Библиотека сайта rus-linux.net
Файловые системы Linux следующего поколения: NiLFS(2) и exofs
Оригинал: "Next-generation Linux file systems: NiLFS(2) and exofs"Автор: M. Tim Jones
Дата публикации: 31 Oct 2009
Перевод: Н.Ромоданов
Дата перевода: декабрь 2009 г.
Краткое содержание:
В системе Linux продолжаются инновации в области файловых систем. В ней поддерживаются разнообразные файловые системы для различных операционных систем. В Linux также поддерживаются самые современные технологии, относящиеся к файловым системам. К числу таких, которые внедряются в Linux, относятся две новые файловые системы: журнально-структурированная файловая система NiLFS(2) и система хранения объектов exofs. Давайте изучим назначение этих двух новых файловых систем и преимущества, которые они дадут.
Анонс новых файловых систем для Linux одновременно как вдохновляет, так и пугает. Вдохновляет, поскольку файловые системы предоставляют новую территорию для интересных улучшений. Пугает, поскольку файловая система на ранних стадиях разработки является, как правило, экспериментальной, и не совсем готова для полноценного использования. Но иногда это анонсы об инвестициях в будущее Linux и, действительно, в недавнем анонсе о ядре 2.6.30-rc1 много интересного. В конце 2008 года было объявлено о Btrfs (B-Tree File System – файловая система на основе бинарных деревьев), а совсем недавно были представлены две другие уникальные файловые системы: NiLFS(2) и exofs.
Основы файловых систем
Давайте начнем с краткого введения в такие нетрадиционные файловые системы, а затем исследуем конкретные особенности систем NiLFS(2) и exofs.
Журнально-структурированные файловые системы
|
Журнально-структурированные файловые системы и твердотельные диски SSD Журнально-структурированные файловые системы являются идеальными для твердотельных дисков (дисков SSD), которые изготавливаются из флеш памяти NAND. Основная проблема с флеш памятью в том, что есть ограничения на число циклов записи и стирания данных. Поскольку журнальная структура задается для всего устройства, операции записи выполняются равномерно по всему диску и количество записей становится одинаковым по всему устройству и, следовательно, число циклов стирания уменьшается. Поэтому журнально-структурированные файловые системы работают очень хорошо на дисках SSD (последовательная запись) и также обеспечивают лучшую их сохранность. |
Журнально-структурированные файловые системы имеют богатую историю в современных компьютерных системах. Первая журнально-структурированная файловая система была предложена в 1988 году Джоном Остераутом (John Ousterhout) и Фредом Дуглисом (Fred Douglis) и позже в 1992 году была реализована в операционной системе Sprite. Как следует из названия, журнально-структурированная файловая система рассматривает файловую систему как закольцованный журнал, в котором новые данные и метаданные файловой системы записываются в начало журнала, а свободное пространство берется с конца журнала (смотрите рис.1). Это означает, что данные в журнале могут быть записаны два и большее число раз, но поскольку журнал хронологически растет вперед, самые последние данные всегда рассматриваются как активные. Наличие нескольких копий данных в журнале дает несколько интересных преимуществ, которые мы более подробно рассмотрим ниже.
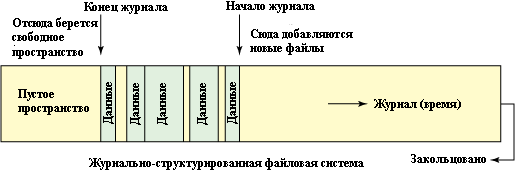
Рис.1: Общий вид журнально-структурированной файловой системы
Хотя журнально-структурированный подход является только архитектурной особенностью, он дает несколько явных преимуществ. Одно из них – восстановление системы после ее краха, которое проще при использовании журнально-структурированного подхода.
Еще одним преимуществом является более производительное использование системы хранения, на базе которой реализована файловая система. Можно напомнить, что последовательная запись на диски происходит значительно быстрее, чем прямой ввод/вывод. Поскольку запись осуществляется последовательно, накладные расходы уменьшаются, результат на диске оказывается быстрее и, следовательно, файловая система работает быстрее.
