Библиотека сайта rus-linux.net
API ядра Linux, Часть 2: Функции отложенного выполнения, тасклеты ядра и очереди работ
Оригинал: "Kernel APIs, Part 2: Deferrable functions, kernel tasklets, and work queues"Автор: M. Tim Jones
Дата публикации: 02 Mar 2010
Перевод: Н.Ромоданов
Дата перевода: 7 мая 2010 г.
Краткое содержание: Для высокоскоростных операций с потоками ядро Linux предлагает тасклеты и очереди работ. С помощью тасклетов и очередей работ реализуются функции отложенного исполнения, что заменяет старый механизм использования нижних половин в драйверах. В этой статье рассматривается использование в ядре тасклетов и очередей работ и показывается, как с помощью API этих конструктивов строить функции отложенного исполнения.
Версия ядра Linux
В настоящем обсуждении тасклетов и рабочих очередей используется ядро Linux версии 2.6.27.14.
В данной статье рассматривается несколько методов, используемых для выполнения отложенной обработки в контексте ядра (в частности, в ядре Linux 2.6.27.14). Хотя эти методы являются специфическими для ядра Linux, идеи, стоящие за ними, также полезные с архитектурной точки зрения. Например, вы могли бы реализовать эти идеи в традиционных встроенных системах вместо традиционного планировщика, используемого при планировании работ.
Однако перед тем, как начать рассматривать методы, используемые в ядре для создания функций отложенного исполнения, давайте обратимся к сути решаемой проблемы. Когда операционная система получает прерывания из-за некоторого аппаратного события (например, наличия пакета, поступившего через сетевой адаптер), обработка начинается в контексте прерывания. Обычно прерывание приводит к выполнению большого объема работы. Некоторая ее часть выполняется в контексте прерывания, а специальный структура work передается в программно реализованный стек для дальнейшей обработки (см. рис.1).
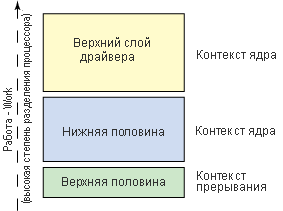
Рис.1. Обработка с использованием метода верхней и нижней половин
Как много работы должно быть сделано в контексте прерывания? Проблема, связанная с контекстом прерывания, состоит в том, что за это время могут быть отменены некоторые или все прерывания, что увеличивает латентность (время ожидания — прим.пер.) обработки других аппаратных событий (и вносит изменения в порядок выполнения обработки). Таким образом, желательно сводить к минимуму работу, выполняемую внутри прерывания, перенаправляя какое-то количество работы в контекст ядра (где существует более высокая вероятность использования разделяемых ресурсов процессора, что более выгодно).
Как показано на рис. 1, обработка, выполняемая в контексте прерывания, называется верхней половиной top half, а обработка прерывания, которая вытесняется из контекста прерывания, называется нижней половиной bottom half (в этом случае в верхней половине планируется обработка, выполняемая нижней половиной). Обработка, выполняемой нижней половиной, осуществляется в контексте ядра, что означает, что прерывания разрешены. Это приводит к более высокой производительности, поскольку появляется возможность быстрой реакции на высокоскоростные прерываний благодаря тому, что откладывается работа, для которой время, когда она будет выполнена, несущественно.
Краткая история метода нижней половины
Linux, по своей функциональности, все больше походит на универсальный швейцарский армейский нож, и функциональность, касающаяся отложенного исполнения, не противоречит этой тенденции. Начиная с ядра 2.3 стали доступны softirq-функции, в которых реализуется набор из 32 статически определенных конструктивов нижней половины. Как статические элементы, они определялись во время компиляции (в отличие от новых механизмов, которые являются динамическими). Softirq-функции использовались в контексте потока ядра для выполнения обработки, критичной по времени (программные прерывания). Вы можете найти исходный код softirq-функций в файле ./kernel/softirq.c. Также нововведением, сделанном в ядре Linux 2.3, были тасклеты (tasklets, см. в ./include/linux/interrupt.h). Тасклеты базируются на softirq-функциях и позволяют динамически создавать функции отложенного исполнения. Наконец, в ядре Linux 2,5, были введены очереди работ (work queues , см. в ./include/linux/workqueue.h). Очереди работ помогают управлять работами, которые были отложены из контекста прерывания в контексте процесса ядра.
Теперь давайте изучим динамические механизмы для работы с отложенным исполнением, тасклетами и очередями работ.
