





Библиотека сайта rus-linux.net
LLVM
Глава 11 из книги "Архитектура приложений с открытым исходным кодом", том 1.
Оригинал: LLVM
Автор: Chris Lattner
Перевод: А.Панин
11.5. Архитектура многоцелевого генератора кода LLVM
Генератор кода LLVM преобразует код представления LLVM IR в машинный код для заданной целевой архитектуры. С другой стороны задачей генератора кода является формирование максимально качественного машинного кода для каждой из архитектур. В идеальном случае каждый генератор кода должен генерировать полностью отличающийся код для своей архитектуры, но с другой стороны генераторы кода для каждой целевой архитектуры решают аналогичные задачи. Например, каждая архитектура требует помещения значений в регистры и хотя каждая архитектура имеет отдельный файл со списком регистров, алгоритмы должны использоваться совместно там, где это возможно.
Аналогично подходу к реализации оптимизатора, генератор кода LLVM разделяет задачу по генерации кода на отдельные фазы - выбор инструкций, резервирование регистров, планирование использования регистров, оптимизация кода и генерация кода, а также предоставляет большое количество встроенных фаз, выполняющихся по умолчанию. Автор поддержки целевой архитектуры может выбрать стандартные фазы, заменить стандартные фазы или реализовать специфические для архитектуры фазы в случае необходимости. Например, система генерации кода для платформы x86 использует планирование распределения регистров, снижающее их использование, так как в данной архитектуре предусмотрено малое количество регистров, при этом система генерации кода для архитектуры PowerPC использует оптимизацию задержек, так как данная архитектура предусматривает большое количество регистров. Система генерации кода для архитектуры x86 использует специальную фазу генерации кода для обработки стека чисел с плавающей точкой x87, а система генерации кода для архитектуры ARM использует специальную фазу генерации кода для размещения наборов констант внутри функций по мере необходимости. Эта гибкость позволяет разработчикам систем генерации кода формировать качественный код без необходимости разработки с нуля всего генератора кода для их целевой архитектуры.
11.5.1. Файлы описания целевой архитектуры в LLVM
Техника "совмещения и сопоставления" позволяет разработчикам генераторов кода для архитектур выбирать необходимые для генерации кода действия и делает возможным повторное использование большого количества кода для разных архитектур. Из-за этого возникает еще одна сложность: каждый разделяемый между архитектурами компонент должен иметь возможность подстраиваться под свойства используемой архитектуры стандартным образом. Например, используемая в нескольких архитектурах система резервирования регистров должна иметь доступ к файлу описания регистров для каждой архитектуры и обладать информацией об условиях использования инструкций и их операндов совестно с регистрами. В LLVM используется решение, при котором для каждой целевой архитектуры создается описание на декларативном предметно-ориентированном языке программирования (набор файлов с расширением .td), обрабатываемое с помощью инструмента tblgen. Процесс генерации кода (упрощенный) для архитектуры x86 показан на Рисунке 11.5.