Объектный подход к системам хранения
|
Системы и стандарты хранения объектов Системы хранения объектов базируются на стандарте T-10 Object Storage Devices (OSD). В его спецификациях уточняется набор команд стандарта SCSI с тем, чтобы можно было поддерживать операции на уровне объектов. В дополнение к определениям объектных методов доступа, в этих спецификациях освещаются вопросы безопасности и управления метаданными. |
Системы хранения объектов – это уникальный путь к очень масштабируемым системам хранения, при этом подразумевается как многовариантность хранения, так и безопасность. Стандарт OSD можно реализовывать различными способами. Вы можете использовать компоненты, соответствующие стандарту OSD (такие, как драйверы и инициаторы OSD), либо высокоуровневые компоненты (целевые системы, которые создают функциональность OSD на баз традиционных драйверов). Но фундаментальное различие между блочными и объектными системами хранения в том, что в блочных системах вы, используя протокол, которые работает на уровне блоков данных, и создаете объекты из коллекций блоков, которые содержат как данные, так и метаданные. В объектных системах вы, вместо этого, взаимодействуете с объектами и связанными с ними метаданными (смотрите рис.2). Тогда устройства хранения объектов становятся одноуровневыми пространствами имен объектов, где иерархия объектов (если она нужна) создается с использованием стека системы хранения.
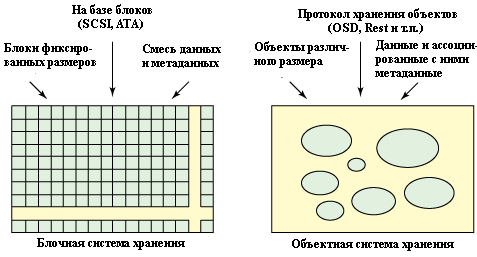
Рис.2: Сравнение систем хранения, использующих блоки, и систем хранения, использующих объекты
В настоящей статье описывается одна из реализаций файловой системы над объектной системой хранения.
Новая реализация журнально-структурированной файловой системы: NiLFS(2)
NiLFS(2) является второй итерацией журнально-структурированной файловой системой, разработанной в Японии фирмой Nippon Telegraph and Telephone (NTT). Файловая система находится в стадии активной разработки, недавно введена в основное ядро Linux (в добавок к вводу в ядро NetBSD). Первая версия NILFS (version 1) появилась в 2005 году, но в ней отсутствовал какой-либо вариант сборки мусора. В середине 2007 года была реализована вторая версия, в которой имелась сборка мусора, а также возможность создавать множественные копии данных и поддерживать с ними работу. В этом году (2009г.) файловая система NiLFS(2) была введена в основное ядро и ее можно просто подключить, инсталлировав загрузочный модуль.
Интересной особенностью NiLFS(2) является создание моментальных снимков. Поскольку файловая система NILFS является журнально-структурированной, новые данные записываются в начало журнала, а старые данные все еще продолжают существовать (до тех пор, пока не потребуется утилизировать память). Поскольку старые данные существуют, вы можете вернуться по времени назад и проверить предыдущие состояния файловой системы. Предыдущие состояния называются в NiLFS(2) контрольными точками и являются интегральной частью файловой системы. NiLFS(2) создает эти контрольные точки в тот момент, когда делаются изменения, но их можно создать и принудительно.
|
Файловые системы с моментальными снимками состояния Система NiLFS(2) – одна из множества файловых систем, в которых есть возможности делать моментальные снимки состояния системы. Другими системами, имеющими средства создания моментальных снимков, являются ZFS, LFS и Ext3cow. |
Кроме постоянного создания моментальных снимков система NiLFS(2) имеет ряд других преимуществ. Одна из наиболее важных возможностей из возможных в перспективе – быстрый рестарт. Если текущая контрольная точка оказалась неработоспособной, то для того, чтобы перейти к работоспособному варианту файловой системы, нужно переместиться назад к последней хорошей контрольной точке. Это, безусловно, лучше процесса восстановления ошибок с помощью fsck.