Введение в тасклеты
Softirq-функции изначально были созданы в виде вектора из 32 записей softirq, поддерживающих разнообразные программные прерывания. Сегодня только девять векторов используются для softirqs, один из которых TASKLET_SOFTIRQ (см. ./include/linux/interrupt.h). И хотя softirqs-функции все еще существуют в ядре, рекомендуется использовать тасклеты и рабочие очереди вместо размещения новых векторов softirq.
Тасклеты являются структурами отложенного исполнения, которые вы можете запланировать на запуск позже в виде зарегистрированных функций. Верхняя половина (обработчик прерываний) выполняет небольшой объем работ, а затем планирует тасклеты, которые будут выполнены позже в нижней половине.
Листинг 1. Объявление и планирование работы тасклета
/* Declare a Tasklet (the Bottom-Half) */ void tasklet_function( unsigned long data ); DECLARE_TASKLET( tasklet_example, tasklet_function, tasklet_data ); ... /* Schedule the Bottom-Half */ tasklet_schedule( &tasklet_example );
Конкретный тасклет будет работать только на одном процессоре (для которого он запланирован), и один и тот же тасклет никогда не будет работать более чем на одном заданном процессоре одновременно. Но различные тасклеты могут одновременно работать на разных процессорах.
Тасклеты представлены в виде структуры tasklet_struct (см. рис.2), в которой содержатся все данные, необходимые для управления тасклетом и поддержания его работы (состояние, включение/отключение с помощью функции atomic_t, указатель на функцию, данные и ссылка на связанный список).
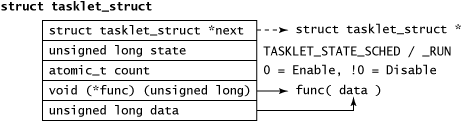
Рис.2. Внутренняя организация структуры tasklet_struct
Планирование исполнения тасклетов осуществляется с помощью механизма softirq, иногда, когда машина сильно загружена обработкой программных прерываний, через демон ksoftirqd (распределяющий поток ядра по процессорам). В следующем разделе мы рассмотрим разнообразные функции, имеющиеся в интерфейсе программирования прикладного программного обеспечения для тасклетов (tasklets API).
Наследие встроенных систем
Идеи, лежащие в основе использования тасклетов и очередей работ, были, в некотором смысле, унаследованы из встроенных систем. Во многих встроенных системах нет традиционного планировщика, а работа просто откладывается на более поздний срок (выполняется на уровне ввода/вывода или на уровне внутренней обработки). Из-за того, что планировщик отсутствует, прерывания и приложения осуществляют откладывание работы в качестве средства планирования работ, которые будут позже выполнены другими элементами системы. В этот случае планировщиком становится обработчик очередей работ (передающий работу обрабатывающим функциям) или битовые маски (которые указывают возможность тасклетов выполнять свою работу).
API для тасклетов
Тасклеты определяются с помощью макроса, называемого
DECLARE_TASKLET (см. листинг 2). Ниже этот макрос просто выполняет инициализацию структуры tasklet_struct в соответствие с предоставленной вами информацией (имя тасклета, функция и данные, конкретные для тасклета). По умолчанию, тасклет включен, что означает, что может быть запланировано его выполнение. С помощью макроса DECLARE_TASKLET_DISABLED тасклет также можно объявить как выключенный по умолчанию. Это потребует вызвать функцию tasklet_enable для того, чтобы можно было планировать его исполнение. Вы можете включать и отключать тасклет (в соответствие с планируемым исполнением), используя для этого соответственно функции tasklet_enable и tasklet_disable. Также существует функция tasklet_init, которая инициализирует структуру tasklet_struct в соответствие с данными, предоставленными пользователем.
Листинг 2. Создание тасклетов и функции включения/отключения
DECLARE_TASKLET( name, func, data );
DECLARE_TASKLET_DISABLED( name, func, data);
void tasklet_init( struct tasklet_struct *, void (*func)(unsigned long),
unsigned long data );
void tasklet_disable_nosync( struct tasklet_struct * );
void tasklet_disable( struct tasklet_struct * );
void tasklet_enable( struct tasklet_struct * );
void tasklet_hi_enable( struct tasklet_struct * );
Есть две функции отключения, каждая из которых посылает запрос на отключение, но только функция tasklet_disable возвращает управление после того, как тасклет будет завершен (а функция tasklet_disable_nosync может вернуть управление раньше, чем произойдет завершение). Функции отключения позволяют сделать тасклет "замаскированным" (то есть, неисполняемым) до тех пор, пока не будут вызваны функции включения. Также существуют две функции включения: одна — для планирования с нормальным приоритетом (tasklet_enable) и одна - для включения планирования с более высоким приоритетом (tasklet_hi_enable). Планирование с нормальным приоритетом обрабатывается softirq-функцией уровня TASKLET_SOFTIRQ, тогда как высокий приоритет - softirq-функцией уровня HI_SOFTIRQ.
