных вычислений, поскольку с его помощью гарантируется, что можно найти данные (и они будут правильными), указываемые в информации о происхождении. Другим важным преимуществом такого управления является то, что есть возможность кэшировать промежуточные данные, к которым затем также могут обращаться другие пользователи.
23.3.2. Выполнение рабочего процесса, кэширование данных
Движок в системе VisTrails, предназначенный для выполнения рабочего процесса, был разработан таким образом, чтобы можно было интегрировать в систему новые и уже существующие инструментальные средства и библиотеки. Мы постарались учесть различные стили, обычно используемые при добавлении научного программного обеспечения, создаваемого сторонними разработчиками и предназначенного для визуализации и вычислений. В частности, система VisTrails может быть интегрирована с прикладными библиотеками, которые существуют либо в виде предварительно скомпилированных двоичных файлов, выполняются в оболочке и в качестве входа и выхода используют файлы, либо в виде библиотек классов языков C++ / Java / Python, которым в качестве входа и выхода передаются внутренние объекты.
В системе VisTrails адаптирована модель исполнения потоков данных, в которой каждый модуль выполняет вычисления и данные, создаваемые модулем, перемещаются по соединениям, которые существуют между модулями. Модули выполняются по принципу снизу-вверх; каждый набор входных данных создается по требованию путем рекурсивного выполнения модулей, находящихся выше (мы говорим, что модуль A находится выше модуля B, если есть последовательность соединений, ведущая от А к В). Промежуточные данные временно хранятся либо в памяти (как объект языка Python) или на диске (объект-оболочка на языке Python, в котором содержится информация о доступе к данным).
Чтобы разрешить пользователям добавлять в систему VisTrails свои собственные функции, мы собрали расширяемую систему пакетов (смотрите раздел 23.3). Система пакетов позволяет пользователям включать в рабочий процесс их собственные или сторонние модули. Разработчик пакета должен определить набор вычислительных модулей и для каждого модуля задать входные и выходные порты, а также определить само вычисление. Для существующих библиотек нужно, чтобы в методе вычисления был указан перевод из входных портов в параметры существующих функций и отображение результирующих значений в выходные порты.
В поисковых задачах, подобные рабочие процессы, которые совместно используют общие подструктуры, часто выполняются в строгой последовательности. Для того, чтобы повысить эффективность выполнения рабочего процесса, промежуточные результаты в системе VisTrails кэшируются с целью свести к минимуму повторные вычисления,. Поскольку мы повторно пользуемся предыдущими результатами вычислений, мы неявно предполагаем, что будут использоваться модули кэширования: для них то, что было на входе, будет и на выходе. Это требование накладывает определенные ограничения на поведение классов, но мы считаем, что они обоснованы.
Но есть очевидные ситуации, в которых такого поведения достигнуть не удается. Например, модуль, который загружает файл на удаленный сервер или сохраняет файл на диске, обладает существенным побочным эффектом, тогда то, что он выдает в качестве выходных данных, имеет сравнительно небольшое значение. В других модулях может использоваться рандомизация, и их недетерминизм может быть желательным; такие модули можно пометить как некэшируемые. Однако, некоторые модули, которые, в сущности, не являются функциональными, могут быть преобразованы; функция, которая записывает данные в два файла, может быть представлена как выдающая содержимое этих файлов.
Далее: 23.3.3. Сериализация и хранение данных