Проблемы с NiLFS(2)
Хотя непрерывное создание моментальных снимков отличное свойство, за это приходится платить. Как упоминалось ранее, эта система – журнально-структурированная, так что в ней операции записи, по своей природе, последовательные (минимизация операций поиска на уровне физического диска) и, следовательно, очень быстрые. Если рассматривать ее подробнее, то из-за того, что она журнально-структурированная, требуется использовать сборщик мусора, который удается старые данные и метаданные. Обычно система работает очень быстро, но когда требуется сборка мусора, производительность системы снижается.
Исследуем NiLFS(2)
|
Версия NiLFS(2) и ядро Приведенный здесь пример работы NiLFS(2) был сделан с использованием ядра Linux 2.6.27. В состав основного ядра файловая система NiLFS(2) была включена в версии 2.6.30-rc1, но для нашего случая модули и инструментальные средства файловой системы NILFS устанавливались из исходных кодов. О том, как установить NiLFS(2) в ядро смотрите в ссылках, приведенных в оригинале статьи. |
$ sudo modprobe nilfs2 $
Затем создадим файл, в котором будет находиться файловая система (область на хостовой операционной системе, в которой мы смонтируем свою собственную файловую систему для псевдоустройства loop device), и после этого с помощью команды mkfs создадим в нем файловую систему NiLFS(2) (смотрите листинг 1).
Листинг 1: Подготовка файловой системы NiLFS(2)
$ dd if=/dev/zero of=/tmp/disk.img bs=384M count=1
1+0 records in
1+0 records out
402653184 bytes (403 MB) copied, 60.7253 s, 6.6 MB/s
$ mkfs.nilfs2 /tmp/disk.img
mkfs.nilfs2 ver 2.0
Start writing file system initial data to the device
Blocksize:4096 Device:/tmp/disk.img Device Size:402653184
File system initialization succeeded !!
$
Теперь мы имеем образ диска, инициализированного в формате файловой системы NiLFS(2). Затем, используя псевдоустройство loop device, монтируем файловую систему (смотрите листинг 2). Обратите внимание, что когда файловая система будет смонтирована, будет также запущена пользовательская программа nilfs_cleanerd, реализующая сервис сборки мусора.
Листинг 2. Монтирование NiLFS(2) на псевдоустройстве loop device
$ sudo losetup /dev/loop0 /tmp/disk.img $ sudo mkdir /mnt/nilfs $ sudo mount -t nilfs2 /dev/loop0 /mnt/nilfs/ mount.nilfs2: WARNING! - The NILFS on-disk format may change at any time. mount.nilfs2: WARNING! - Do not place critical data on a NILFS filesystem. $ ls /mnt/nilfs $
Теперь добавим в файловую систему несколько файлов, а затем воспользуемся командой lscp для выдачи списка имеющихся в наличии текущих контрольных точек (смотрите листинг 3). С помощью команды mkcp создайте мгновенный снимок, а затем снова взглянете на контрольные точки. После второго выполнения команды lscp вы увидите вновь созданный мгновенный снимок (со всеми контрольными точками и мгновенными снимками, имеющими номер контрольной точки CNO).
Листинг 3: Список контрольных точек и создание мгновенного снимка
$ cd /mnt/nilfs
$ sudo touch file1.txt file2.txt
$ lscp
CNO DATE TIME MODE FLG NBLKINC ICNT
1 2009-08-21 22:29:31 cp - 11 3
2 2009-08-21 22:36:44 cp - 11 5
$ sudo mkcp -s
$ lscp
CNO DATE TIME MODE FLG NBLKINC ICNT
1 2009-08-21 22:29:31 cp - 11 3
2 2009-08-21 22:36:44 ss - 11 5
3 2009-08-21 22:39:47 cp i 7 5
$
Теперь у нас имеется мгновенный снимок и снова с помощью команды touch добавим в нашу текущую файловую систему несколько новых файлов (смотрите листинг 4).