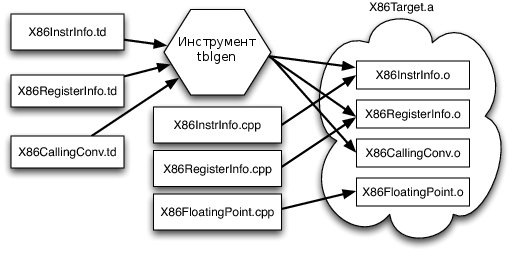
Рисунок 11.5: Упрощенный процесс генерации кода для целевой архитектуры x86
Различные подсистемы, поддерживаемые файлами с расширением .td позволяют разработчикам генераторов кода для разных архитектур последовательно обозначить особенности работы их архитектур. Например, система генерации кода для архитектуры x86 задает класс регистров, включающий в себя все 32-битные регистры и имеющий название "GR32" (в файлах с расширением .td специфичные для архитектуры объявления записываются заглавными буквами) следующим образом:
def GR32 : RegisterClass<[i32], 32,
[EAX, ECX, EDX, ESI, EDI, EBX, EBP, ESP,
R8D, R9D, R10D, R11D, R14D, R15D, R12D, R13D]> { ... }
Это объявление сообщает о том, что регистры этого класса могут хранить 32-битные целочисленные значения ("i32"), предпочтительно их выравнивание по границам 32 бит, всего класс содержит 16 регистров (которые объявлены в одном из файлов с расширением .td), а также приводятся дополнительные данные для установления порядка резервирования регистров и других параметров. После добавления этого объявления в файл, специфические инструкции могут ссылаться на него, используя его в качестве операнда. Например, инструкция для работы с 32-битными регистрами описывается следующим образом:
let Constraints = "$src = $dst" in
def NOT32r : I<0xF7, MRM2r,
(outs GR32:$dst), (ins GR32:$src),
"not{l}\t$dst",
[(set GR32:$dst, (not GR32:$src))]>;
Эта описание сообщает о том, что NOT32r является инструкцией (используется класс I tblgen), задается информация о кодировании (0xF7, MRM2r), задается объявленный для "вывода" 32-битный регистр с именем $dst и объявленный для "ввода" 32-битный регистр с именем $src (описанный выше класс регистров GR32 устанавливает, какие регистры могут использоваться для операндов), задается синтаксис ассемблера для инструкции (используется объявление () для поддержки и синтаксиса AT&T и синтаксиса Intel), задается результат выполнения инструкции и шаблон, с которым должно совпадать объявление, в последней строке. Условие "let" в первой строке сообщает системе резервирования регистров о том, что для ввода и вывода данных должен быть зарезервирован один и тот же физический регистр.
Это объявление является очень точным описанием инструкции, поэтому стандартный код LLVM может быть сформирован с учетом полученной из него информации (с помощью инструмента tblgen). Одного этого объявления достаточно для системы выбора инструкций чтобы сформировать эту инструкцию на основе проверки совпадения с шаблоном данных из из IR-представления, передаваемых компилятору. Данное объявление также сообщает системе резервирования регистров о том, как работать с данной инструкцией, чего вполне достаточно для кодирования и декодирования инструкции в формат машинного кода, а также достаточно для поиска и вывода инструкции в текстовой форме. Эти возможности позволяют использовать систему генерации кода для архитектуры x86 в качестве отдельного ассемблера x86 (который может быть заменой ассемблера "gas" от GNU) и дизассемблеров на основе описания целевой архитектуры, а также кодировать инструкцию для использования JIT.
В дополнение к полезным функциям, наличие нескольких экземпляров данных, полученных из одного и того же источника полезно и для других целей. Данный подход делает практически невозможным рассогласование между ассемблером и дизассемблером в плане синтаксиса ассемблера и бинарного кода. Также это позволяет проводить простое тестирование: кодирование инструкций может быть проверено с помощью unit-тестирования без использования всего генератора кода.
Хотя в файлах с расширением .td и должно быть собрано столько полезной информации в удобной декларативной форме, сколько возможно, ее не достаточно. Напротив, от разработчиков систем генерации кода для разных архитектур требуется разработка кода на языке C++ для реализации различных функций и специфических для данной архитектуры фаз генерации исходного кода, которые могут понадобиться (таких, как X86FloatPoint.cpp для работы со стеком чисел с плавающей точкой). Так как в составе LLVM появляется поддержка новых архитектур, все более и более важным становится повышение количества архитектур, которые могут быть описаны с помощью файлов с расширением .td, поэтому и проводится работа по увеличению количества данных в этих файлах. Большим достоинством этого подхода является тот факт, что разрабатывать системы генерации кода для различных архитектур с использованием LLVM со временем становится все проще.
Далее: 11.6. Интересные возможности, предоставляемые модульной архитектурой