Как и в случае функций включения с нормальным и высоким приоритетом, есть функции планирования с нормальным и высоким приоритетом (см. листинг 3). Каждая функция помещает тасклет в конкретный вектора softirq (tasklet_vec для нормального приоритета и tasklet_hi_vec высокого приоритета). Тасклеты из вектора с высоким приоритетом обслуживаются первыми, а затем — из вектора с нормальным приоритетом. Заметим, что для каждого процессора есть собственные вектора softirq с нормальным и высоким приоритетами.
Листинг 3. Функции планирования тасклетов
void tasklet_schedule( struct tasklet_struct * ); void tasklet_hi_schedule( struct tasklet_struct * );
Наконец, после того, как тасклет будет создан, его можно остановить при помощи функций tasklet_kill (см. листинг 4). Функция tasklet_kill обеспечивает,что тасклет не будет снова работать, а если в текущий момент тасклет планируется для выполнения, то функция будет ждать его завершения, а затем уничтожит тасклет. Функция tasklet_kill_immediate используется только когда процессор находится в тупиковом состоянии.
void tasklet_kill( struct tasklet_struct * ); void tasklet_kill_immediate( struct tasklet_struct *, unsigned int cpu );
Познакомившись с API, вы видите, что API для тасклетов простое и реализовано. Вы можете найти реализацию механизма тасклетов в файлах ./kernel/softirq.c и ./include/linux/interrupt.h.
Простой пример тасклета
Давайте рассмотрим простое использовании API тасклетов (см. листинг 5). Как здесь показано, при создании функции тасклета используются соответствующие данные (my_tasklet_function и my_tasklet_data), который затем используется при объявлении нового тасклета с помощью макроса DECLARE_TASKLET. Когда модуль вставляется, то планируется исполнение тасклета, что делает его исполняемым в определенный момент в будущем. Когда модуль выгружается, вызывается функция tasklet_kill для того, чтобы изъять тасклет из состояния запланированного исполнения.
Листинг 5. Простой пример тасклета в контексте модуля я
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/interrupt.h>
MODULE_LICENSE("GPL");
char my_tasklet_data[]="my_tasklet_function was called";
/* Bottom Half Function */
void my_tasklet_function( unsigned long data )
{
printk( "%s\n", (char *)data );
return;
}
DECLARE_TASKLET( my_tasklet, my_tasklet_function,
(unsigned long) &my_tasklet_data );
int init_module( void )
{
/* Schedule the Bottom Half */
tasklet_schedule( &my_tasklet );
return 0;
}
void cleanup_module( void )
{
/* Stop the tasklet before we exit */
tasklet_kill( &my_tasklet );
return;
}
Введение в очереди работ
Очереди работ являются совсем недавним механизмом отложенного исполнения, который был добавлен в версии 2.5 ядра Linux. Вместо того, чтобы предлагать однократную схему отложенного исполнения, как в случае с тасклетами, очереди работ являются обобщенным механизмом отложенного исполнения, в котором функция обработчика, используемая для очереди работ, может "засыпать" (что невозможно в модели тасклетов). Очереди работ могут иметь более высокую латентность, чем тасклеты, но они имеют более богатое API для отложенного исполнения работ. Управление отложенным исполнением раньше осуществлялось точно также, как очередями задач с помощью keventd, но теперь управление осуществляется при помощи рабочих потоков ядра, имеющих имена events/X.
В очередях работ предлагается обобщенный механизм, в котором отсроченная функциональность переносится в механизмы выполнения нижних половин. В основе лежит очередь работ (структура workqueue_struct), который является структурой, в которую помещается данные объект work. Работа (т.е. объект work) представлена структурой work_struct, в которой идентифицируется работа, исполнение которой откладывается, и функция отложенного исполнения, которая будет при этом использоваться (см. рис. 3). Потоки ядра events/X (по одному на процессор) выбирают работу (т.е. объект work) из очереди работ и активируют один из обработчиков нижней половины (как указано в функции обработчика в структуре work_struct).
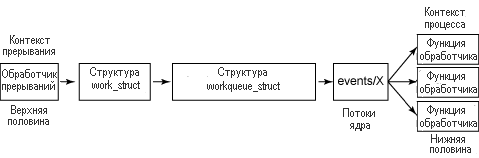
Рис.3. Процесс, стоящий за очередями работ
Поскольку в структуре work_struct указывается, какую следует использовать функцию обработчика, вы можете обрабатывать очередь работ любыми обработчиками очередей. Теперь давайте рассмотрим функции API, которые можно использовать для очередей работ.