Листинг 4: Добавляем в нашу файловую систему NiLFS(2) еще несколько файлов
$ sudo touch file3.txt file4.txt $ ls file1.txt file2.txt file3.txt file4.txt $
Теперь смонтируем наш мгновенный снимок как файловую систему, позволяющую только чтение. Сделайте это точно так, как и при предыдущем монтировании, но в этом случае нужно указать для монтирования мгновенный снимок. Сделайте это с помощью опции cp. Обратите внимание, что по результатам использования команды lscp видно, что мгновенный снимок был CNO=2. Используйте это значение CNO в команде mount для того, чтобы смонтировать файловую систему с доступом только для чтения. Если смонтировать систему на чтение и запись, то вы с помощью команды ls увидите все файлы. В случае монтирования в режиме только для чтения, вы увидите только два файла, которые были сделаны в момент создания мгновенного снимка (смотрите листинг 5).
Листинг 5: Монтирование мгновенного снимка NiLFS(2) в режиме только для чтения.
$ sudo mkdir /mnt/nilfs-ss2 $ sudo mount.nilfs2 -r /dev/loop0 /mnt/nilfs-ss2/ -o cp=2 $ ls /mnt/nilfs file1.txt file2.txt file3.txt file4.txt $ ls /mnt/nilfs-ss2/ file1.txt file2.txt $
Обратите внимание на то, что эти мгновенные снимки хранятся постоянно, поскольку они конвертированы из контрольных точек. Контрольные точки изымаются из файловой системы, когда требуется дисковое пространство, но мгновенные снимки продолжают сохраняться.
В этом примере показаны две утилиты командной строки файловой системы NiLFS(2): lscp (список контрольных точек и мгновенных снимков) и mkcp (создать контрольную точку или мгновенный снимок). Имеется также утилита, называемая chcp, предназначенная для конвертации контрольной точки в мгновенный снимок и обратно, и утилита rmcp – для аннулирования контрольной точки или мгновенного снимка.
С учетом непостоянной природы файловой системы фирма NTT рассмотрела некоторые другие весьма новаторские инструменты для использования в будущем – например, команды tls (temporal ls – временное ls), tdiff (temporal diff- временное diff) и tgrep (temporal grep – временное grep).
Расширенная файловая система хранения объектов (exofs)
Расширенная файловая система хранения объектов (exofs) является традиционной файловой системой Linux, построенной над системой хранения объектов. Exofs была первоначально разработана Эвнишаем Трегером (Avnishay Traeger) из IBM и в тот момент называлась файловой системой OSD. После этого компания Panasas, которая строит объектные системы хранения, забрала проект себе и переименовала его в exofs (поскольку истоки идут от файловой системы ext2).
Файловая система над системой хранения объектов
Концептуально система хранения объектов может рассматриваться как одноуровневое пространство имен объектов и связанных с этими объектами метаданных. Сравните это с традиционными системами хранения, использующими блоки, где некоторые блоки заняты метаданными, обеспечивающими семантическую связку. Общая схема exofs такая, как показано на рис.3. Виртуальный переключатель файловых систем VFS (Virtual File System Switch) дает доступ к exofs, а exofs взаимодействует с системой хранения объектов через локальный инициатор OSD. Инициатор OSD реализует набор SCSI команд стандарта OSD T-10.
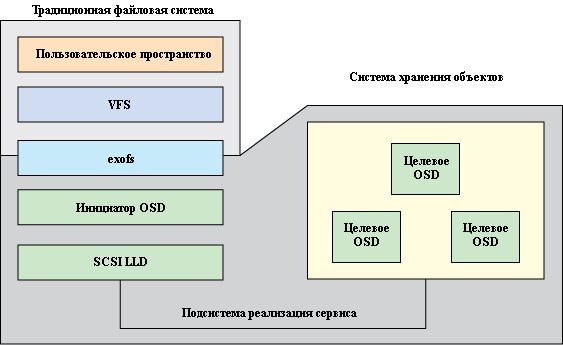
Рис.3: Общая схема экосистемы exofs/OSD
Идея, лежащая за exofs, это - реализовать традиционную файловую систему над хранилищем OSD. В этом случае будет проще переходить на объектный уровень хранения, поскольку представленная файловая система будет традиционной файловой системой.