API для очередей работ
API для очередей работ немного более сложное, чем для тасклетов, главным образом потому, что поддерживается использование различных возможностей. Давайте сначала изучим очереди работ, а затем рассмотрим на практике и эти возможности.
Вспомним из рис.3, что основная структура для очереди работ сама является очередью. Эта структура используется при обработке очередей механизмом верхней половины, где планируются отложенные действия, передаваемые в нижнию половину на последующее исполнение. Очередь работ создается с помощью макроса с именем create_workqueue, который возвращает ссылку на workqueue_struct. Вы позже сможете удалить (при необходимости) эту очередь работ с помощью вызова функции destroy_workqueue:
struct workqueue_struct *create_workqueue( name ); void destroy_workqueue( struct workqueue_struct * );
Работа (т.е. объект work), которая должна быть передана через очередь работ, определяется структурой work_struct. Как правило, эта структура является первым элементом пользовательской структуры, определяющей работу (ниже вы увидите пример). В API для очередей работ предлагается три функции для инициализации работы (из размещаемого буфера); см. листинг 6. Всю необходимую инициализацию и настройку функции обработчика (передаваемую пользователем) обеспечивает макрос INIT_WORK. В случаях, когда нужно сделать задержку прежде, чем работа будет поставлена в очереди работ, вы можете использовать макросы INIT_DELAYED_WORK и INIT_DELAYED_WORK_DEFERRABLE.
Листинг 6. Макросы инициализации очередей работ
INIT_WORK( work, func ); INIT_DELAYED_WORK( work, func ); INIT_DELAYED_WORK_DEFERRABLE( work, func );
После того, как будет инициализирована структура для объекта work, следующим шагом будет помещение этой структуры в очередь работ. Вы можете сделать это несколькими способами (см. листинг 7). Во-первых, просто добавить работу (объект work) в очередь работ с помощью функции queue_work (которая назначает работу текущему процессору). Либо вы можете с помощью функции queue_work_on указать процессор, на котором будет выполняться обработчик. Две дополнительные функции обеспечивают те же функции для отложенной работы (в которой инкапсулирована структура work_struct и таймер, определяющий задержку).
Листинг 7. Функции очередей работ
int queue_work( struct workqueue_struct *wq, struct work_struct *work );
int queue_work_on( int cpu, struct workqueue_struct *wq, struct work_struct *work );
int queue_delayed_work( struct workqueue_struct *wq,
struct delayed_work *dwork, unsigned long delay );
int queue_delayed_work_on( int cpu, struct workqueue_struct *wq,
struct delayed_work *dwork, unsigned long delay );
Вы можете использовать глобальное ядро - глобальную очередь работ с четырьмя функциями, которые работают с этой очередью работ. Эти функции (см. листинг 8) имитируют функции из листинга 7, за исключением лишь того, что вам не нужно определять структуру очереди работ.
Листинг 8. Функции для глобальной очереди работ
int schedule_work( struct work_struct *work );
int schedule_work_on( int cpu, struct work_struct *work );
int scheduled_delayed_work( struct delayed_work *dwork, unsigned long delay );
int scheduled_delayed_work_on(
int cpu, struct delayed_work *dwork, unsigned long delay );
Есть также целый ряд вспомогательных функций, которые можно использовать, чтобы принудительно завершить (flush) или отменить работу из очереди работ. Для того, чтобы принудительно завершить конкретный элемент work и блокировать прочую обработку прежде, чем работа будет закончена, вы можете использовать функцию flush_work. Все работы в данной очереди работ могут быть принудительно завершены с помощью функции flush_workqueue. В обоих случаях вызывающий блок блокируется до тех пор, пока операция не будет завершена. Для того, чтобы принудительно завершить глобальную очередь работ ядра, вызовите функцию flush_scheduled_work.
int flush_work( struct work_struct *work ); int flush_workqueue( struct workqueue_struct *wq ); void flush_scheduled_work( void );
Вы можете отменить работу, если она еще не выполнена обработчиком. Обращение к функции cancel_work_sync завершит работу в очереди, либо возникнет блокировка до тех пор, пока не будет завершен обратный вызов (если работа уже выполняется обработчиком). Если работа отложена, вы можете использовать вызов функции cancel_delayed_work_sync.
int cancel_work_sync( struct work_struct *work ); int cancel_delayed_work_sync( struct delayed_work *dwork );
Наконец, вы можете выяснить приостановлен ли элемент work (еще не обработан обработчиком) с помощью обращения к функции work_pending или delayed_work_pending.
work_pending( work ); delayed_work_pending( work );
Это основная часть API очередей работ. Вы можете посмотреть реализацию API очередей работ в файле ./kernel/workqueue.c, а определения API в файле ./include/linux/workqueue.h. Давайте теперь перейдем к рассмотрению простого примера использования API очередей работ.
Простой пример очереди работ
В следующем примере иллюстрируются несколько основных функций API очередей работ. Как и в примере с тасклетами, этот пример для простоты рассмотрения будет реализован в контексте модуля ядра.
Во-первых, взглянем на вашу структуру work и функцию обработчика, что вы будете реализовывать в качестве нижней половины (см. листинг 9). Первое, на что вам здесь следует обратить внимание, это ссылка на определение структуры вашей очереди работ (my_wq) и определение my_work_t. Определение типа my_work_t включает в себя структуру work_struct, которая находится в голове очереди, и целое число, которое представляет собой ваш элемент работы work. Ваш обработчик (функция обратного вызова) получает доступ по указателю work_struct к типу данных my_work_t. После того, как будет получен экземпляр работы work (целое число из структуры), указатель на объект work будет освобожден.
Листинг 9. Рабочая структура work и обработчик нижней половины
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/workqueue.h>
MODULE_LICENSE("GPL");
static struct workqueue_struct *my_wq;
typedef struct {
struct work_struct my_work;
int x;
} my_work_t;
my_work_t *work, *work2;
static void my_wq_function( struct work_struct *work)
{
my_work_t *my_work = (my_work_t *)work;
printk( "my_work.x %d\n", my_work->x );
kfree( (void *)work );
return;
}
В листинге 10 приведена ваша функция init_module, которая начинается с создания очереди работ, для чего используется функция API create_workqueue. После успешного создания очереди работ, вы создаете два элемента работ work (размещаются в памяти с помощью kmalloc). Затем каждый элемент работ work инициализируется с помощью INIT_WORK, определяется работа work, а затем с помощью вызова функции queue_work работа помещается в очередь работ. Затем завершается процесс верхней половины (здесь имитируется). Затем, спустя некоторое время, работа будет обработана обработчиком так, как показано в листинге 10.
Листинг 10. Очередь работ и создание структуры work
int init_module( void )
{
int ret;
my_wq = create_workqueue("my_queue");
if (my_wq) {
/* Queue some work (item 1) */
work = (my_work_t *)kmalloc(sizeof(my_work_t), GFP_KERNEL);
if (work) {
INIT_WORK( (struct work_struct *)work, my_wq_function );
work->x = 1;
ret = queue_work( my_wq, (struct work_struct *)work );
}
/* Queue some additional work (item 2) */
work2 = (my_work_t *)kmalloc(sizeof(my_work_t), GFP_KERNEL);
if (work2) {
INIT_WORK( (struct work_struct *)work2, my_wq_function );
work2->x = 2;
ret = queue_work( my_wq, (struct work_struct *)work2 );
}
}
return 0;
}
Заключительные этапы приведены в листинге 11. Здесь, в модуле очистки, вы принудительно завершаете конкретную очередь работ (в результате чего возникает блокировка до тех пор, пока не будет выполнена вся обработка работы work), а затем очередь работ уничтожается.
Листинг 11. Принудительное завершение очереди работ и ее уничтожение
void cleanup_module( void )
{
flush_workqueue( my_wq );
destroy_workqueue( my_wq );
return;
}
Различие между тасклетами и очередями работ
Из этого краткого введения в тасклеты и очереди работ видны две различные схемы реализации отложенных работ, которые переносят работы из верхних половин в нижние половины драйверов. В тасклетах реализуется механизм с низкой латентностью, который является простым и ясным, а очереди работ имеют более гибкое API, которое позволяет обслуживать несколько элементов работы. В каждой схеме откладывание работы выполняется из контекста прерывания, но только тасклеты выполняют запуск автоматически в стиле "работа до полного завершения", тогда как очереди работ разрешают обработчикам "засыпать". Каждый из методов пригоден для реализации переноса работ, так что при выборе метода вы должны основываться на своих собственных нуждах.
Двигаемся дальше
В настоящей статье изложены два метода откладывания работ, используемые в ядре Linux - метод, уже ушедший в историю, и современный метод (не рассматриваются таймеры, которые будут темой следующей статьи). Они, конечно, на самом деле не новы, в иной форме они существовали и прежде, но они представляют собой интересный архитектурный шаблон, который пригодится и в Linux и в других системах. Ядро Linux продолжает всесторонне развиваться - от softirq-функций и до тасклетов и очередей работ — это позволяет переносить накопленный практический опыт и на приложения, предназначенные для работы в пользовательском пространстве.