Отображение, используемое в файловой системе
Каждый объект в OSD представлен в одноуровневом пространстве имен с помощью 64-битового идентификатора. Для того, чтобы заменить стандартный интерфейс POSIX на систему хранения объектов, требуется использовать отображение (mapping). В Exofs предлагается простая система отображения, которая как масштабируема, так и расширяемая.
Файлы внутри файловой системы представлены уникальным образом как айноды (inodes). Exofs в объектной системе отображает айноды в идентификаторы объектов (OIDs). Из этого следует, что объекты используются для представления всех элементов файловой системы. Файлы отображаются непосредственно в объекты, а директории являются просто файлами, которые ссылаются на файлы, содержащиеся в директории (как имя файла и пары inode-OID). Иллюстрация этого приведена в простой форме на рис.4. Для поддержки таких вещей, как побитовые карты размещения айнодов, существуют другие объекты.
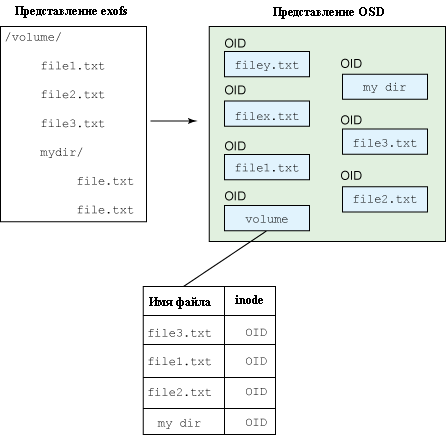
Рис.4: Обобщенная схема представлений OSD
Размер идентификаторов OID, используемых для представления объектов в объектном пространстве, равен 64 битам, поэтому поддерживается работа с огромным пространством объектов.
Почему хранение объектов?
Хранение объектов является интересной идеей и позволяет создавать значительно более масштабируемую систему. Некоторые части файловой системы можно изъять из хостовой системы и перенести на уровень реализации подсистемы хранения. Происходит перераспределение, а за счет того, что эти части можно распределить по нескольким устройствам (или системам) реализации объектных систем, вы можете распределить рабочую нагрузку, что упрощает масштабирование методов, базирующийся на объектах, и позволяет создавать существенно большие системы хранения. Вместо того, чтобы требовать от хостовой операционной системы заботиться об отображении блоков и файлов, устройство хранения само обеспечивает это отображение, позволяя хостовой системе оперировать на уровне файлов.
В системах хранения объектов можно также получать доступ к имеющимся метаданным. Это дает некоторое дополнительное преимущество, поскольку при поиске некоторые операции будут выполняться на уровне реализации объектных систем.
Идея хранения объектов недавно возродилась как механизм хранения, используемый в облачных системах. Провайдеры облачных систем хранения (которые продают хранилища как сервис) представляют свои хранилища как средство работы с объектами вместо традиционных блочных API. Эти провайдеры реализуют API для передачи объектов, управления объектами и управления метаданными.
Что дальше?
Хотя NiLFS(2) и exofs будут хорошим дополнением в составе файловых систем Linux, они еще в разработке. Недавно была представлена файловая система Btrfs (фирмы Oracle), которая предлагает для Linux альтернативу файловой системы Zettabyte File System (ZFS) фирмы Sun Microsystems. Еще одной совсем недавно разработанной системой является Ceph, которая представляет собой надежную распределенную файловую систему на основе POSIX, устойчивой к единичным отказам. Сегодня мы рассмотрели новую журнально-структурированную файловую систему и привели с файловой системой на базе хранилища объектов. Linux продолжает доказывать, что это исследовательская платформа и, одновременно, промышленная операционная система.